データを整理する:代表値と散らばり
Stage 1 — 第1章| 統計学基礎カリキュラム 推定学習時間:40〜50分 | 難易度:★☆☆☆☆
この章で学ぶこと
「平均を取ればわかる」——そう思っていませんか? 実はそれだけでは、データは半分しか語ってくれません。
この章では、データをひとことで要約する「代表値」と、データのばらつきを測る「散らばり」、この2つの視点を身につけます。2つがそろって、データの全体像がつかめます。
この章を終えると、こんなことができるようになります:
- 平均値・中央値・最頻値の使い分けができる
- 分散と標準偏差を手計算で求められる
- 「平均が同じでも、データが全然違う」理由を説明できる
- 変動係数を使って異なるデータのばらつきを比較できる
- 記述統計の問題を自信を持って解ける
1. なぜデータを「要約」するのか
500人の期末テストの点数があるとします。500個の数字を眺めても、何もわかりません。 「全体的にどのくらいの点数だったか」「ばらつきはあるか」を把握するには、うまく要約(summarize)する必要があります。
これが記述統計学(Descriptive Statistics)の仕事です。 データをあるがままに全部見せるのではなく、本質的な特徴を抜き出して伝える。
記述統計の主な仕事は大きく2つです:
| 視点 | 問いかけ | 代表的な指標 |
|---|---|---|
| 中心(代表値) | データは全体的にどのくらい? | 平均値、中央値、最頻値 |
| 散らばり | データはどれくらい広がっている? | 分散、標準偏差、変動係数 |
2. 代表値:データの「真ん中」を捉える
関連教材(青の統計学)
2.1 平均値(Mean)
最もおなじみの代表値です。
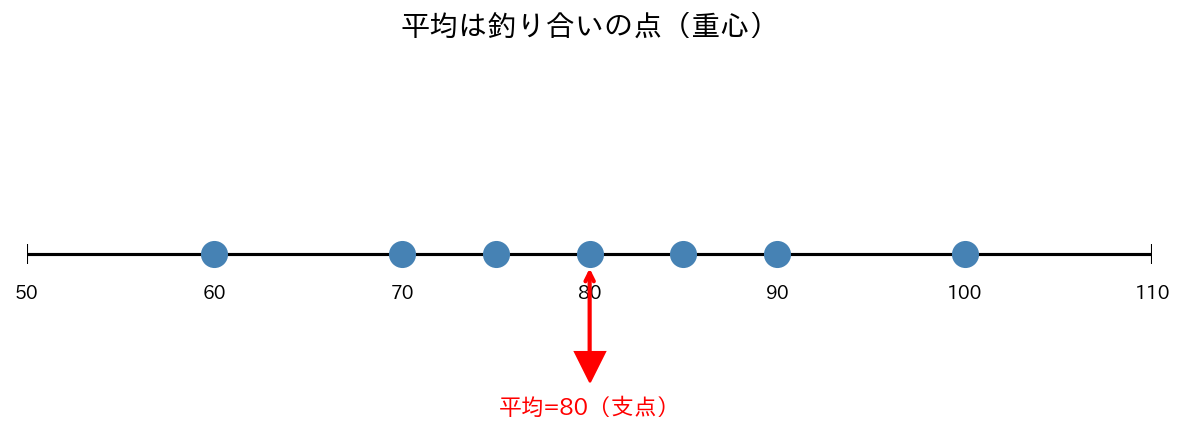
例) 5人のテスト点数:60, 70, 80, 90, 100
[図1] 数直線上の平均値
平均値の落とし穴:外れ値への弱さ
次のデータを見てください。
5人の年収(万円):200, 250, 300, 350, 5000
1人の富豪が入っただけで、平均が1220万円に跳ね上がりました。 この集団の「典型的な年収」は1220万円でしょうか? そんなことはありませんよね。
このように、平均値は外れ値(異常に大きい・小さい値)の影響を強く受けるという弱点があります。
📘 専門的な補足:加重平均(Weighted Mean)
通常の平均は全データを等しく扱いますが、データに「重要度」や「度数」が異なる場合は加重平均を使います。
\[ \bar{x}_w = \frac{w_1 x_1 + w_2 x_2 + \cdots + w_n x_n}{w_1 + w_2 + \cdots + w_n} \]例)期末試験(配点60点)と中間試験(配点40点)の成績
- 期末:75点、中間:85点
- 単純平均:(75+85)/2 = 80点
- 加重平均:(75×60 + 85×40) / (60+40) = (4500+3400)/100 = 79点
度数分布表からの平均計算には、この加重平均の考え方が使われます。
2.2 中央値(Median)
データを小さい順に並べたとき、ちょうど真ん中にくる値です。
- データ数が奇数のとき → 真ん中の1つ
- データ数が偶数のとき → 真ん中の2つの平均
奇数の例) 200, 250, 300, 350, 5000 → 中央値 = 300万円
偶数の例) 200, 250, 300, 350, 5000, 6000 → 中央値 = (300 + 350) / 2 = 325万円
先ほどの年収データでは、平均1220万円より中央値300万円のほうが「典型的な年収」として納得感がありますよね。 中央値は外れ値の影響を受けにくいため、所得・不動産価格・資産額などでよく使われます。
[図2] 平均と中央値の比較(年収データ)

📘 専門的な補足:パーセンタイルと四分位数
中央値は「50パーセンタイル」とも呼ばれます。パーセンタイルとは「データ全体の何%がその値以下か」を示す指標です。
特によく使われるのが四分位数(Quartile):
- Q1(第1四分位数):25パーセンタイル(下から25%の位置)
- Q2(第2四分位数):50パーセンタイル=中央値
- Q3(第3四分位数):75パーセンタイル(下から75%の位置)
Q3 − Q1 を四分位範囲(IQR: Interquartile Range)といい、中央50%のデータの広がりを表します。外れ値検出の基準(IQR × 1.5ルール)にも使われます。これは次章のグラフ(箱ひげ図)で視覚化します。
2.3 最頻値(Mode)
データの中で最もよく出てくる値です。
例) アンケート「好きなスポーツ」の回答: 野球(30人), サッカー(45人), バスケ(20人), テニス(15人), その他(10人)
→ 最頻値 = サッカー
最頻値は数値でなくてもよく、カテゴリーデータ(名義尺度)にも使えます。 一方、平均や中央値は数値データにしか使えません。
[図3] 3つの代表値の使い分け
データの種類 平均値 中央値 最頻値 数値データ(外れ値なし) ◎ ○ △ 数値データ(外れ値あり) △ ◎ △ カテゴリーデータ ✕ △ ◎
3. 散らばり:データはどれくらい広がっているか
関連教材(青の統計学)
代表値だけでは不十分なことを、例で確認しましょう。
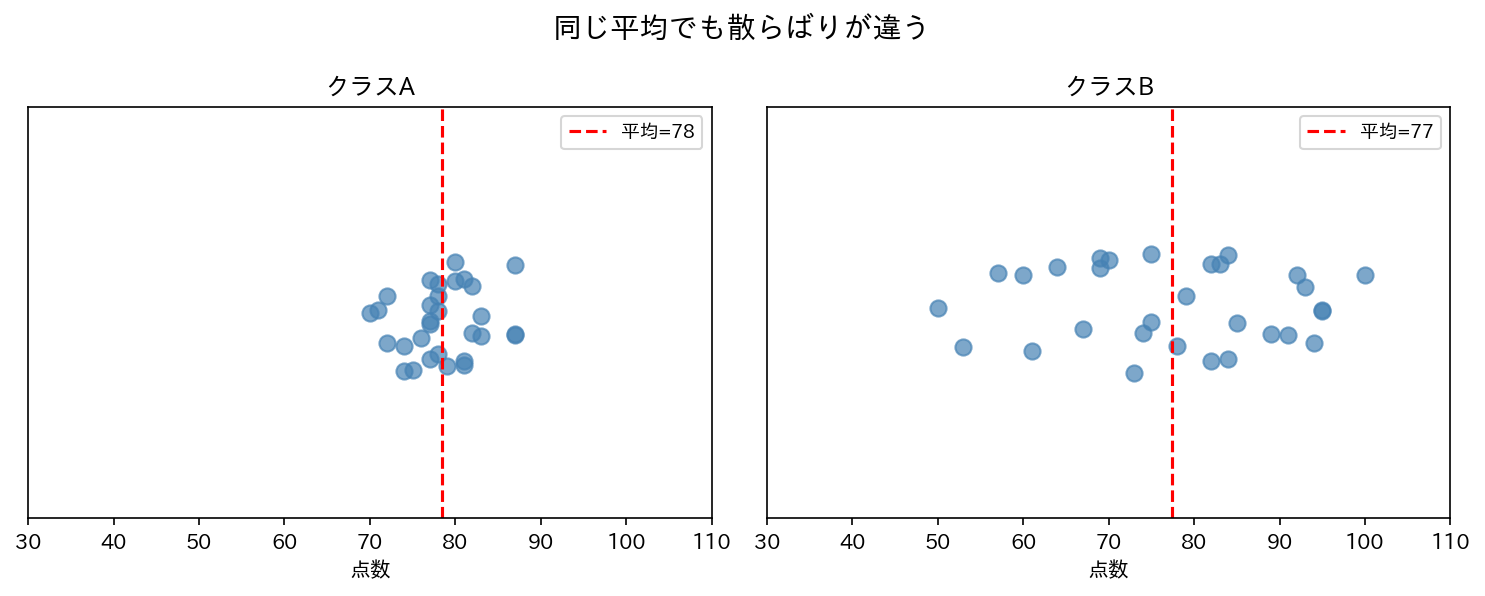
クラスAの点数: 70, 75, 80, 85, 90(平均 = 80点) クラスBの点数: 40, 60, 80, 100, 120(平均 = 80点)
どちらも平均は80点。しかしデータの様子は全く違いますね。
[図4] 平均が同じでも散らばりが違う
3.1 偏差(Deviation)
各データが平均からどれくらい離れているかを示す値。
クラスAの例(平均80):
| データ $x_i$ | 偏差 $x_i - \bar{x}$ |
|---|---|
| 70 | −10 |
| 75 | −5 |
| 80 | 0 |
| 85 | +5 |
| 90 | +10 |
| 合計 | 0 |
偏差の合計は必ずゼロになります(プラスとマイナスが打ち消し合う)。 そのため、偏差をそのまま足してもばらつきを測れません。
3.2 分散(Variance)
偏差をそのまま足せないなら、2乗して足すのが解決策です。
クラスAの分散:
📘 専門的な補足:なぜ「絶対値」ではなく「2乗」するのか?
偏差のプラスマイナスを消す方法として、絶対値をとる方法($|x_i - \bar{x}|$ の平均 → 平均絶対偏差)も考えられます。 ではなぜ2乗が選ばれたのでしょうか?
主な理由は2つです:
- 数学的な扱いやすさ:絶対値関数は $x=0$ で微分できませんが、2乗関数は至るところで微分可能です。微積分を使った最適化(最小二乗法など)と相性が抜群です。
- 大きなズレを強調できる:2乗することで、平均から大きく外れたデータに重みが乗ります。10点ズレたデータは5点ズレたデータの4倍(2²倍)の影響を持ちます。実用上、大きなズレをより重視したい場合に適しています。
ちなみに、絶対偏差を使う指標(MAE: Mean Absolute Error)は機械学習の誤差関数などでよく使われます。
📘 専門的な補足:標本分散と不偏分散
上の式では $n$ で割りましたが、統計では $n-1$ で割る不偏分散(Unbiased Variance)がよく使われます。
\[ s^2_{\text{不偏}} = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2 \]なぜ $n-1$ なのか? 手元のデータ(標本)から母集団全体のばらつきを推定する場合、$n$ で割ると系統的に「小さく見積もりすぎる」ことが数学的に証明されています。$n-1$ にすることで、その偏りが補正されます(この $n-1$ を自由度といいます)。
「母集団全体のばらつきを推定したい」場合は不偏分散($n-1$)、手元のデータのばらつきをそのまま表したい場合は標本分散($n$)を使います。文脈に応じて使い分けましょう。
3.3 標準偏差(Standard Deviation)
分散の単位は「点²(点の2乗)」になってしまい、直感的に掴みにくいです。 そこで、分散の平方根(ルート)をとった値が標準偏差です。
クラスAの標準偏差:
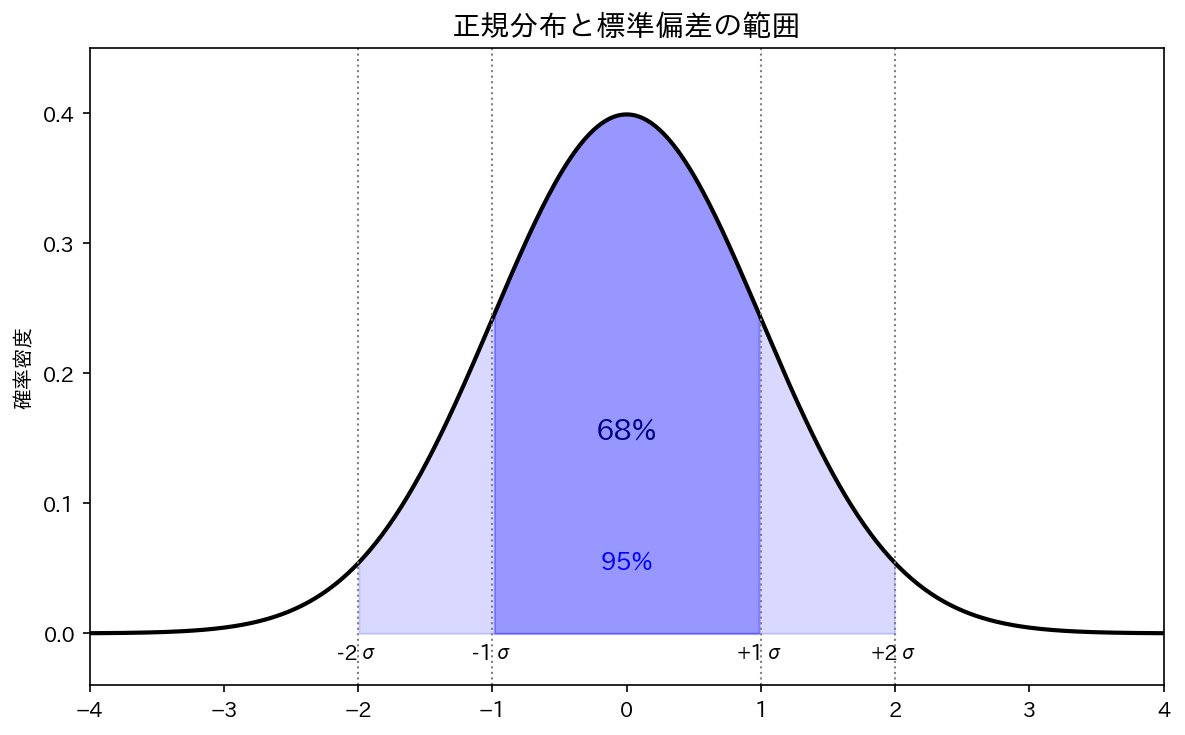
「平均80点で、標準偏差が7点」 → 多くのデータが 73〜87点の範囲に集まっているイメージです。
[図5] 標準偏差のイメージ(正規分布の場合)
3.4 変動係数(Coefficient of Variation)
「身長の標準偏差5cm」と「体重の標準偏差5kg」——どちらのばらつきが大きいでしょうか? 単位が違うデータを単純に標準偏差で比較することはできません。
そこで使うのが変動係数(CV: Coefficient of Variation)です。
標準偏差を平均で割ることで、単位に依存しない相対的なばらつきを表します。
例)
| 平均 | 標準偏差 | 変動係数 | |
|---|---|---|---|
| 身長(cm) | 170 | 8 | 4.7% |
| 体重(kg) | 65 | 10 | 15.4% |
変動係数を見ると、体重(15.4%)のほうが身長(4.7%)より相対的にばらつきが大きいことがわかります。
⚠️ 注意:変動係数は、平均値が0に近いデータや、負の値を含むデータには使用できません。
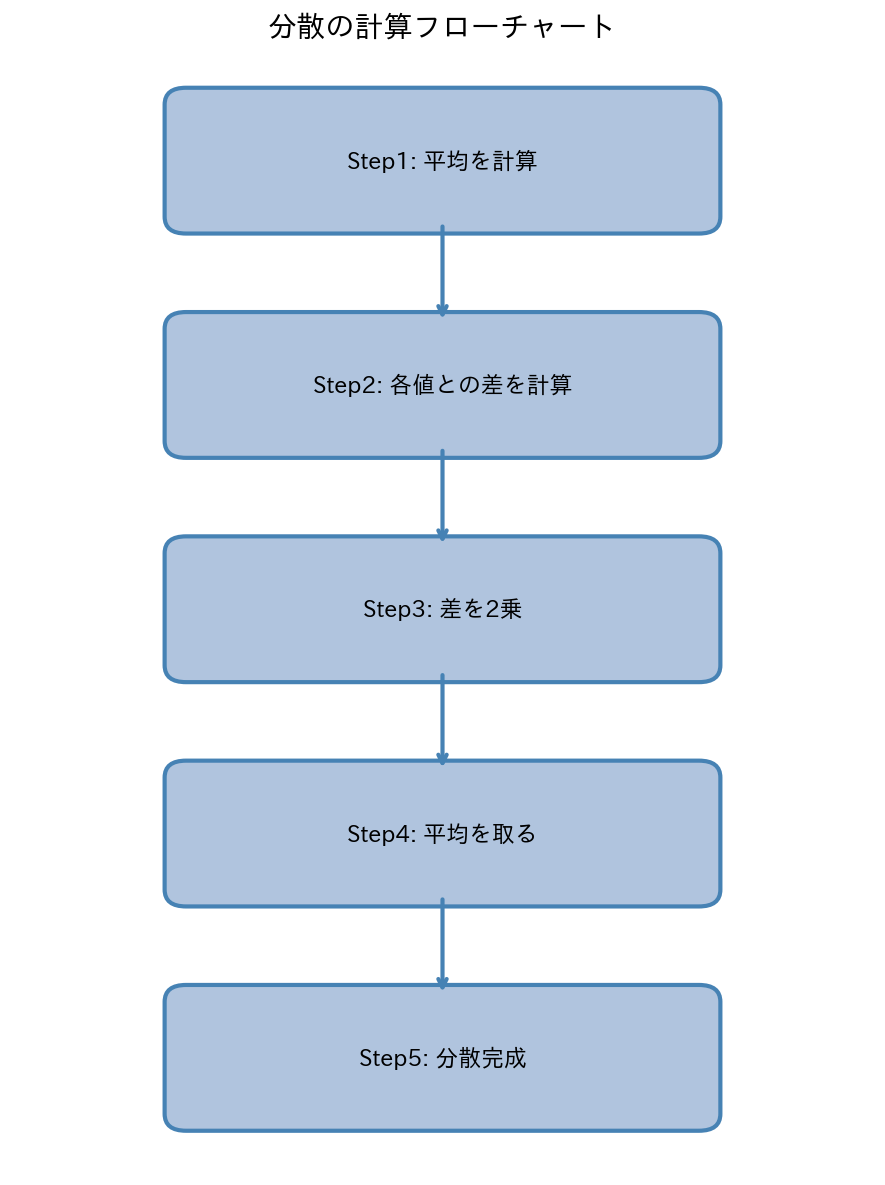
4. 計算の手順まとめ
Step 1: 平均値 x̄ を求める
Step 2: 各データの偏差 (xᵢ - x̄) を求める
Step 3: 偏差を2乗 (xᵢ - x̄)² して、全部足してnで割る → 分散 s²
Step 4: 分散の平方根をとる → 標準偏差 s
Step 5: 必要なら s ÷ x̄ × 100 → 変動係数 CV
[図6] 計算フローチャート
5. 演習問題
問題1(代表値)
次の7人の月収(万円)のデータについて、平均値・中央値を求めてください。また、どちらが「典型的な月収」をより適切に表しているか、理由とともに答えてください。
💡 解答・解説を見る
平均値:
中央値:
データはすでに昇順なので、7個の真ん中は4番目の値:
どちらが適切か:
中央値(32万円) が典型的な月収をより適切に表しています。
200万円という外れ値のせいで平均が55.4万円まで押し上げられており、7人中6人が平均を下回るという不自然な状態になっています。 中央値は外れ値の影響を受けないため、「集団の真ん中」を正しく捉えられます。
問題2(分散・標準偏差)
クラスBの5人の点数:40, 60, 80, 100, 120(平均 = 80点)について、分散と標準偏差を求めてください。クラスAの標準偏差(≈7.07点)と比較し、何がわかるか説明してください。
💡 解答・解説を見る
各偏差と偏差の2乗:
| データ $x_i$ | 偏差 $x_i - 80$ | 偏差の2乗 |
|---|---|---|
| 40 | −40 | 1600 |
| 60 | −20 | 400 |
| 80 | 0 | 0 |
| 100 | +20 | 400 |
| 120 | +40 | 1600 |
| 合計 | 0 | 4000 |
分散:
標準偏差:
クラスAとの比較:
| 平均 | 標準偏差 | |
|---|---|---|
| クラスA | 80点 | ≈ 7.07点 |
| クラスB | 80点 | ≈ 28.28点 |
平均は同じ80点ですが、クラスBの標準偏差はクラスAの約4倍。クラスBの点数は平均から大きく散らばっており、非常に「ばらついたクラス」であることがわかります。平均だけ見ると同じクラスのように見えますが、散らばりまで見ると全く異なる特性を持つことがわかります。
問題3(考察・変動係数)
2つの投資商品AとBの月次リターン(%)があります。
-商品A:2, 3, 4, 3, 3(平均 = 3%) -商品B:−10, 5, 12, 8, 0(平均 = 3%)
平均リターンは同じです。変動係数を使って2つを比較し、リスクを嫌う投資家はどちらを選ぶべきか答えてください。
💡 解答・解説を見る
商品Aの分散・標準偏差:
偏差:−1, 0, +1, 0, 0 偏差の2乗の合計:1 + 0 + 1 + 0 + 0 = 2
商品Bの分散・標準偏差:
偏差:−13, +2, +9, +5, −3 偏差の2乗:169, 4, 81, 25, 9 → 合計 = 288
結論:
| 平均リターン | 標準偏差 | 変動係数 | |
|---|---|---|---|
| 商品A | 3% | 0.63% | 21.1% |
| 商品B | 3% | 7.59% | 253% |
リスク(ばらつき)は商品Bが圧倒的に大きく、変動係数は約12倍。商品Bは−10%という大きな損失月もあり、リスクを嫌う投資家は商品Aを選ぶべきです。
このように、リターン(平均)が同じでもリスク(標準偏差・変動係数)が全く異なるケースは投資の世界では日常的です。「期待値だけで判断しない」ことが統計的思考の基本です。
まとめ
| 指標 | 意味 | 強み | 弱み |
|---|---|---|---|
| 平均値 | データの重心 | 計算しやすい・数学的に扱いやすい | 外れ値に弱い |
| 中央値 | データのど真ん中(50%点) | 外れ値に強い | 全データを使わない |
| 最頻値 | 最もよく出る値 | カテゴリにも使える | データ型が限られる |
| 分散 | 散らばりの大きさ(2乗単位) | 数学的に扱いやすい・微分可能 | 単位が直感的でない |
| 標準偏差 | 散らばりの大きさ(元の単位) | 直感的・正規分布と相性◎ | 外れ値に弱い |
| 変動係数 | 相対的なばらつき(%) | 単位が違うデータを比較できる | 平均≒0では使えない |
この章のキーメッセージ: データを見るときは、「中心はどこか」と「どれくらい散らばっているか」の2つを必ずセットで確認する習慣をつけましょう。平均だけ見てわかった気になると、大事な情報を見落とします。
次の章へ
代表値と散らばりを学んだ次のステップは、データをグラフで可視化することです。 ヒストグラム・箱ひげ図・散布図を使うと、数値だけでは見えなかったデータの「形」が浮かび上がります。
→ 次: データを視覚化する:ヒストグラムと箱ひげ図