第4章:ロジスティック回帰とオッズ比
Stage 5:回帰・分散分析・応用
この章で学ぶこと
「このメールはスパムか」「この患者は疾患ありか」——目的変数が 0/1 の二値変数であるとき、線形回帰は適切ではありません。
こうした分類問題に対応するのがロジスティック回帰です。また、係数の解釈に使うオッズ比は医学・疫学・社会科学で広く使われる概念です。
1. なぜ線形回帰では不十分か
0/1 の目的変数への線形回帰の問題
$y \in \{0, 1\}$ を線形回帰で予測しようとすると:
この予測値は「$y = 1$ である確率」と解釈したくなりますが、以下の問題が生じます。
- $x$ が大きいと $\hat{y} > 1$ になる
- $x$ が小さいと $\hat{y} < 0$ になる
確率は $[0, 1]$ の範囲に収まらなければなりません。線形モデルではこれを保証できません。
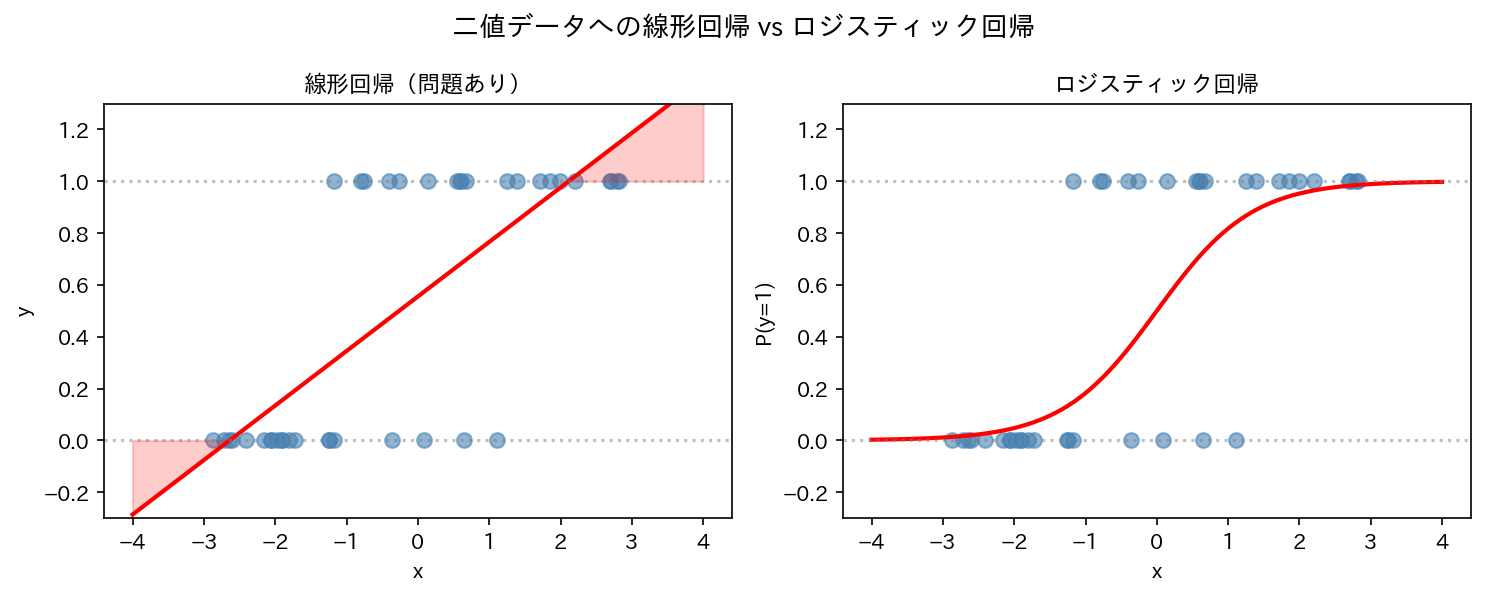
解決策:確率を S 字型の関数で表す
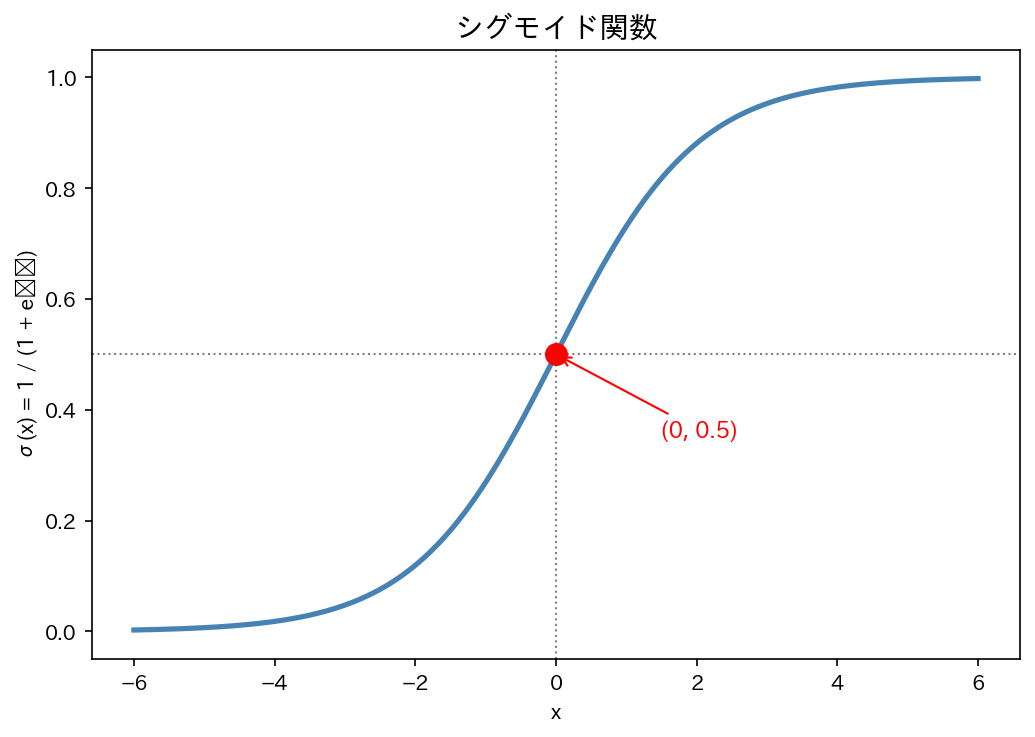
0 から 1 の範囲に自然に収まる関数が必要です。それがシグモイド関数(ロジスティック関数)です。
2. シグモイド関数とロジット変換
関連教材(青の統計学)
シグモイド関数
- $z \to +\infty$ のとき $\sigma(z) \to 1$
- $z \to -\infty$ のとき $\sigma(z) \to 0$
- $z = 0$ のとき $\sigma(z) = 0.5$
- 常に $(0, 1)$ の範囲に収まる
オッズ(odds)
確率 $p$ のオッズとは「成功する確率と失敗する確率の比」です。
例:確率 $p = 0.8$ なら $\text{odds} = 0.8/0.2 = 4$(4対1で起きやすい)
| 確率 $p$ | オッズ |
|---|---|
| 0.1 | 0.111 |
| 0.5 | 1.000 |
| 0.8 | 4.000 |
| 0.9 | 9.000 |
ロジット変換(対数オッズ)
オッズの対数をとったものがロジット(logit)です。
- $p = 0.5$ のとき $\text{logit} = 0$
- $p \to 1$ のとき $\text{logit} \to +\infty$
- $p \to 0$ のとき $\text{logit} \to -\infty$
ロジットは $(-\infty, +\infty)$ の範囲をとります。これを説明変数の線形結合でモデル化するのがロジスティック回帰です。
3. ロジスティック回帰モデル
モデルの形
あるいは確率 $p$ を直接書くと:
推定方法:最尤推定(MLE)
ロジスティック回帰の係数は最小二乗法ではなく最尤推定(Maximum Likelihood Estimation)で推定します。
観測データが得られる確率(尤度)を最大化するパラメータを求めます。閉形式の解がないため、数値最適化(ニュートン法など)を使います。
係数の有意性検定
Wald 検定:
(標本が大きいとき)
または尤度比検定(LRT):
4. オッズ比
定義
ロジスティック回帰の係数 $\hat{\beta}_j$ を指数変換した値がオッズ比(Odds Ratio, OR)です。
解釈
$x_j$ が1単位増えたとき、他の変数を固定した状態で、$y = 1$ のオッズが何倍になるか。
| $\text{OR}_j$ の値 | 解釈 |
|---|---|
| $\text{OR} > 1$ | $x_j$ が増えるとオッズが上がる($y = 1$ になりやすい) |
| $\text{OR} = 1$ | $x_j$ は $y$ に関連しない($\beta_j = 0$ に対応) |
| $\text{OR} < 1$ | $x_j$ が増えるとオッズが下がる($y = 1$ になりにくい) |
例:喫煙($x_1$:1=喫煙者、0=非喫煙者)と肺がん発症($y$)のロジスティック回帰で $\hat{\beta}_1 = 1.6$ なら:
「喫煙者は非喫煙者に比べて、肺がん発症のオッズが約5倍」と解釈します。
オッズ比の信頼区間
信頼区間が1 を含まない→ 統計的に有意な関連がある。
確率への変換
オッズ比は確率の比ではありません。具体的な確率が欲しいときは:
注意:「オッズ比 ≈ 相対危険度(リスク比)」が成り立つのは、$y = 1$ の発生率が低いとき($p < 0.1$ 程度)のみです。発生率が高い場合はオッズ比が相対危険度を過大評価します。
5. モデルの評価
関連教材(青の統計学)
混同行列(Confusion Matrix)
ロジスティック回帰の予測(通常 $p > 0.5$ を 1、$p \leq 0.5$ を 0 と判定)を実際の値と比較します。
| 予測:Positive | 予測:Negative | |
|---|---|---|
| 実際:Positive | TP(真陽性) | FN(偽陰性) |
| 実際:Negative | FP(偽陽性) | TN(真陰性) |
主な評価指標
- 感度(Recall):実際に陽性のうち、正しく陽性と予測できた割合(「見逃し」の少なさ)
- 特異度:実際に陰性のうち、正しく陰性と予測できた割合(「誤検知」の少なさ)
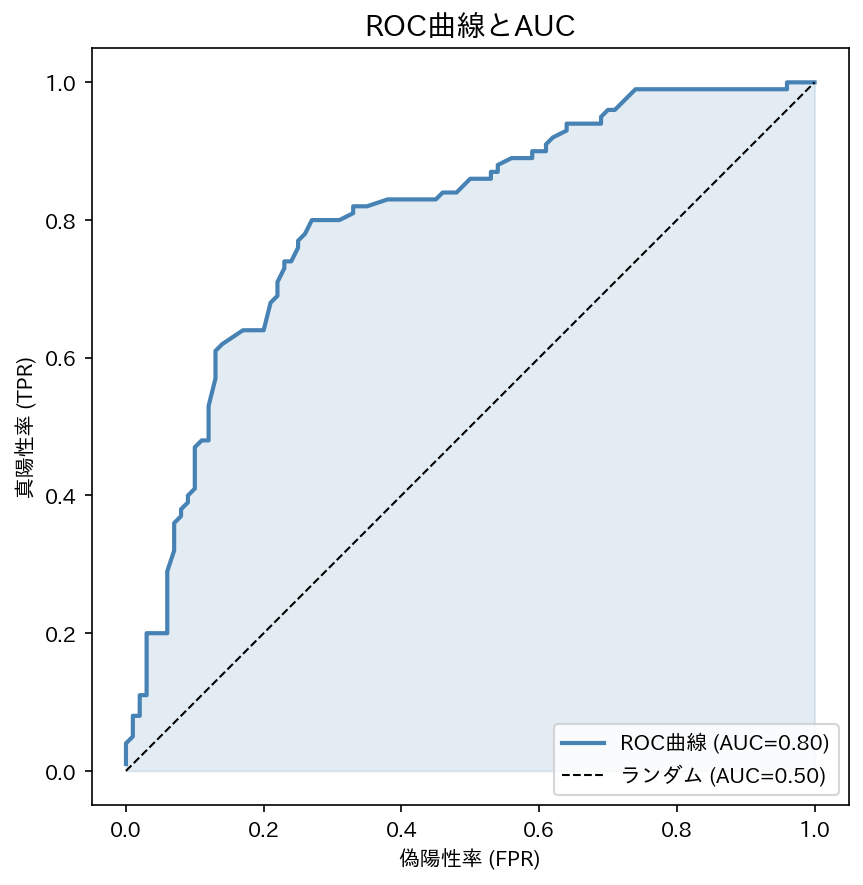
ROC 曲線と AUC
判定閾値(0.5)を動かすと感度と特異度のバランスが変わります。全ての閾値に対して「感度 vs (1 - 特異度)」をプロットしたのが ROC 曲線です。
AUC(Area Under the Curve):ROC 曲線の下の面積。
| AUC の値 | モデルの性能 |
|---|---|
| 1.0 | 完全予測 |
| 0.9〜1.0 | 非常に優秀 |
| 0.7〜0.9 | 良好 |
| 0.5 | ランダムと同等 |
演習問題
問題1
ロジスティック回帰モデルで $\hat{\beta}_0 = -3.0$、$\hat{\beta}_1 = 0.5$ が得られた。$x_1 = 4$ のとき、$y = 1$ となる確率を求めてください。
解答を見る
線形予測子の計算:
シグモイド関数に代入:
$x_1 = 4$ のとき、$y = 1$ となる確率は約26.9%です。
通常の閾値 $p > 0.5$ では、この予測は $y = 0$(陰性)と判定されます。
問題2
ある疾患の発症($y=1$)を予測するロジスティック回帰で、年齢($x_1$)の係数 $\hat{\beta}_1 = 0.08$、95%信頼区間は $(0.05, 0.11)$ だった。
(1) オッズ比とその95%信頼区間を求めてください。 (2) オッズ比の解釈を述べてください。
解答を見る
(1) オッズ比と信頼区間
信頼区間:
(2) 解釈
他の変数を固定したとき、年齢が1歳上がるごとに、この疾患を発症するオッズが約1.083倍(約8.3%増加)します。
95%信頼区間は $(1.051, 1.116)$ で、1を含まないため、この関連は有意です。年齢は疾患発症の有意な予測因子です。
問題3
がん検診のモデルを評価したところ、次の混同行列が得られた。感度・特異度・正確度を計算してください。
| 予測:陽性 | 予測:陰性 | |
|---|---|---|
| 実際:陽性 | 80 | 20 |
| 実際:陰性 | 15 | 185 |
解答を見る
$TP = 80$、$FN = 20$、$FP = 15$、$TN = 185$、合計 $n = 300$
感度(Recall):
実際の陽性のうち80%を正しく検出できています。20%を見逃しています。
特異度:
実際の陰性のうち92.5%を正しく陰性と判定できています。
正確度(Accuracy):
全体の88.3%を正しく分類できています。ただし、クラスの不均衡がある場合は正確度だけでは不十分な評価になることがあります。
まとめ
| 概念 | 内容 |
|---|---|
| シグモイド関数 | $\sigma(z) = 1/(1+e^{-z})$。出力を $(0,1)$ に変換 |
| ロジット | $\ln(p/(1-p))$。確率を $(-\infty, +\infty)$ に変換 |
| ロジスティック回帰 | ロジットを線形モデルで表現。MLE で推定 |
| オッズ比 OR | $e^{\hat{\beta}_j}$。$x_j$ が1単位増えたときのオッズの倍率 |
| 混同行列 | 予測と実際の対比。感度・特異度・精度を算出 |
| AUC | ROC 曲線の面積。モデル全体の識別能力 |
次の章では、最尤推定(MLE)の考え方をより体系的に学びます。