第3章:仮説検定の考え方
Stage 4:標本から母集団へ
この章で学ぶこと
標本データから得た結果が「偶然のばらつき」なのか「意味のある差」なのかを判断する手続きが、仮説検定(hypothesis testing)です。
「新しい薬は効くか」「2つのグループに差があるか」——こうした問いに、データに基づいて答えるための論理的な枠組みを身につけます。
1. 仮説検定の基本的なロジック
「証明」ではなく「反証」
仮説検定は、「主張を直接証明する」のではなく、「その逆を否定する」という論法を使います。
数学の背理法に似た考え方です。
「新薬は効果がある」を直接証明したい → まず「新薬に効果はない」と仮定する → データを見たとき、この仮定のもとで得られる確率が非常に小さければ → 「効果がない」という仮定が疑わしい → 仮定を棄却する
これが仮説検定の骨格です。
2. 帰無仮説と対立仮説
帰無仮説 H₀(null hypothesis)
検定で否定しようとする仮説です。多くの場合「差がない」「効果がない」という内容になります。
例:
- $H_0$:新薬の効果はプラセボと変わらない($\mu_1 = \mu_2$)
- $H_0$:コインは公正である($p = 0.5$)
- $H_0$:二群の平均に差はない($\mu = \mu_0$)
対立仮説 H₁(alternative hypothesis)
検定で採択しようとする仮説です。研究者が「示したいこと」になります。
例:
- $H_1$:新薬の効果はプラセボより高い
- $H_1$:コインは偏っている($p \neq 0.5$)
- $H_1$:二群の平均に差がある
両側検定と片側検定
対立仮説の立て方によって、検定の方向性が変わります。
両側検定(two-tailed test):
「大きい方向にも小さい方向にも差がある可能性がある」場合に使います。検定に方向性の先入観がない場合のデフォルト選択です。
片側検定(one-tailed test):
「一方向の差だけに関心がある」場合に使います。理論的な根拠があるときにのみ使用します。
注意:「p値が小さくなるから」という理由だけで片側検定を選ぶのは不正直な分析です。仮説はデータを見る前に設定します。
3. 有意水準 α と棄却域
関連教材(青の統計学)
有意水準(significance level)α
帰無仮説を棄却するためのしきい値です。一般的には $\alpha = 0.05$(5%)が使われます。
$\alpha = 0.05$ の意味:
「帰無仮説が本当に正しいとき、誤って棄却してしまう確率を5%以下に設定する」
この5%という値は統計的な慣習であり、絶対的なものではありません。医薬品承認では $\alpha = 0.01$、探索的研究では $\alpha = 0.10$ を使うこともあります。
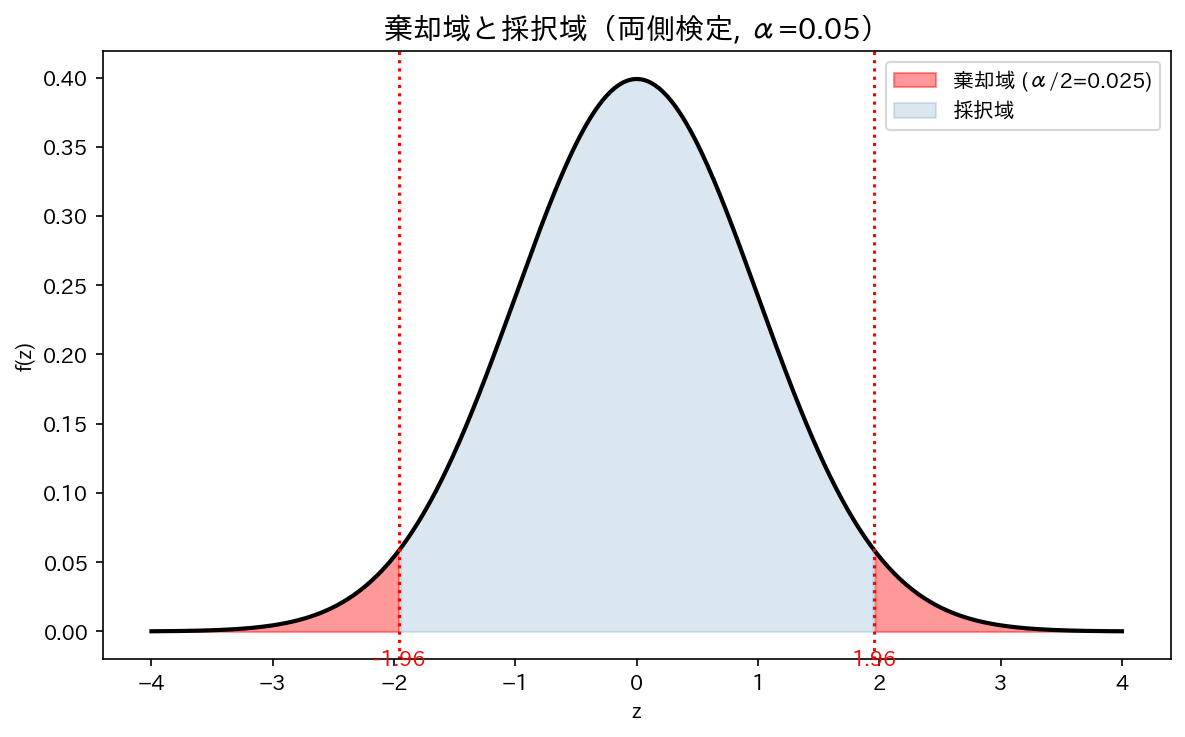
棄却域(rejection region)
検定統計量の値が「帰無仮説と矛盾する」と判断する範囲のことです。
両側検定($\alpha = 0.05$)での棄却域:
4. p値
関連教材(青の統計学)
p値の定義
もう少し丁寧に言うと:
「もし帰無仮説が正しければ、今回の実験で得られた結果(またはそれ以上に極端な結果)が偶然起きる確率はどれくらいか」
p値が小さいほど、帰無仮説のもとでは「起きにくい結果」だったことを示します。
p値と有意水準の比較
| p値と α の関係 | 判断 |
|---|---|
| $p < \alpha$ | 帰無仮説を棄却する → 統計的に有意 |
| $p \geq \alpha$ | 帰無仮説を棄却できない → 統計的に有意でない |
具体例:
薬の投与前後で血圧が平均5mmHg下がった。検定を行った結果、$p = 0.03$。
$\alpha = 0.05$ とすると $p = 0.03 < 0.05$ なので、帰無仮説「薬に効果はない」を棄却できます。
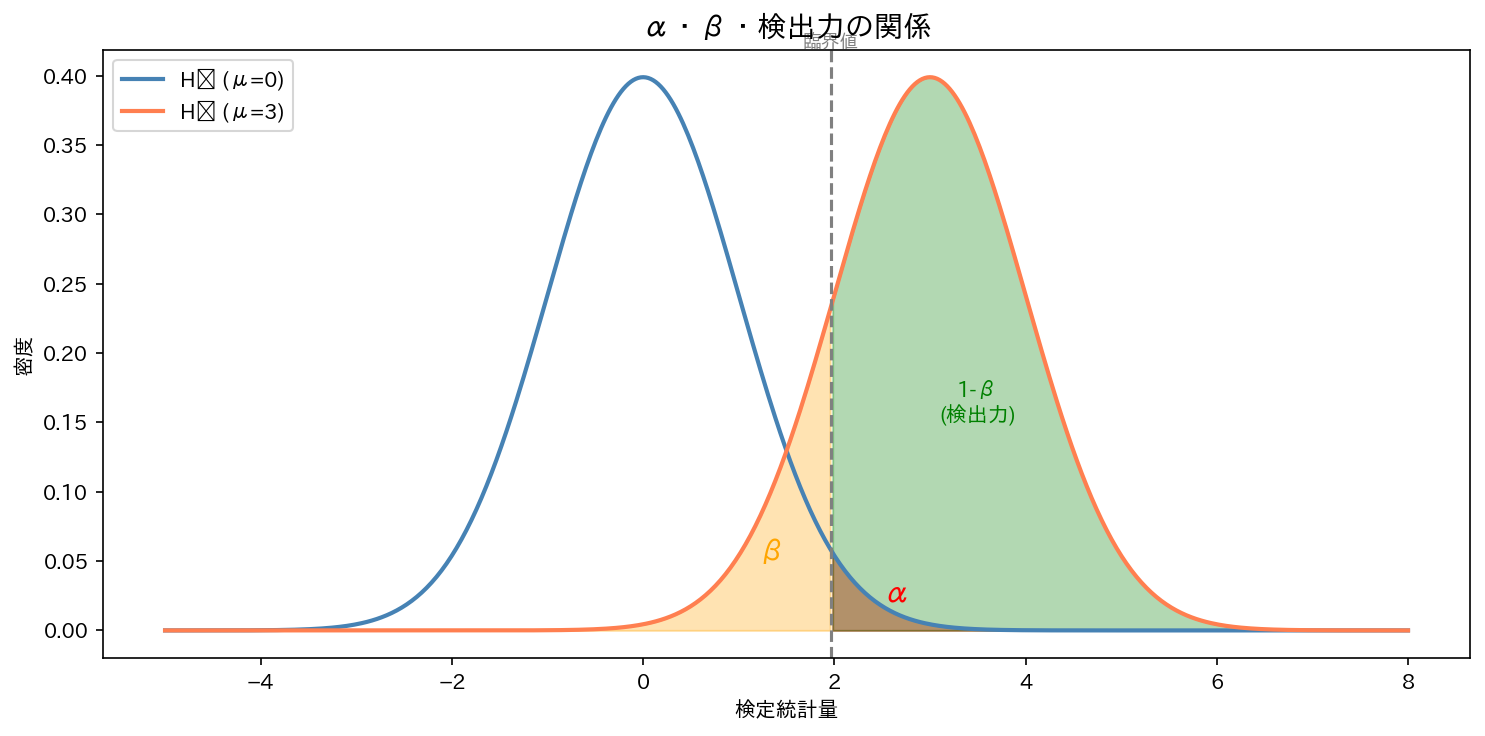
5. 第一種の過誤・第二種の過誤
検定の判断は4通りの結果に分かれます。
| 帰無仮説が真 | 帰無仮説が偽 | |
|---|---|---|
| 棄却する | 第一種の過誤(Type I Error)確率 = α | 正しい判断(検出力 = 1 - β) |
| 棄却しない | 正しい判断(確率 = 1 - α) | 第二種の過誤(Type II Error)確率 = β |
第一種の過誤(Type I Error)
効果がないのに「ある」と結論してしまう過誤です。
- 確率は有意水準 α に等しい($\alpha$ が小さいほど第一種の過誤は減る)
- 「無実なのに有罪にしてしまう」過誤に相当
第二種の過誤(Type II Error)
効果があるのに「ない」と結論してしまう過誤です。
- 確率は β(ベータ)で表す
- 「有罪なのに無罪にしてしまう」過誤に相当
検出力(power)
検出力が高いほど「効果があれば、それを検出できる能力が高い」ことを意味します。
α と β のトレードオフ
α を小さくすると(第一種の過誤を減らすと)、β が大きくなる(第二種の過誤が増える)傾向があります。
検出力を高めるには:
- 標本サイズを増やす(最も効果的)
- 有意水準 α を大きくする
- 効果量(実際の差)が大きいほど自然に上がる
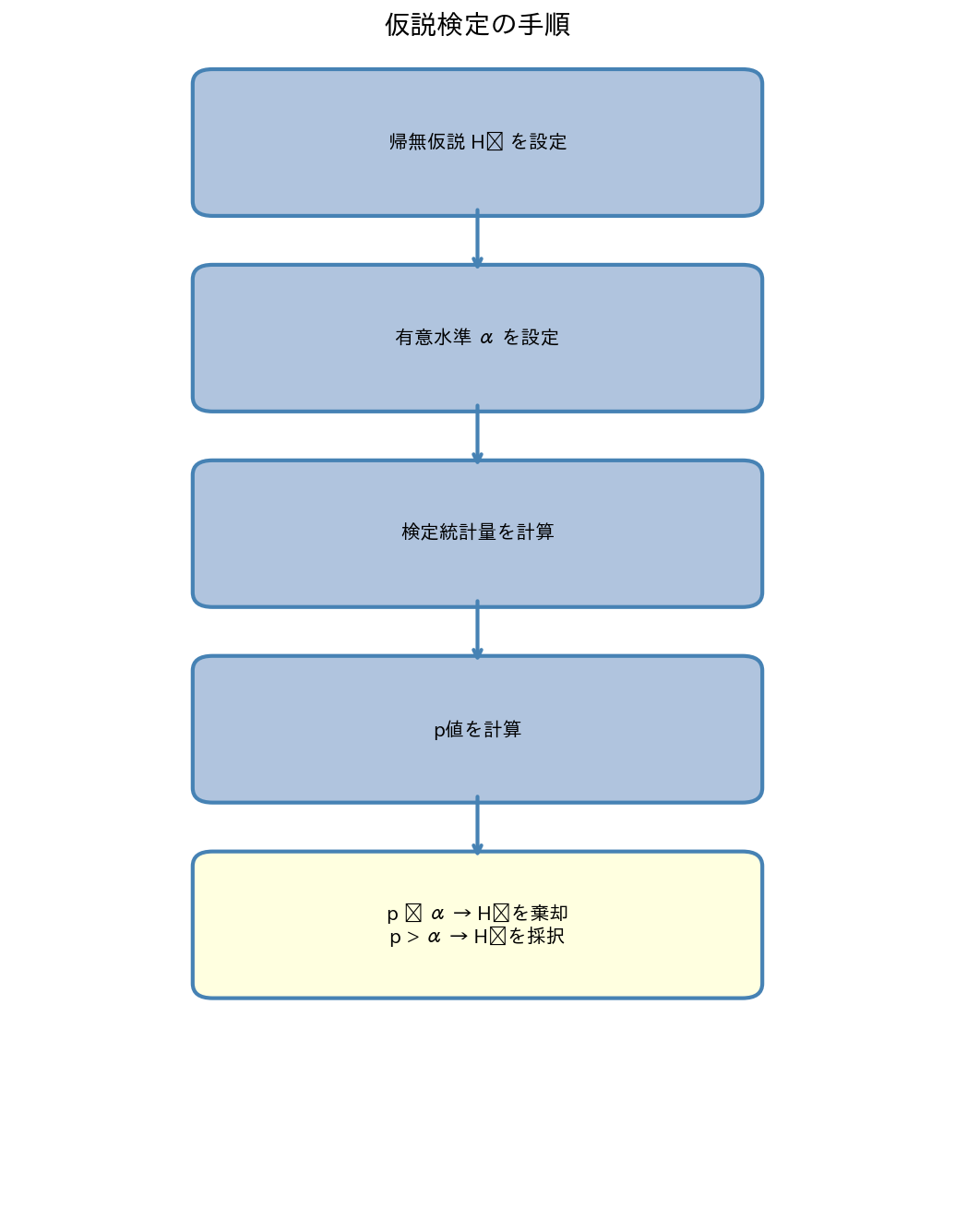
6. 検定の5ステップ
仮説検定は、以下の手順に沿って行います。
Step 1:仮説の設定
帰無仮説 $H_0$ と対立仮説 $H_1$ を、データを見る前に設定します。
Step 2:有意水準の決定
$\alpha$ を設定します(通常 0.05)。
Step 3:検定統計量の計算
データから検定統計量(z値・t値・χ²値など)を計算します。
Step 4:p値の算出(または棄却域との比較)
検定統計量から p値を計算し、有意水準と比較します。
Step 5:結論の導出
- $p < \alpha$ → 帰無仮説を棄却。「統計的に有意な差がある」
- $p \geq \alpha$ → 帰無仮説を棄却できない。「統計的に有意な差は認められない」
「有意差なし」は「差がない」と同じではありません。「今回のデータでは差を検出できなかった」という意味です。
7. p値についてのよくある誤解
❌ 誤解1:「p値 = 帰無仮説が正しい確率」
p値は「帰無仮説のもとで観測結果が得られる確率」であり、「帰無仮説が正しい確率」ではありません。
$p = 0.03$ は「帰無仮説が正しい確率が3%」ではなく、「H₀が正しければ、この結果が偶然起きる確率が3%」です。
❌ 誤解2:「p < 0.05 なら効果が大きい」
p値は効果の大きさを示しません。標本サイズが大きければ、非常に小さな差でも p < 0.05 になります。
効果の大きさは効果量(effect size)で評価します(例:Cohen's d)。
❌ 誤解3:「p ≥ 0.05 なら差がない」
「差を検出できなかった」だけであり、「差が存在しない」という証明ではありません。検出力が低ければ、真の差があっても検出できません。
❌ 誤解4:「p値は0.05という境界で二値化できる」
$p = 0.049$ と $p = 0.051$ の間に本質的な差はありません。p値は連続的な証拠の強さを示すものであり、単純な二値判断には注意が必要です。
📘 補足:なぜ「証明」できないのか
仮説検定は、帰無仮説を棄却するか否かしか言えません。帰無仮説が「真である」と証明することは原理的にできません。
これは、帰無仮説を棄却できないとき「H₀が真だから」なのか「標本サイズが足りなかっただけ」なのか、区別できないためです。
この非対称性は統計的推論の根本的な限界であり、仮説検定を使う際に常に意識しておく必要があります。
演習問題
問題1
あるメーカーは「うちのバッテリーの平均寿命は500時間以上だ」と主張している。これを検証するため、消費者団体が25個を抜き取り検査した。
この状況について、帰無仮説と対立仮説を適切に設定してください。また、両側検定と片側検定のどちらが適切かを理由とともに答えてください。
解答を見る
帰無仮説 $H_0$:母平均の寿命 $\mu = 500$(時間)
対立仮説 $H_1$:母平均の寿命 $\mu < 500$(時間)
片側検定が適切です。
消費者団体は「500時間を下回っているかどうか」を調べたいのであり、「500時間を超えているかどうか」には関心がありません。主張の「下回る方向」のみを検証する理論的根拠があるため、片側検定(左側)を使います。
もし「500時間と異なるかどうか」を検証するなら両側検定が適切ですが、この文脈では片側検定が自然です。
問題2
あるサプリメントの効果を検定したところ、$p = 0.04$ という結果が得られた(有意水準 $\alpha = 0.05$)。
次のA〜Dの解釈について、それぞれ正しいか誤りかを判断してください。
- A:帰無仮説が正しい確率は4%である
- B:帰無仮説を棄却できる
- C:サプリメントには大きな効果がある
- D:もし帰無仮説が正しければ、今回以上に極端な結果が得られる確率が4%である
解答を見る
A:誤り。p値は「帰無仮説が真のとき観測結果が得られる確率」であり、「帰無仮説が正しい確率」ではありません。
B:正しい。$p = 0.04 < \alpha = 0.05$ なので、帰無仮則を棄却できます。
C:誤り。p値は効果の大きさを示しません。$p < 0.05$ は統計的有意性を示すだけで、効果量とは別の話です。標本サイズが大きければ、非常に小さな差でも有意になります。
D:正しい。これがp値の正確な定義です。
問題3
新しい教育プログラムの効果を検定した。実際には教育プログラムに効果があったが、検定の結果「有意差なし($p = 0.12$)」と判断してしまった。
(1) これは第何種の過誤か答えてください。 (2) この過誤を減らすために有効な対策を1つ挙げてください。
解答を見る
(1) 第二種の過誤(Type II Error)
帰無仮説(「教育プログラムに効果はない」)が実際には偽であるにもかかわらず、棄却できなかった場合が第二種の過誤(β)です。
「効果があったのに、ないと結論してしまった」誤りに相当します。
(2) 対策:標本サイズを増やす
第二種の過誤を減らす(検出力を上げる)最も効果的な方法は、標本サイズを増やすことです。
標本サイズが大きいほど、標本平均のばらつき(標準誤差)が小さくなり、帰無仮説のもとでは起きにくい値になる確率が上がります。その結果、真の効果がある場合に正しく検出できる確率(検出力)が高まります。
なお、有意水準 $\alpha$ を大きくする(例:0.05→0.10)と β は減りますが、第一種の過誤が増えるトレードオフが生じます。
📘 補足コラム:多重検定・検出力・サンプルサイズ設計
関連教材(青の統計学)
多重検定問題(multiple testing problem)
1つの研究で複数の仮説を同時に検定すると、「少なくとも1つで誤って棄却してしまう確率」が α より大きくなります。これをファミリーワイズ誤り率(FWER)の膨張と言います。
例:20個の独立な仮説をすべて α = 0.05 で検定すると、H₀がすべて真でも
約64%の確率で「偽の有意」が生じます。
Bonferroni 補正は、各検定の有意水準を $\alpha / m$($m$ = 検定の数)に下げることで FWER を α 以下に抑える、最もシンプルな補正法です。
例:20個の検定を行うなら、各検定の閾値を $0.05/20 = 0.0025$ にします。
ただし Bonferroni 補正は保守的すぎる(真の差を見逃しやすい)という欠点があります。大規模データでは、偽発見率(FDR)を制御する Benjamini-Hochberg 法がよく使われます。
検出力とサンプルサイズ設計
実験や調査を設計する際は、「どれくらいの標本サイズがあれば十分か」を事前に計算します(事前検出力分析)。
検出力に影響する要素:
| 要素 | 検出力への影響 |
|---|---|
| 標本サイズ $n$ | 大きいほど検出力が上がる |
| 効果量(実際の差の大きさ) | 大きいほど検出力が上がる |
| 有意水準 α | 大きいほど検出力が上がる(第一種の過誤とトレードオフ) |
| ばらつき $\sigma$ | 小さいほど検出力が上がる |
一般的な目標値は検出力 0.80(80%)です。つまり「真の効果があれば80%の確率で検出できる」標本サイズを設計時に確保します。
事前にサンプルサイズを設計せずに実験した後で「検出力が低かった」と言っても意味がありません(事後検出力分析の問題点)。研究の計画段階で検出力を考慮することが重要です。
まとめ
| 概念 | 内容 |
|---|---|
| 帰無仮説 H₀ | 「差がない・効果がない」という否定的な仮説 |
| 対立仮説 H₁ | 示したい仮説(両側または片側) |
| 有意水準 α | 誤って棄却してよい確率の上限(通常0.05) |
| p値 | H₀のもとで観測結果以上に極端な値が出る確率 |
| 第一種の過誤 | 本当はH₀が真なのに棄却してしまう過誤(確率 = α) |
| 第二種の過誤 | 本当はH₀が偽なのに棄却できない過誤(確率 = β) |
| 検出力 | 1 - β。効果があるとき正しく検出できる確率 |
次の章では、実際の検定手法(z検定・t検定・χ²検定)を学びます。