第3章:重回帰分析
Stage 5:回帰・分散分析・応用
この章で学ぶこと
単回帰は説明変数が1つでしたが、現実には複数の要因が結果に影響します。「売上は広告費だけで決まるのか?気温や曜日も関係するのでは?」——複数の説明変数を同時に扱うのが重回帰分析です。
この章では、重回帰モデルの構造・調整済み $R^2$・多重共線性・ダミー変数・モデル選択の考え方を学びます。
1. 重回帰モデル
モデルの形
- $x_1, x_2, \ldots, x_k$:$k$ 個の説明変数
- $\beta_j$:偏回帰係数(partial regression coefficient)
- $\varepsilon \sim N(0, \sigma^2)$:誤差項
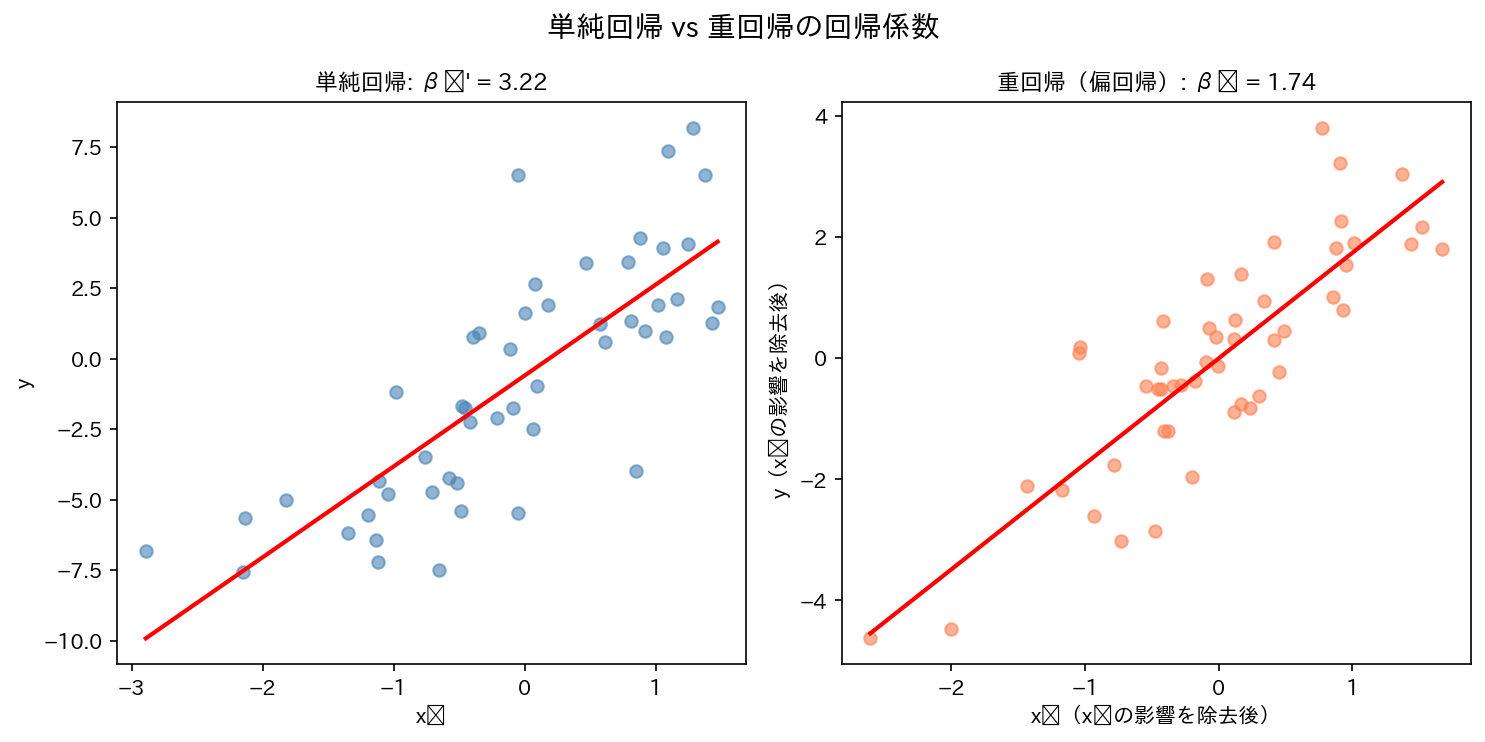
偏回帰係数の解釈
単回帰の回帰係数と重回帰の偏回帰係数は意味が異なります。
偏回帰係数 $\hat{\beta}_j$:他の説明変数をすべて固定したまま、$x_j$ だけが1単位増えたときの $y$ の変化量。
例:売上($y$)を広告費($x_1$)と気温($x_2$)で回帰した場合
- $\hat{\beta}_1 = 5$:気温を一定に保ったとき、広告費が1万円増えると売上は平均5万円増える
- $\hat{\beta}_2 = 2$:広告費を一定に保ったとき、気温が1度上がると売上は平均2万円増える
この「他を固定したとき」という条件が、単回帰の回帰係数と重回帰の偏回帰係数が異なる値になる理由です。
交絡の制御
重回帰の重要な用途の一つが交絡変数の統計的制御です。
例:「収入($x_1$)と健康($y$)の関係を調べたい。しかし年齢($x_2$)が両方に影響している」
重回帰で年齢を共変量として投入すれば、年齢の影響を除いたうえで収入と健康の関係を推定できます。これを「年齢を調整した」と言います。
2. 調整済み $R^2$
なぜ調整が必要か
通常の $R^2$ は、説明変数を増やすと必ず増加します。意味のない変数を追加しても $R^2$ は下がりません。
これは、変数を増やせば残差 RSS が(悪くなることなく)小さくなるためです。
調整済み $R^2$(Adjusted $R^2$)
自由度を使って変数の数に対するペナルティを課した指標です。
- $k$:説明変数の数
- $n-k-1$:残差の自由度
特徴:
- 変数を増やしても、その変数が十分な説明力を持たなければ $\bar{R}^2$ は下がることがある
- $\bar{R}^2 < R^2$ が常に成立(等号は $k=0$ のとき)
- $\bar{R}^2$ が負の値になることもある(モデルが非常に悪い場合)
モデル比較への利用
| モデル | 説明変数 | $R^2$ | $\bar{R}^2$ |
|---|---|---|---|
| A | $x_1$ | 0.72 | 0.71 |
| B | $x_1, x_2$ | 0.78 | 0.76 |
| C | $x_1, x_2, x_3$(無意味な変数) | 0.78 | 0.75 |
モデルCは $R^2$ がBと同じでも $\bar{R}^2$ は下がっています。$x_3$ の追加がモデルを改善していないことが分かります。
3. 多重共線性(Multicollinearity)
関連教材(青の統計学)
問題の概要
説明変数どうしに強い相関がある状態を多重共線性と言います。
例:住宅価格の予測に「延床面積($x_1$)」と「部屋数($x_2$)」を同時に投入した場合、$x_1$ と $x_2$ は高い相関を持ちます。
多重共線性があると:
- 偏回帰係数の推定値が不安定になる(標準誤差が大きくなる)
- 係数の符号が直感と逆になることがある
- t 検定の p 値が大きくなり、本来有意な変数が有意でなくなる
VIF(分散膨張係数)
多重共線性の程度を測る指標がVIF(Variance Inflation Factor)です。
$R_j^2$ は、$x_j$ を他の全説明変数で回帰したときの決定係数です。$x_j$ が他の変数と強く関連するほど $R_j^2$ が高くなり、VIF が大きくなります。
| VIF の値 | 目安 |
|---|---|
| $\text{VIF} < 5$ | 問題なし |
| $5 \leq \text{VIF} < 10$ | 注意が必要 |
| $\text{VIF} \geq 10$ | 重篤な多重共線性の可能性 |
対処法
- 相関の高い変数のいずれかを除外する
- 主成分分析(PCA)で変数を合成する
- リッジ回帰などの正則化手法を使う
4. ダミー変数
カテゴリカル変数の扱い
「性別」「地域」「業種」などのカテゴリカル変数は、そのままでは回帰に投入できません。ダミー変数(dummy variable)に変換します。
カテゴリ $k$ 種類の変数には $k-1$ 個のダミー変数を作ります(1個省くのは基準カテゴリにするため)。
例:「地域」が東京・大阪・名古屋の3カテゴリ → ダミー変数は2つ
| 地域 | $D_{\text{大阪}}$ | $D_{\text{名古屋}}$ |
|---|---|---|
| 東京(基準) | 0 | 0 |
| 大阪 | 1 | 0 |
| 名古屋 | 0 | 1 |
回帰式:$\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 D_{\text{大阪}} + \hat{\beta}_2 D_{\text{名古屋}} + \cdots$
解釈:
- $\hat{\beta}_0$:東京(基準)での $y$ の推定平均
- $\hat{\beta}_1$:大阪と東京の差(他の変数を固定したとき)
なぜ k 個全て入れてはいけないか
3つ全てのダミーを投入すると $D_{\text{東京}} + D_{\text{大阪}} + D_{\text{名古屋}} = 1$ となり、定数項と完全な線形従属になります(ダミー変数トラップ)。行列の逆行列が計算できなくなるため、必ず1つ省きます。
5. モデル選択
関連教材(青の統計学)
AIC と BIC
変数の数が異なるモデルを比較するとき、単純な $R^2$ では不十分です。モデルの当てはまりの良さと パラメータ数のペナルティ を両立した指標を使います。
AIC(赤池情報量規準):
BIC(ベイズ情報量規準):
- $\ln L$:最大対数尤度(当てはまりの良さ)
- $k$:パラメータ数(変数が増えるとペナルティが増える)
- BIC は AIC より大きなペナルティを課すため、より少ない変数のモデルを選ぶ傾向がある
選択基準:AIC・BIC ともに小さいほど良いモデルです。
変数選択の方法
| 方法 | 概要 |
|---|---|
| 変数増加法(Forward) | 変数を1つずつ追加。AIC 改善が止まったら終了 |
| 変数減少法(Backward) | 全変数から1つずつ除外。AIC 悪化が出たら終了 |
| 変数増減法(Stepwise) | 追加と除外を繰り返す |
注意:変数選択はデータ探索的な手法であり、因果解釈には適しません。理論的背景のある変数を事前に選ぶことが望ましいです。
演習問題
問題1
ある分析で、住宅の家賃(万円)を床面積($x_1$、$\mathrm{m^2}$)と最寄り駅からの距離($x_2$、分)で重回帰した結果:
(1) 偏回帰係数 $\hat{\beta}_1 = 0.25$ を正しく解釈してください。 (2) 床面積60m²、駅から10分の物件の家賃を予測してください。
解答を見る
(1) $\hat{\beta}_1 = 0.25$ の解釈
最寄り駅からの距離を一定に保ったとき、床面積が1m²増えると家賃は平均0.25万円(約2,500円)高くなる、と推定されます。
「他の変数を固定したとき」という条件が偏回帰係数解釈の核心です。
(2) 予測
この物件の家賃は月額15.0万円と予測されます。
問題2
説明変数3つのモデルで $R^2 = 0.82$、$n = 50$ だった。調整済み $R^2$ を計算してください。
解答を見る
$R^2 = 1 - \text{RSS}/\text{TSS} = 0.82$ より $\text{RSS}/\text{TSS} = 0.18$
$R^2 = 0.82$ に対して $\bar{R}^2 \approx 0.808$ と少し小さくなります。変数3つのペナルティが反映されています。
問題3
重回帰分析を行ったところ、説明変数 $x_1$ の VIF = 12 だった。
(1) VIF = 12 が示す問題を説明してください。 (2) この問題への対処法を2つ挙げてください。
解答を見る
(1) VIF = 12 の意味
VIF が10以上は重篤な多重共線性の目安です。VIF = 12 は、$x_1$ が他の説明変数と強く相関していることを示します。
具体的には、$x_1$ を他の説明変数で回帰したときの決定係数が:
約92%の説明力があり、$x_1$ が他の変数でほぼ予測できてしまっています。
この状態では $\hat{\beta}_1$ の標準誤差が膨らみ、t 検定が有意になりにくくなります。係数の符号が逆転することもあります。
(2) 対処法(2つ)
① 変数の除外:$x_1$ と強く相関している変数を特定し、いずれか一方を除外します。理論的に重要な変数を残します。
② 主成分分析(PCA)による次元削減:相関の高い複数の変数を主成分にまとめ、独立性の高い合成変数に変換してから回帰に投入します。解釈がやや難しくなりますが、多重共線性を解消できます。
まとめ
| 概念 | 内容 |
|---|---|
| 偏回帰係数 $\hat{\beta}_j$ | 他の変数を固定したときの $x_j$ の効果 |
| 調整済み $R^2$ | 変数数のペナルティあり。モデル比較に使う |
| 多重共線性 | 説明変数間の高い相関。VIF で検出 |
| ダミー変数 | $k$ カテゴリ → $k-1$ 個のダミー変数 |
| AIC / BIC | 当てはまりとパラメータ数のトレードオフで小さいほど良い |
次の章では、分類問題に対応するロジスティック回帰とオッズ比を学びます。