確率変数と期待値・分散
Stage 3 — 第1章| 統計学基礎カリキュラム 推定学習時間:45〜55分 | 難易度:★★★☆☆
この章で学ぶこと
「コインを10回投げたとき、表が出る回数」——これは試行ごとに変わる値ですが、どんな値がどんな確率で出るかは事前にわかります。このような「不確実だが確率で記述できる量」を確率変数と呼びます。
確率変数を使うと、「ランダムな現象」を数学的に扱えるようになります。これが確率分布・推定・検定すべての基礎です。
この章を終えると、こんなことができるようになります:
- 確率変数と確率分布の意味を説明できる
- 離散型と連続型の違いを区別できる
- 期待値(平均)・分散・標準偏差を確率変数について計算できる
- 確率変数の線形変換・標準化ができる
- 2つの確率変数の和の期待値・分散を求められる
1. 確率変数とは
1.1 定義
確率変数(random variable)とは、試行の結果に応じて値が決まる変数です。 通常 $X$, $Y$, $Z$ などの大文字で表します。
例:
- $X$ = サイコロ1回の目の数 → $X \in \{1, 2, 3, 4, 5, 6\}$
- $Y$ = コイン10回中の表の回数 → $Y \in \{0, 1, 2, \ldots, 10\}$
- $Z$ = ある人の身長(cm) → $Z \in (0, \infty)$
「$X = 3$」「$X \leq 4$」のように事象として扱えます。
1.2 離散型と連続型
| 種類 | 定義 | 例 |
|---|---|---|
| 離散型(discrete) | とりうる値が有限または可算無限 | サイコロの目・コインの表の回数・不良品数 |
| 連続型(continuous) | とりうる値が連続した区間 | 身長・体重・待ち時間・測定値 |
2. 確率分布
関連教材(青の統計学)
確率変数がどんな値をどんな確率でとるかを記述したものが確率分布(probability distribution)です。
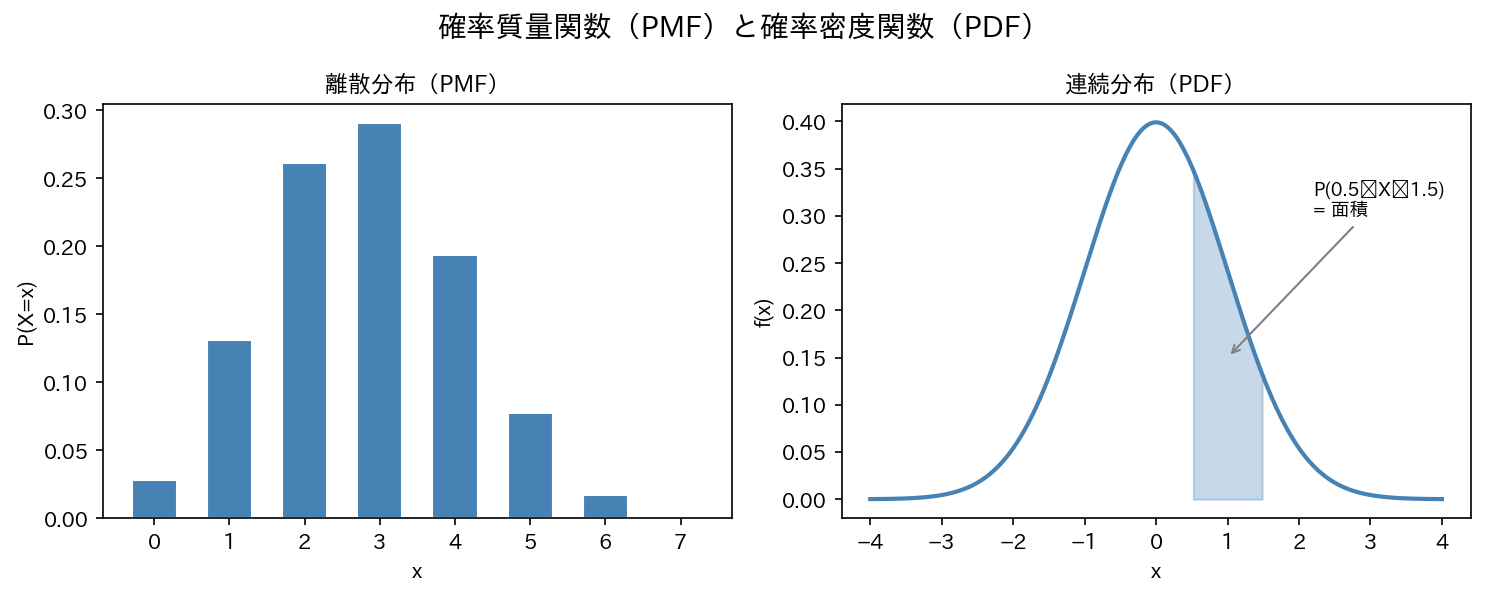
2.1 離散型:確率質量関数(PMF)
離散型確率変数 $X$ の各値 $x$ に対して確率を対応させる関数:
満たすべき条件:
- $p(x) \geq 0$(すべての $x$ で非負)
- $\sum_{\text{全ての} x} p(x) = 1$(確率の総和は1)
例) サイコロ1回の目 $X$ の PMF:
| $x$ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| $P(X=x)$ | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
2.2 連続型:確率密度関数(PDF)
連続型確率変数 $X$ では「$X$ がちょうど $x$ になる確率」はゼロです(無限に多くの点があるため)。代わりに、区間に確率を割り当てます。
$f(x)$ を確率密度関数(PDF: Probability Density Function)と呼びます。
満たすべき条件:
- $f(x) \geq 0$
- $\int_{-\infty}^{\infty} f(x) \, dx = 1$(全区間の面積が1)
注意: $f(x)$ は確率ではありません。確率は「面積」です。$f(x) > 1$ になることもあります。
[図1] PMFとPDFの比較
📘 専門的な補足:累積分布関数(CDF)
確率変数 $X$ が $x$ 以下になる確率を記述する関数:
\[ F(x) = P(X \leq x) \]離散型では $F(x) = \sum_{t \leq x} p(t)$、連続型では $F(x) = \int_{-\infty}^{x} f(t) \, dt$
CDFは単調非減少で、$F(-\infty) = 0$、$F(+\infty) = 1$ を満たします。 後の章で「正規分布表を使う」場面では、この CDF の値を読むことになります。
3. 期待値(Expected Value)
関連教材(青の統計学)
3.1 定義
確率変数 $X$ の期待値(expected value)または平均(mean)は、試行を無限に繰り返したときの値の長期的な平均です。$E[X]$ または $\mu$ と書きます。
離散型:
連続型:
例) サイコロの目の期待値:
サイコロを多数回振れば、目の平均は3.5に近づきます(大数の法則)。
3.2 期待値の性質(線形性)
この線形性は期待値の最も重要な性質です。$X$ と $Y$ が独立であるかどうかに関係なく常に成り立ちます。
4. 分散と標準偏差
4.1 分散の定義
確率変数 $X$ の分散(variance)は、$X$ が期待値からどれくらい散らばるかを表します。$V[X]$ または $\sigma^2$ と書きます。
離散型の計算:
例) サイコロの目の分散($\mu = 3.5$):
4.2 標準偏差
サイコロの目の標準偏差:$\sigma \approx \sqrt{2.917} \approx 1.708$
4.3 分散の性質
定数 $b$ を足しても分散は変わりません(全体をずらすだけでばらつきは不変)。 $a$ 倍すると分散は $a^2$ 倍になります。
独立な $X, Y$ に対して:
引き算でも分散は足される点に注意してください(ばらつきは打ち消されません)。
📘 専門的な補足:共分散と $V[X+Y]$ の一般式
$X$ と $Y$ が独立でない場合、分散の和には共分散(covariance)が加わります:
\[ V[X + Y] = V[X] + V[Y] + 2\,\text{Cov}(X, Y) \]ここで $\text{Cov}(X, Y) = E[(X - \mu_X)(Y - \mu_Y)]$
独立なら $\text{Cov}(X, Y) = 0$ となるため、$V[X+Y] = V[X] + V[Y]$ が成り立ちます。 共分散・相関係数は Stage 4(推定・検定・回帰)で詳しく扱います。
5. 標準化(Standardization)
確率変数 $X$(期待値 $\mu$、標準偏差 $\sigma$)を次の変換で標準化します:
標準化後の $Z$ は:
- $E[Z] = 0$(期待値がゼロ)
- $V[Z] = 1$(分散が1)
なぜ標準化するか?
- 単位の違うデータを比較できる(Stage 1の変動係数と同じ発想)
- 正規分布の確率計算で「標準正規分布表」が使えるようになる(Stage 3-p3で詳述)
- 機械学習での特徴量の前処理としても重要
例) 身長 $X$($\mu = 170$ cm、$\sigma = 8$ cm)のとき、175cmの人の標準化値:
「平均より0.625標準偏差分だけ高い」という意味です。
6. 演習問題
問題1(期待値・分散の計算)
確率変数 $X$ が次の確率分布に従うとします。
| $x$ | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| $P(X=x)$ | 0.1 | 0.3 | 0.4 | 0.2 |
(1)$E[X]$ を求めてください。 (2)$V[X]$ を求めてください。 (3)$Y = 3X + 2$ のとき、$E[Y]$ と $V[Y]$ を求めてください。
💡 解答・解説を見る
(1)期待値:
(2)分散:
まず $E[X^2]$ を計算します:
(3)線形変換:
問題2(独立な確率変数の和)
$X$($E[X] = 3$、$V[X] = 4$)と $Y$($E[Y] = 5$、$V[Y] = 9$)が独立な確率変数のとき、以下を求めてください。
(1)$E[X + Y]$ (2)$V[X + Y]$ (3)$E[2X - Y + 1]$ (4)$V[2X - Y + 1]$
💡 解答・解説を見る
(1)
(2)($X, Y$ は独立なので共分散ゼロ)
(3)
(4) 定数の加算は分散に影響しない。引き算でも独立なら分散は足される。
ポイント: $V[-Y] = (-1)^2 V[Y] = V[Y] = 9$。分散は常に非負です。
問題3(標準化)
ある試験の得点 $X$ が $E[X] = 60$、$\sigma = 10$ とします。
(1)得点75点の人を標準化してください。 (2)標準化値が $-1.5$ の人の元の得点を求めてください。 (3)$P(50 \leq X \leq 70)$ を、標準化した $Z$ の確率として書き直してください。
💡 解答・解説を見る
(1)75点の標準化:
平均より1.5標準偏差分高い得点です。
(2)$Z = -1.5$ の元の得点:
$Z = (X - 60) / 10 = -1.5$ を解くと:
(3)確率を $Z$ で書き直す:
この確率の具体的な値は、正規分布の章(s3-p3)で正規分布表を使って計算します。 正規分布では $P(-1 \leq Z \leq 1) \approx 68\%$ になります(Stage 1 p1 で既出)。
まとめ
| 概念 | 定義・公式 |
|---|---|
| 確率変数 | 試行結果に応じて値が決まる変数 |
| PMF(離散) | $p(x) = P(X = x)$、$\sum p(x) = 1$ |
| PDF(連続) | $P(a \leq X \leq b) = \int_a^b f(x)dx$、$\int f(x)dx = 1$ |
| 期待値 | $E[X] = \sum x \cdot p(x)$(離散) |
| 期待値の線形性 | $E[aX+b] = aE[X]+b$、$E[X+Y] = E[X]+E[Y]$ |
| 分散 | $V[X] = E[X^2] - (E[X])^2$ |
| 分散の性質 | $V[aX+b] = a^2 V[X]$、独立なら $V[X+Y] = V[X]+V[Y]$ |
| 標準化 | $Z = (X - \mu)/\sigma$、$E[Z]=0$、$V[Z]=1$ |
この章のキーメッセージ: 確率変数は「ランダムな量を数学で扱う道具」です。 期待値と分散は確率分布の「中心」と「広がり」を1つの数値で要約し、 標準化はあらゆる分布を共通のスケールで比較可能にします。
次の章へ
確率変数の言語を手に入れました。次は最もよく使われる離散型の分布——二項分布とポアソン分布——を具体的に学びます。
→ 次: 離散型確率分布:二項分布とポアソン分布