データはどこから来るか:サンプリングと調査設計
Stage 1 — 第3章| 統計学基礎カリキュラム 推定学習時間:35〜45分 | 難易度:★☆☆☆☆
この章で学ぶこと
どんなに高度な分析も、データの収集方法が偏っていれば結論は信頼できません。 「どのようにデータを集めるか」は、統計学の根幹です。
この章を終えると、こんなことができるようになります:
- 母集団・標本・パラメータ・統計量の違いを説明できる
- 無作為抽出・層別抽出・クラスター抽出の違いを使い分けられる
- 選択バイアス・非回答バイアス・生存者バイアスを見抜ける
- 「相関関係がある」と「因果関係がある」の違いを明確に説明できる
- 交絡変数の概念を説明できる
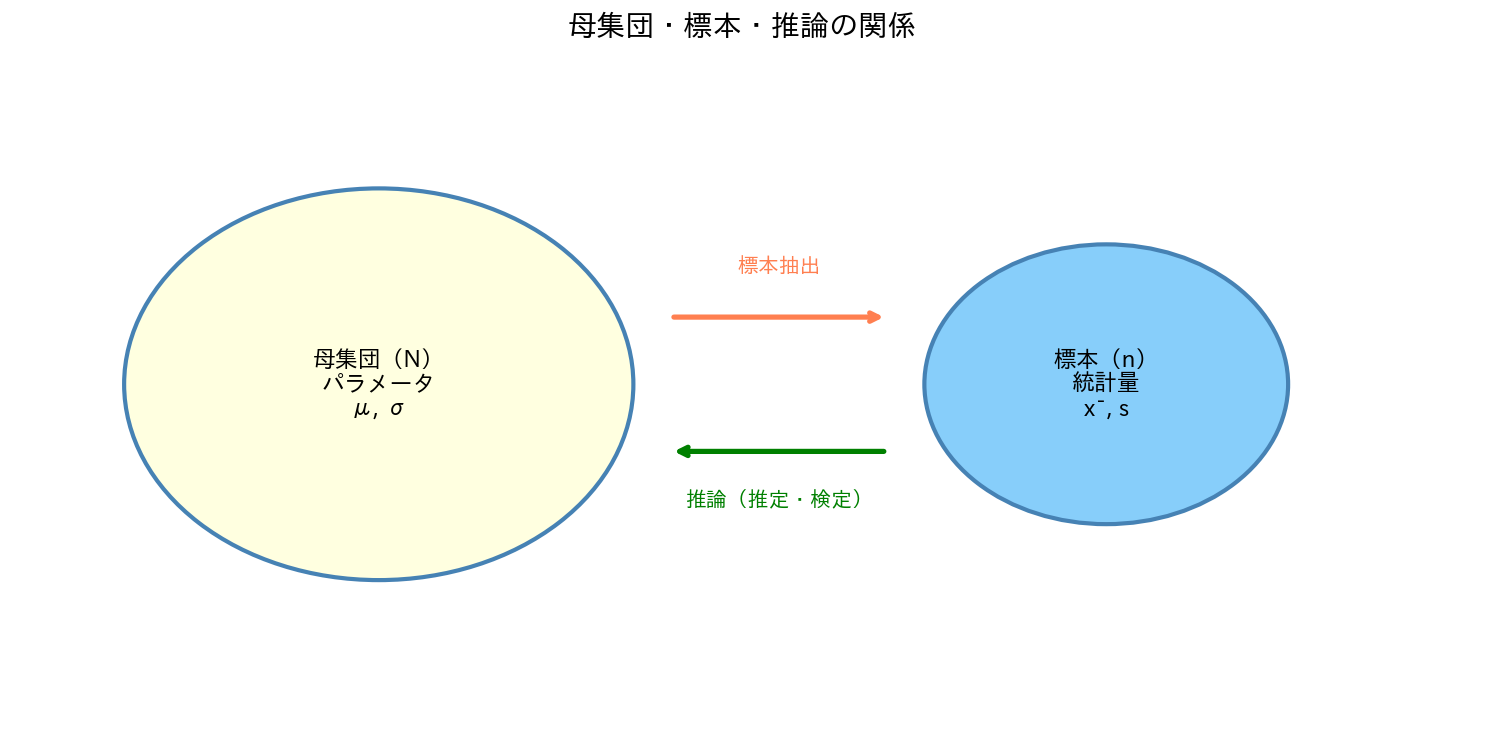
1. 母集団と標本:なぜ全員を調べないのか
1.1 基本用語の整理
| 用語 | 定義 | 例 |
|---|---|---|
| 母集団(population) | 知りたい対象の全体 | 日本の全有権者(約1億人) |
| 標本(sample) | 母集団から実際に選んだ一部 | 選挙前の世論調査で選んだ1000人 |
| パラメータ(母数) | 母集団の特性値 | 全有権者のA党支持率 |
| 統計量 | 標本から計算した値 | 調査した1000人のA党支持率 |
なぜ全数調査(センサス)しないのか?
全員を調べることが理想ですが、現実には次の壁があります:
- コスト:1億人に聞くには膨大な費用と時間がかかる
- 破壊検査:製品の強度テストは壊すことが前提なので、全数検査は全滅を意味する
- 実現不可能性:海の魚の数、大気中の微粒子数など、そもそも全数把握が不可能
だから私たちは標本から母集団を推論(推測統計)するのです。
[図1] 母集団・標本・推論の関係
1.2 代表性が命
標本を使って母集団を語るために、最低限満たすべき条件が代表性(representativeness)です。
標本が母集団の縮図になっていれば、標本の統計量はパラメータの良い推定値になります。 代表性を担保するのが、次節で学ぶ「正しいサンプリング」です。
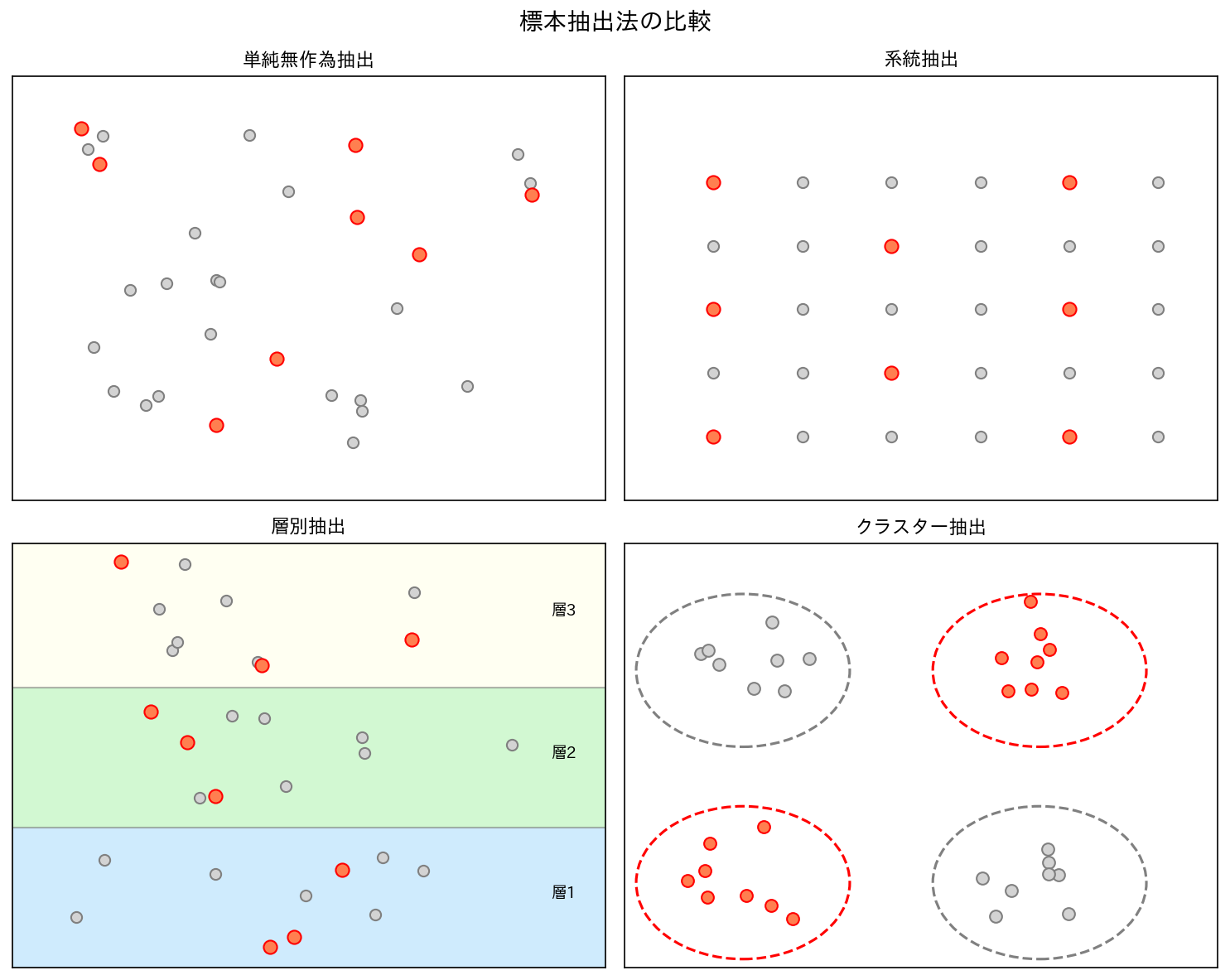
2. サンプリングの種類
関連教材(青の統計学)
2.1 単純無作為抽出(Simple Random Sampling)
母集団の全メンバーに等しい確率で選ばれるチャンスを与える方法。
- くじ引き・乱数表・コンピュータの乱数生成を使う
- 最も基本的で、バイアスが入りにくい
- 母集団リストが必要なため、リストが存在しない場合は使えない
$N$:母集団の大きさ、$n$:標本サイズ
2.2 系統抽出(Systematic Sampling)
母集団リストから、一定間隔おきに選ぶ方法。
例) 1000人のリストから100人を選ぶ場合:
- 間隔 $k = 1000 / 100 = 10$ を計算
- 最初の1〜10の中からランダムに開始点を決める(例:3番)
- 3番、13番、23番、33番… と等間隔で選ぶ
- 単純無作為抽出より実施しやすい
- ⚠️ リストに周期性がある場合、その周期と間隔が一致するとバイアスが生まれる
2.3 層別抽出(Stratified Sampling)
母集団をあらかじめいくつかの層(グループ)に分け、各層から無作為に抽出する方法。
例) 大学生1000人から100人を選ぶ
- 1年生(300人)→ 30人抽出
- 2年生(250人)→ 25人抽出
- 3年生(250人)→ 25人抽出
- 4年生(200人)→ 20人抽出
各層の比率を保つ(比例割当)ことで、全体の代表性が高まる。 特に、層ごとに意見や特性が大きく違う場合に有効。
2.4 クラスター抽出(Cluster Sampling)
母集団をいくつかのクラスター(塊)に分け、クラスターをランダムに選び、選ばれたクラスター内の全員(または一部)を調査する方法。
例) 全国の小学生の学力調査
学校(クラスター)をランダムに50校選ぶ
選ばれた学校の生徒全員を調査
コストが大幅に削減できる(調査員の移動が少ない)
同じクラスター内のデータは似た傾向を持つため、層別抽出より統計的効率は低い
[図2] 4種類のサンプリング比較
📘 専門的な補足:標本サイズと精度の関係
「標本を大きくすれば精度が上がる」は正しいですが、収穫逓減があります。
標本平均の標準誤差(精度の指標)は次の式で表されます:
\[ SE = \frac{\sigma}{\sqrt{n}} \]$\sigma$:母標準偏差、$n$:標本サイズ
- $n$ を4倍にすると、精度は2倍($\sqrt{4}=2$)
- $n$ を100倍にすると、精度は10倍($\sqrt{100}=10$)
つまり精度を2倍にするには、標本を4倍にする必要があります。大規模調査は「費用対効果」を見ながら標本サイズを決める必要があります。これは推定の章で詳しく扱います。
3. バイアスの罠
バイアス(bias)とは、標本が母集団を系統的に歪めて表現することです。 サンプリングが適切でも、調査の設計が悪ければバイアスは生まれます。
3.1 選択バイアス(Selection Bias)
調査対象の選ばれやすさが均等でなく、特定の傾向を持つ人が多く選ばれてしまうバイアス。
有名な歴史的失敗例:Literary Digest の1936年大統領選挙予測
- 雑誌が読者・電話帳・車の登録者リストから1000万通の調査票を送付
- 結果:共和党候補の圧倒的勝利を予測
- 実際:民主党候補(ルーズベルト)の圧勝
- 原因:1930年代の電話・雑誌・車は「富裕層の持ち物」。貧困層が調査から除外されていた
その他の例:
- 自発的回答バイアス:「満足しているか」というアンケートに、不満のある人のほうが回答しやすい
- 生存者バイアス(後述)
3.2 非回答バイアス(Non-response Bias)
調査対象に選ばれたが、回答しなかった人の特性が、回答した人と系統的に異なる場合のバイアス。
例) 健康調査で、病気の人ほど「忙しい・外出できない」などの理由で回答しない → 実際より健康な人のデータしか集まらず、「健康問題は少ない」という誤った結論になる
回答率が低い調査は非回答バイアスのリスクが高くなります。
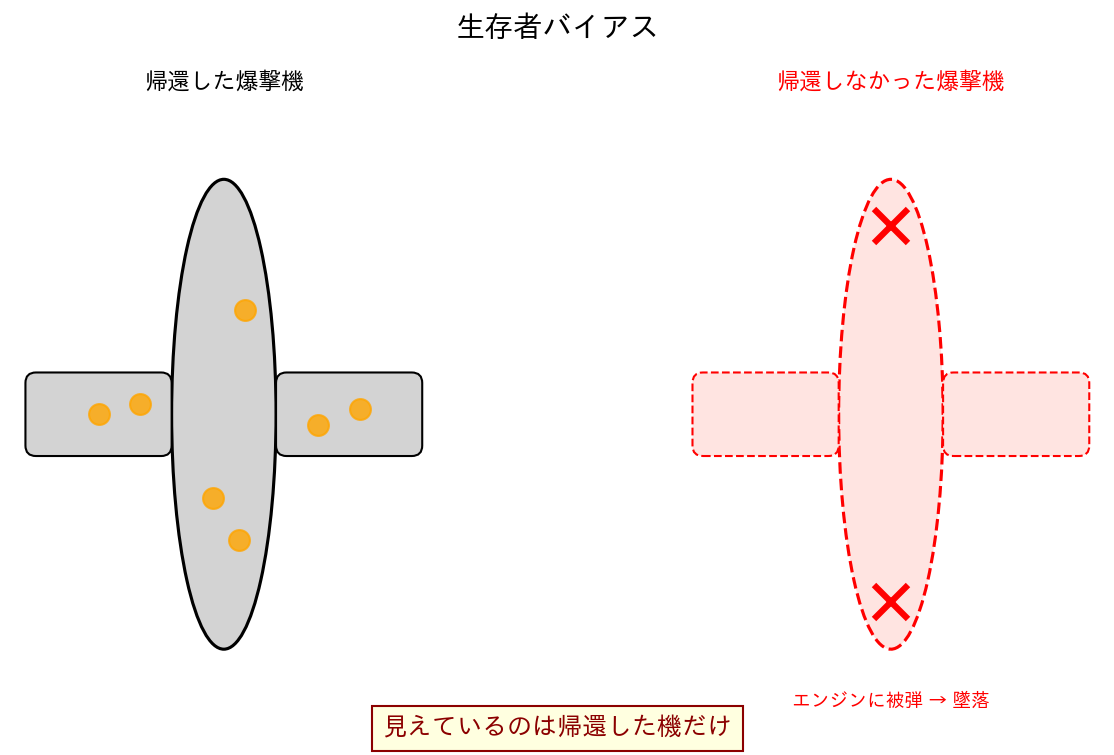
3.3 生存者バイアス(Survivorship Bias)
「生き残った」ものだけが観察でき、「消えたもの」が見えないことで生じるバイアス。
有名な例:第二次世界大戦の爆撃機
- 帰還した爆撃機を調べると、翼や胴体に多くの被弾跡があった
- 「被弾跡の多い部分を強化しよう」という案が出た
- しかし統計家エイブラハム・ウォールドは反論:「帰ってこなかった機体はエンジンに被弾している。帰還機のエンジンに弾痕がないのは、エンジンを撃たれた機は帰れなかったから」
- 見えているのは生き残ったデータだけというトラップ
現代の例:
- 「成功した起業家は大学を中退している」→ 大学中退して失敗した人は語られない
- 「古いビルは頑丈だ」→ 頑丈でなかったビルは既に壊れて残っていない
[図3] 生存者バイアスのイメージ
4. 観察研究 vs 実験研究:相関と因果
関連教材(青の統計学)
4.1 2種類の研究デザイン
| 観察研究 | 実験研究(介入研究) | |
|---|---|---|
| 研究者の介入 | なし(自然な状態を観察) | あり(条件を操作) |
| 例 | 喫煙者と非喫煙者の肺がん罹患率を比較 | 薬Aと偽薬を無作為に割り振り効果を比較 |
| 因果推論 | 困難(交絡が入る) | 可能(無作為化により交絡を制御) |
| 実施しやすさ | 比較的容易・倫理的障壁が低い | 難しい・費用がかかる・倫理審査が必要 |
4.2 相関関係と因果関係
相関関係(correlation):2つの変数が一緒に増減する傾向 因果関係(causation):一方が原因となり、もう一方が結果として引き起こされる関係
有名な例:アイスクリームの売上と水難事故
- アイスクリームの売上が増えると、水難事故も増える(正の相関)
- 「アイスを食べると溺れる?」← 違います
- 真の原因:気温が高い日はアイスもよく売れ、海や川に人が増えて事故も増える
この「第3の変数」を交絡変数(confounding variable)と呼びます。
4.3 交絡変数(Confounding Variable)
定義:2つの変数(X と Y)の両方に影響を与える隠れた変数 Z
ZをコントロールしないでXとYの関係を見ると、見せかけの相関(疑似相関)が生まれます。
例:靴のサイズと読解力の相関
- 子どもを対象に調査すると、靴のサイズが大きいほど読解力が高い傾向がある
- 交絡変数:年齢(年齢が上がると靴も大きくなるし、読解力も上がる)
実験研究が因果を言える理由:無作為割付(ランダム化)
参加者を無作為にグループ(介入群・対照群)に割り振ると、既知・未知を問わず全ての交絡変数が2グループ間で均等に分布します。その結果、グループ間の差を「介入の効果」として解釈できます。
📘 専門的な補足:二重盲検法(Double-Blind Trial)
医薬品の臨床試験で使われる最も厳格な実験設計です。
- 盲検(blind):参加者が自分が介入群か対照群かを知らない
- 二重盲検(double-blind):参加者も研究者も、どちらが薬でどちらが偽薬かを知らない
なぜ研究者も知らない必要があるのか? 研究者が知っていると、無意識に「薬を飲んでいる患者は良くなってほしい」という期待から、観察・記録・評価に偏り(観察者バイアス)が入る可能性があるためです。
「二重盲検ランダム化比較試験(RCT)」は、因果推論における「ゴールドスタンダード」とされています。
5. 演習問題
問題1(サンプリングの問題点)
ある市が「市民の行政サービス満足度」を調査するため、市役所の窓口を訪れた人300人にアンケートを配布しました。回収率は60%(180人)でした。
(1)このサンプリング方法にはどのようなバイアスが入る可能性があるか、具体的に説明してください。 (2)より代表性の高い調査設計を1つ提案してください。
💡 解答・解説を見る
(1)含まれるバイアス:
選択バイアス:市役所を訪れる人は、何らかの用事がある人(手続き中、問題を抱えている人など)に偏っています。普段行政サービスをほとんど使わない市民は調査対象に入りません。「不満があったから窓口に来た」という人が多ければ、満足度が実際より低く出る可能性があります。
非回答バイアス:回収率60%(180人)は、40%(120人)が回答しなかったことを意味します。「忙しくて書けなかった」「答えたくない」という人が系統的に特定の属性(例:不満が強い人、または逆に関心のない人)に偏っていると、結果が歪む可能性があります。
(2)改善案:
市の住民基本台帳から単純無作為抽出または層別抽出(年齢・居住地域・行政サービス利用頻度などで層別)で市民を選び、郵送またはオンラインで調査します。未回答者には追跡調査を行い、回収率を高める工夫をします。
問題2(バイアスの判定)
以下の各状況に含まれるバイアスの種類を答えてください。
(A)あるダイエットサプリの口コミサイトに、「3ヶ月で5kg痩せた!」という体験談が多く掲載されている。→ ダイエット効果があると結論づけてよいか?
(B)「日本人の英語力は低い」という調査結果があった。調査方法を見ると、英語学習者向けアプリのユーザーを対象にしていた。
💡 解答・解説を見る
(A)生存者バイアス
口コミを投稿するのは「効果があった人」または「強く不満だった人」に偏りがちです。特に「効果がなかった人」は投稿しない(あるいは記事にならない)可能性が高く、サプリの効果がないにも関わらず「効果あり」の体験談が目立つ可能性があります。このような「効果があったと感じた人の声だけが残る」現象は生存者バイアスに相当します。
→ 結論:口コミだけでは効果を判断できません。無作為化比較試験(RCT)の結果が必要です。
(B)選択バイアス
英語学習アプリのユーザーは、英語に関心がある・勉強している層に偏っています。英語を全く使わない・学んでいない人は調査に含まれません。この標本は「英語学習者」という特定の母集団しか代表しておらず、「日本人全般」の英語力を論じることはできません。
問題3(相関 vs 因果・交絡変数)
ある研究が「消防車の出動台数が多い火事ほど、被害額が大きい」という正の相関を発見しました。
(1)「消防車をたくさん出動させると被害が大きくなる」という因果解釈は正しいか? (2)この相関の真の説明を、交絡変数を明示して論じてください。 (3)この例から、相関と因果を混同することで起こりうる(実際に起こりうる)意思決定の誤りを1つ考えてください。
💡 解答・解説を見る
(1)因果解釈は誤り
消防車の出動台数を増やすことが被害を拡大させているわけではありません。これは典型的な疑似相関です。
(2)交絡変数の説明
交絡変数は「火事の規模(または深刻さ)」です。
火事が大きければ大きいほど、消防車は多く出動し、かつ被害額も大きくなります。消防車と被害額はどちらも「火事の規模」という共通の原因から生じているため、正の相関が観察されるのです。
(3)意思決定の誤りの例
「消防車を2台以上出動させると被害が大きくなる統計がある。だから火事には消防車1台で対応する」という政策を採ったとします。 → 実際には大火事に対して消防車が足りなくなり、被害が拡大する逆効果になります。
このように、相関を因果として解釈した政策は深刻な誤りを招く可能性があります。因果を確かめるには観察データだけでなく、介入実験や因果推論の手法が必要です。
まとめ
| 概念 | ポイント |
|---|---|
| 母集団 vs 標本 | 費用・実現可能性から全数調査は困難。標本で推論する |
| サンプリング | 単純無作為・系統・層別・クラスター。目的に応じて選択 |
| バイアス | 選択・非回答・生存者バイアス。見えないデータに注意 |
| 相関 ≠ 因果 | 交絡変数が「見せかけの相関」を作る |
| 因果の確認 | ランダム化比較試験(RCT)が因果推論のゴールドスタンダード |
この章のキーメッセージ: 「データがある」ことと「データが信頼できる」ことは別物です。 どのように集めたか(設計)を確認することが、分析の第一歩です。
次の章へ
記述統計の3章(代表値・可視化・サンプリング)を終えました。 次のステージでは、「不確実性を数値で扱う」確率の世界へ踏み込みます。
→ Stage 2へ:確率の基礎 — 不確実性を数値で語る