データを視覚化する:ヒストグラムと箱ひげ図
Stage 1 — 第2章| 統計学基礎カリキュラム 推定学習時間:40〜50分 | 難易度:★☆☆☆☆
この章で学ぶこと
前章では、データを数値で要約する「代表値」と「散らばり」を学びました。 しかし数値だけでは見えてこないものがあります——データの「形」です。
この章では、データを視覚化してその形を読み取る技術を身につけます。
この章を終えると、こんなことができるようになります:
- 度数分布表を作り、データを区間に整理できる
- ヒストグラムを読んで、分布の形(対称・右寄り・左寄り)を判断できる
- 箱ひげ図から中央値・四分位数・外れ値を読み取れる
- 「ヒストグラムを使うべき場面」と「箱ひげ図を使うべき場面」を使い分けられる
- グラフ読み取り問題を自信を持って解ける
1. なぜグラフで見るのか
次の2つのデータを見てください。
データX: 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 7 データY: 1, 1, 2, 4, 4, 4, 4, 4, 4, 4, 6, 8, 8, 9, 9
どちらも平均 ≈ 4.3、標準偏差 ≈ 1.7 ですが、性質は全く違います。 数値だけでは気づけない違いを、グラフは一瞬で見せてくれます。
[図1] データXとYの比較
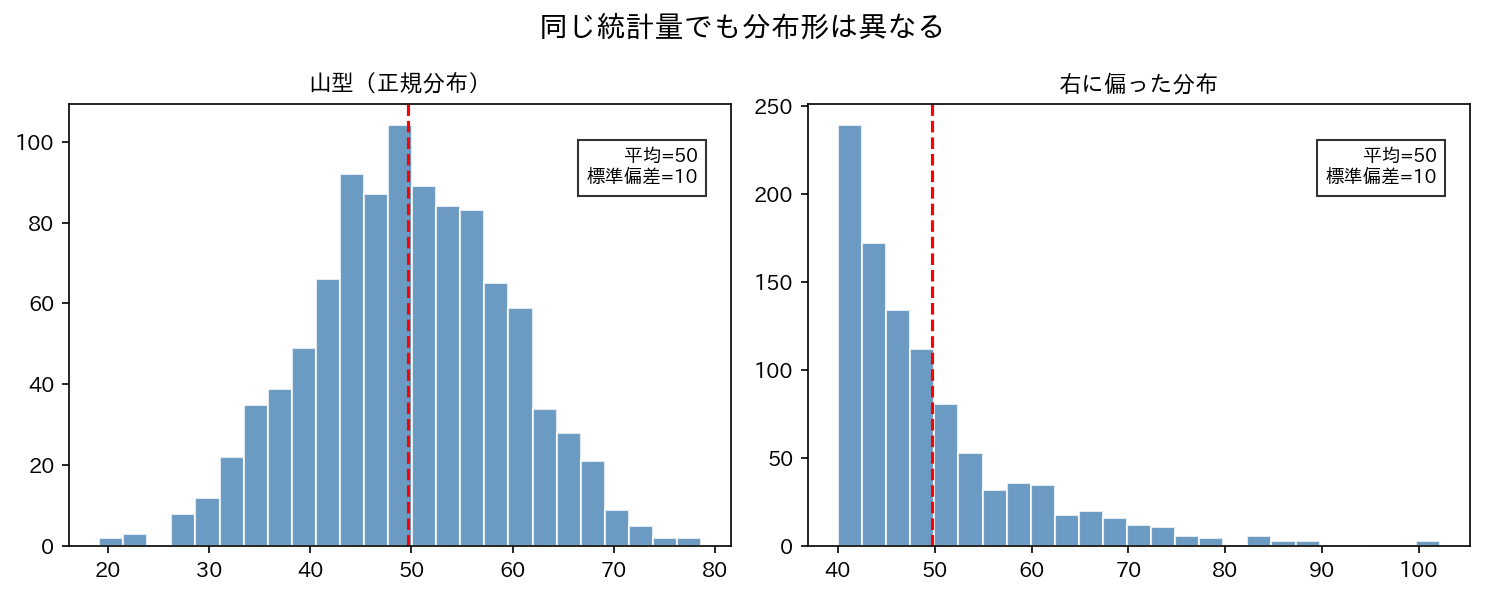
2. 度数分布表:グラフの前に数値を整理する
ヒストグラムを作る前に、まずデータを区間に分けて集計する必要があります。これが度数分布表です。
例) 30人のテスト点数(0〜100点)を整理する
| 階級(点) | 度数(人) | 相対度数 | 累積相対度数 |
|---|---|---|---|
| 40〜50未満 | 3 | 0.10 | 0.10 |
| 50〜60未満 | 5 | 0.17 | 0.27 |
| 60〜70未満 | 9 | 0.30 | 0.57 |
| 70〜80未満 | 8 | 0.27 | 0.83 |
| 80〜90未満 | 4 | 0.13 | 0.97 |
| 90〜100以下 | 1 | 0.03 | 1.00 |
| 合計 | 30 | 1.00 | — |
用語の整理:
- 階級(class):データを分けた区間。「60〜70未満」のような範囲
- 階級幅:各区間の幅。上の例では10点
- 度数(frequency):その階級に入るデータの個数
- 相対度数:度数 ÷ 全体の個数。全て足すと1になる
- 累積相対度数:その階級までの相対度数を全て足した値(0〜1の間)
📘 専門的な補足:階級幅の選び方
階級幅を変えると、グラフの見え方が大きく変わります。
- 幅が広すぎる:細かい特徴が消えて、粗くなる
- 幅が狭すぎる:凸凹が多くなり、傾向が見えにくい
よく使われる目安として、スタージェスの公式があります:
\[ k = 1 + \log_2 n \approx 1 + 3.32 \log_{10} n \]ここで $k$ は階級数、$n$ はデータの個数。$n = 30$ なら $k \approx 6$ 程度が目安です。 ただし、これはあくまで参考値。データの性質や伝えたいことに応じて調整します。
3. ヒストグラム:分布の「形」を見る
関連教材(青の統計学)
度数分布表をグラフにしたものがヒストグラム(histogram)です。 横軸に階級、縦軸に度数(または相対度数)をとり、棒を並べて描きます。
棒グラフとの決定的な違い:棒同士をくっつける
棒グラフはカテゴリ間に隙間があります(「野球・サッカー・バスケ」は別物だから)。 ヒストグラムは連続したデータなので、棒をくっつけて描きます。
[図2] 30人のテスト点数のヒストグラム
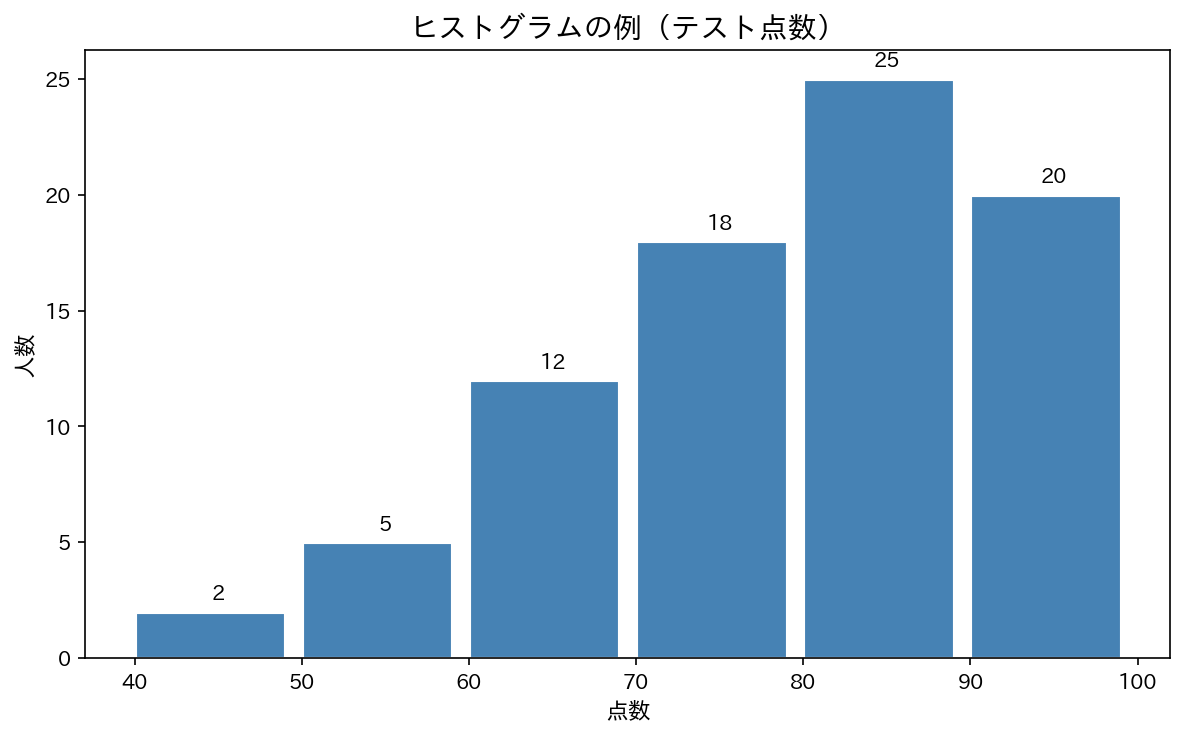
3.1 分布の形を読む
ヒストグラムを見たとき、最初に確認すべきは「形」です。
[図3] 代表的な分布の形
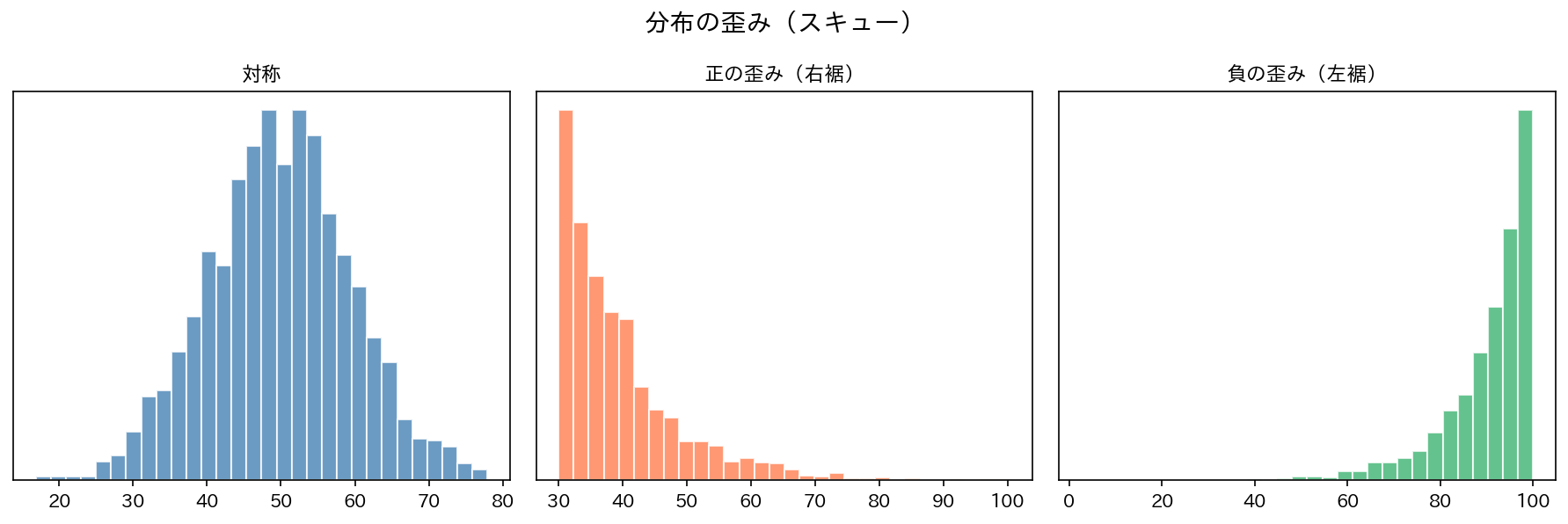
読み取りのポイント:
| 特徴 | 何を示すか | 代表値への影響 |
|---|---|---|
| ピークが1つ・左右対称 | 正規分布に近い | 平均 ≈ 中央値 ≈ 最頻値 |
| 右に尾を引く(正の歪み) | 高い値の外れ値あり | 平均 > 中央値 |
| 左に尾を引く(負の歪み) | 低い値の外れ値あり | 平均 < 中央値 |
| ピークが2つ(双峰型) | 2つの集団が混在 | 平均が「中間」になり、実態を反映しない |
📘 専門的な補足:歪度(Skewness)と尖度(Kurtosis)
分布の形を数値で表す指標もあります。
歪度(skewness):分布の左右の非対称さを測る
- 歪度 > 0:右に尾を引く(正の歪み)
- 歪度 = 0:左右対称
- 歪度 < 0:左に尾を引く(負の歪み)
尖度(kurtosis):分布の「とがり」を測る
- 正規分布の尖度を0(または3)として相対的に定義
- 尖度が大きい:ピークが鋭く、裾が重い
- 尖度が小さい:ピークが平らな分布
実務・試験ともに「歪みの方向を視覚的に読み取る」スキルがよく問われます。歪度・尖度の数値計算は後の章で扱います。
4. 箱ひげ図:5つの数値でデータを要約する
関連教材(青の統計学)
箱ひげ図(box plot / box-and-whisker plot)は、5つの数値でデータの分布を表現します。
5数要約(Five-number summary):
| 数値 | 意味 |
|---|---|
| 最小値 | データの最小値(外れ値を除く場合あり) |
| Q1(第1四分位数) | 下から25%の位置 |
| Q2(中央値) | 下から50%の位置 |
| Q3(第3四分位数) | 下から75%の位置 |
| 最大値 | データの最大値(外れ値を除く場合あり) |
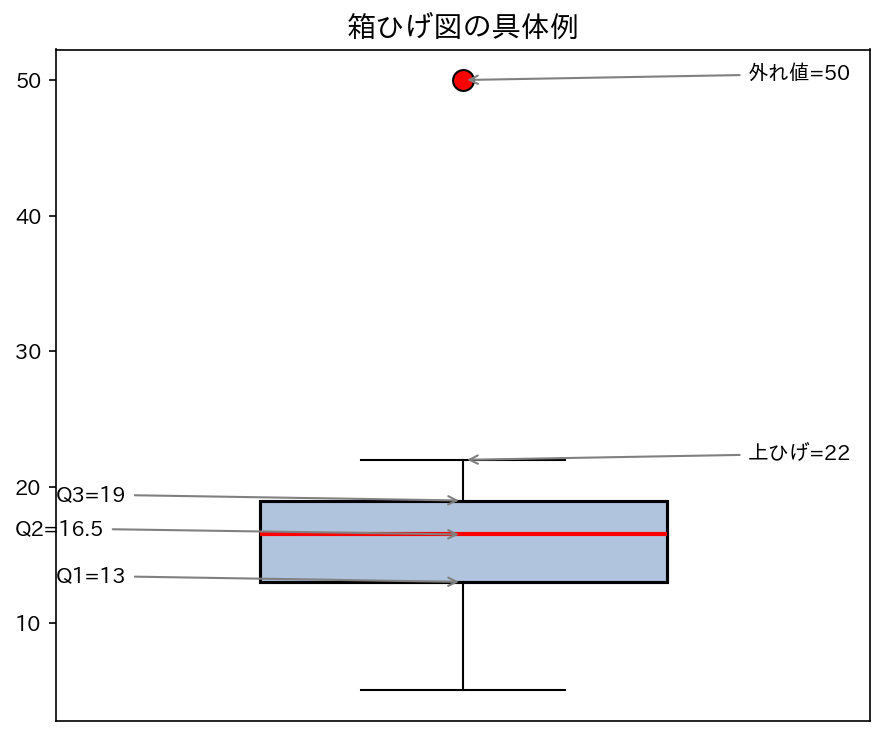
[図4] 箱ひげ図の構造
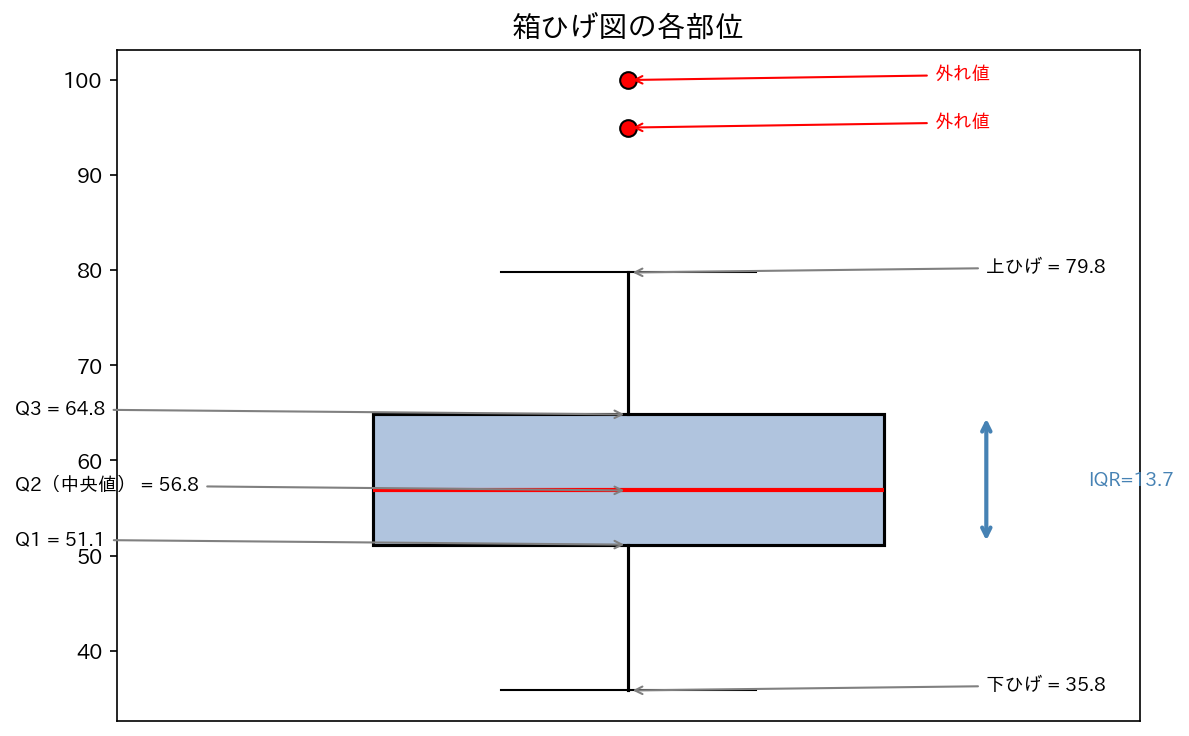
4.1 外れ値の検出:1.5 × IQR ルール
IQR(四分位範囲)= Q3 − Q1 を使って、外れ値の基準を決めます。
この範囲を超えるデータは外れ値(outlier)として、点(○)で別描きします。 ひげは、外れ値を除いた最大値・最小値まで伸ばします。
例) データ:10, 12, 14, 15, 16, 17, 18, 20, 22, 50
- Q1 = 13, Q2 = 16.5, Q3 = 19, IQR = 6
- 下限 = 13 − 9 = 4, 上限 = 19 + 9 = 28
- 50 は上限28を超えるので外れ値
- ひげの上端は22(外れ値を除いた最大値)
[図5] 外れ値ありの箱ひげ図
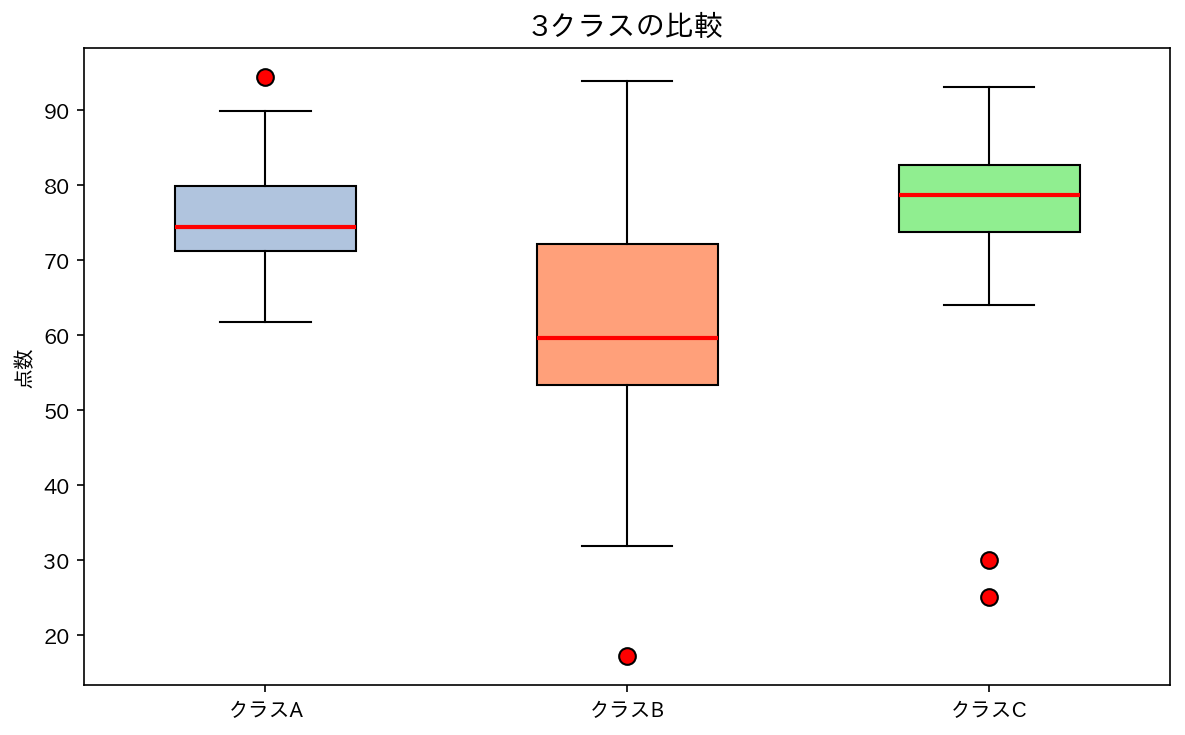
4.2 箱ひげ図でグループを比較する
箱ひげ図の最大の強みは、複数のグループを並べて一気に比較できる点です。
[図6] クラスA・B・Cの点数比較(箱ひげ図)
- クラスA:中央値が高く、ばらつきも中程度
- クラスB:中央値が低く、ばらつきが大きい(幅が広い箱)
- クラスC:中央値が高く、箱が右に偏っている。外れ値あり
5. ヒストグラムと箱ひげ図の使い分け
どちらも量的データの分布を見るグラフですが、得意な場面が違います。
| ヒストグラム | 箱ひげ図 | |
|---|---|---|
| 分布の形(歪み・双峰) | ◎ | △ |
| 外れ値の可視化 | △ | ◎ |
| 複数グループの比較 | △(並べると見づらい) | ◎ |
| 5数要約の視覚化 | △ | ◎ |
| データの密度感 | ◎ | △ |
使い分けの基準: -1グループの分布の形を詳しく見たい→ ヒストグラム -外れ値を検出したい / グループ間を比較したい→ 箱ひげ図
📘 専門的な補足:茎葉図(Stem-and-Leaf Plot)
ヒストグラムと似た目的を持ちながら、元のデータ値を保持する図が茎葉図です。
例)テスト点数:43, 55, 61, 68, 72, 74, 75, 81, 88, 93
茎 | 葉 4 | 3 5 | 5 6 | 1 8 7 | 2 4 5 8 | 1 8 9 | 3横にすると分布の形がヒストグラムと同じように見え、かつ元の値も読み取れます。 データ数が少ない(20〜50程度)場合に特に有用です。
📘 専門的な補足:正規分布と分布の形の対応
統計学で最も重要な分布は正規分布(Normal Distribution)です。 ヒストグラムが「左右対称の釣り鐘型」に近い分布は正規分布に近く、多くの統計的手法(t検定・信頼区間など)の前提条件を満たしやすいです。
「正規性の確認」は実務でも重要なステップです。視覚的にはヒストグラムで確認し、より厳密には正規確率プロット(Q-Qプロット)や統計的検定(Shapiro-Wilk検定など)を使います。これらは推定・検定の章で改めて扱います。
6. 演習問題
問題1(度数分布表の作成)
以下の20人の試験点数から度数分布表を完成させ、最も度数が大きい階級を答えてください。 階級幅は10点(40〜50未満、50〜60未満、…、90〜100以下)で作成してください。
💡 解答・解説を見る
各点数を階級に振り分けると:
| 階級(点) | 該当データ | 度数 | 相対度数 |
|---|---|---|---|
| 40〜50未満 | 48 | 1 | 0.05 |
| 50〜60未満 | 55, 59, 55, 58 | 4 | 0.20 |
| 60〜70未満 | 62, 66, 61, 68, 63 | 5 | 0.25 |
| 70〜80未満 | 73, 70, 77, 74, 79, 72 | 6 | 0.30 |
| 80〜90未満 | 81, 83, 85 | 3 | 0.15 |
| 90〜100以下 | 92 | 1 | 0.05 |
| 合計 | — | 20 | 1.00 |
最も度数が大きい階級:70〜80未満(6人)
相対度数を見ると、60〜79点の2つの階級で全体の55%を占めており、データの中心がこのあたりにあることがわかります。
問題2(ヒストグラムの読み取り)
あるヒストグラムを読み取ったところ、次のような分布でした。
度数
8 | ██
7 | ████
6 | ████████
5 | ████████
4 | ██████████
3 | ████████████
2 | ██████████████
1 | ████████████████
+--+--+--+--+--+--+--+
0 2 4 6 8 10 12 (値)
(1)この分布の形を「正の歪み・負の歪み・対称」で答えてください。 (2)平均値と中央値のどちらが大きいか、理由とともに答えてください。
💡 解答・解説を見る
(1)分布の形:正の歪み(右裾が長い)
左側(小さい値)に度数が集中しており、右側(大きい値)に向かって度数が減りながら裾を引いています。これを「正の歪み(right-skewed)」と呼びます。
(2)平均値 > 中央値
正の歪みの分布では、大きい値の外れ値が平均を右(大きい方)へ引っ張ります。一方、中央値は順位で決まるため外れ値の影響を受けにくく、より左(小さい側)に位置します。
年収・資産額・医療費など、現実世界の経済データにはこのような右裾の長い分布が多く見られます。
問題3(箱ひげ図の読み取りと比較)
2つのクラスの試験点数について、箱ひげ図から次の5数要約が読み取れました。
| 最小値 | Q1 | 中央値 | Q3 | 最大値 | |
|---|---|---|---|---|---|
| クラスA | 50 | 62 | 72 | 80 | 95 |
| クラスB | 30 | 55 | 70 | 85 | 98 |
(1)各クラスのIQRを求めてください。 (2)「1.5 × IQRルール」を使って、クラスBで30点が外れ値かどうか判定してください。 (3)クラスAとクラスBのどちらのほうが「ばらつきが大きい」といえるか、IQRを根拠に答えてください。
💡 解答・解説を見る
(1)各クラスのIQR:
(2)クラスBの30点が外れ値かどうか:
30点 > 10点 なので、下限(10点)を超えていない → 外れ値ではない
ひげは最小値30点まで伸びます。
(3)ばらつきの比較:
クラスBのほうがばらつきが大きい。
IQRは中央50%のデータの広がりを示します。クラスBのIQR(30点)はクラスA(18点)より大きく、中間層の点数のばらつきが大きいことを意味します。
補足:中央値はA(72点)とB(70点)でほぼ同じですが、IQRに大きな差があります。「平均(または中央値)だけで比較しない」ことが重要です。
まとめ
| グラフ | 何を見るか | 強み |
|---|---|---|
| 度数分布表 | 区間ごとの集計 | 数値として正確に把握できる |
| ヒストグラム | 分布の形・ピーク・歪み | 「形」を視覚的に把握できる |
| 箱ひげ図 | 5数要約・外れ値・グループ比較 | 複数グループを一度に比較できる |
この章のキーメッセージ: 数値(平均・標準偏差)とグラフ(ヒストグラム・箱ひげ図)は補完関係にあります。どちらか一方だけでは全体像は見えません。データを見るとき、「まずグラフで形を確認してから数値で詳細を確認する」流れを習慣にしましょう。
次の章へ
記述統計の数値と可視化を学んだ次のステップは、「どのようにデータを収集するか」です。 どんなに優れた分析も、収集方法が偏っていれば結論は信頼できません。
→ 次: データの収集とサンプリング:バイアスのない調査設計