第2章:回帰分析の解釈
Stage 5:回帰・分散分析・応用
この章で学ぶこと
前章で単回帰モデルの推定方法を学びました。この章では、推定した回帰モデルを正しく解釈するための知識を扱います。
- モデル全体の有意性を F 検定で確認する
- $R^2$ の意味と限界を理解する
- 回帰係数の信頼区間と予測区間の違いを理解する
- 回帰分析の前提条件(LINE)を確認する
1. 分散分解と F 検定
平方和の分解
$y$ の変動は「モデルで説明できる部分」と「説明できない部分」に分解できます。
| 記号 | 名称 | 意味 |
|---|---|---|
| TSS | Total Sum of Squares | $y$ の全変動 |
| RegSS | Regression Sum of Squares | モデルが説明した変動 |
| RSS | Residual Sum of Squares | モデルが説明できなかった変動 |
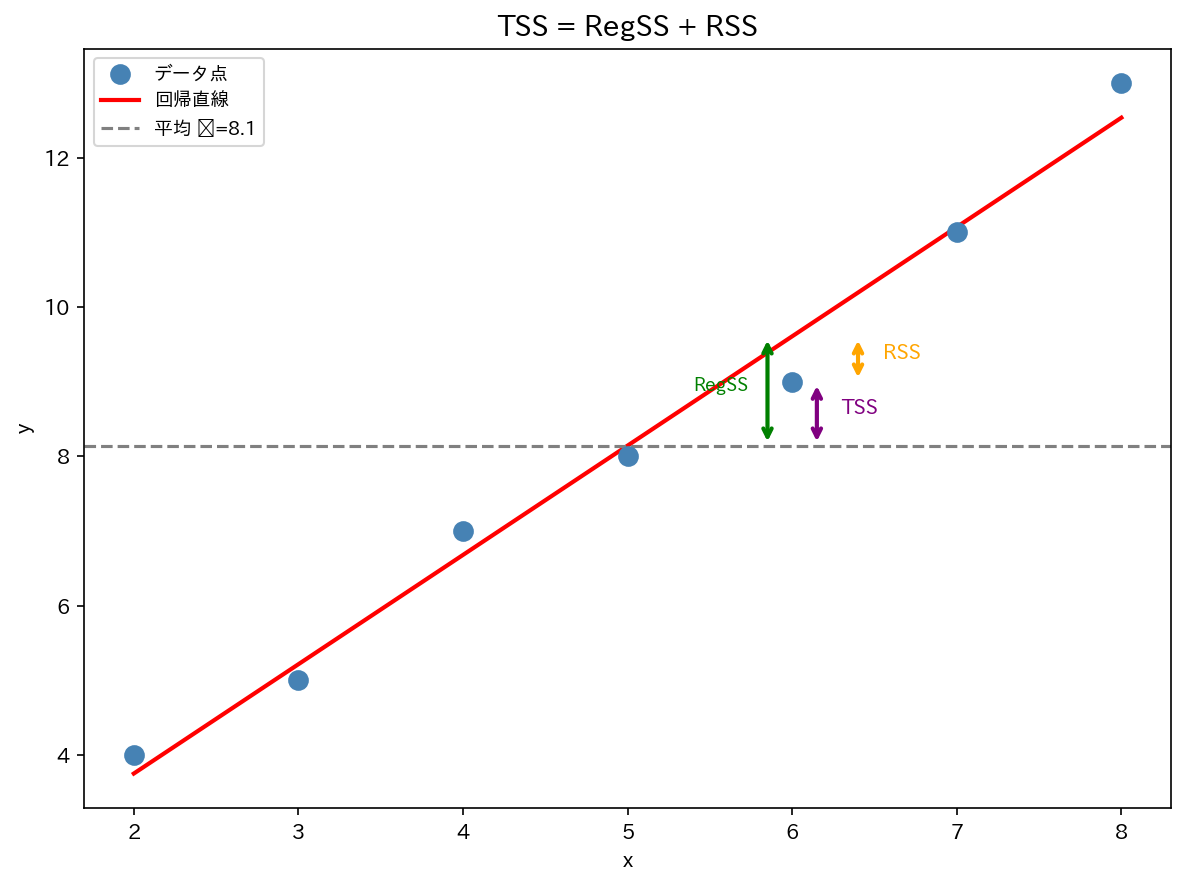
決定係数との関係
F 検定(モデル全体の有意性検定)
「このモデル全体は有意か(= $\beta_1 = 0$ でないか)」を検定します。
F 統計量(単回帰の場合):
この統計量は自由度 $(1, n-2)$ の F 分布に従います。
単回帰では $F = t^2$($\beta_1$ の t 統計量の2乗)が成り立つため、単回帰においては F 検定と t 検定は同じ結果を与えます。F 検定が本来の威力を発揮するのは、複数の説明変数を持つ重回帰の場面です。
ANOVA テーブル
統計ソフトの出力によく登場する分散分析表(ANOVA table)の構造:
| 変動要因 | 平方和 | 自由度 | 平均二乗 | F 値 |
|---|---|---|---|---|
| 回帰 | RegSS | 1 | RegSS/1 | MSR/MSE |
| 残差 | RSS | $n-2$ | RSS/$(n-2)$ | — |
| 合計 | TSS | $n-1$ | — | — |
2. 決定係数 $R^2$ の限界
関連教材(青の統計学)
$R^2$ の基本
$R^2$ はモデルの説明力を示しますが、単独では判断できない側面があります。
$R^2$ が高くても問題が起きるケース:
説明変数を増やすと $R^2$ は必ず上がる:意味のない変数を加えても、RSS は(悪くなることがないため)$R^2$ は増加します。これが重回帰での「調整済み $R^2$」が必要な理由です(次章で扱います)。
$R^2$ が高くても予測精度が低いことがある:$R^2 = 0.80$ でも、残差の絶対値が大きければ実用的な予測には使えない場合があります。
$R^2$ が低くても有用なモデルはある:社会科学や医学では $R^2 = 0.20$ 程度でも重要な知見をもたらすことがあります。
$R^2$ の正しい使い方
$R^2$ は他の指標(F 値の有意性・残差プロット・予測誤差など)と組み合わせてモデルを評価するものです。$R^2$ だけで「良いモデルかどうか」を判断するのは不十分です。
3. 回帰係数の信頼区間
$\hat{\beta}_1$ の信頼区間
$\hat{\beta}_1$ は点推定値です。その不確かさを区間で表すと:
解釈:この手続きを繰り返せば、95%の区間が真の $\beta_1$ を含む。
信頼区間が 0 を含まなければ、$\beta_1 = 0$ の棄却(有意な回帰関係がある)と一致します。
$\hat{\beta}_0$ の信頼区間
切片の信頼区間は $x = 0$ が観測範囲内にあるときのみ実用的な意味を持ちます。
4. 予測区間と信頼区間
$x = x^*$ のときの $y$ を予測したいとき、2種類の区間があります。
平均応答の信頼区間(confidence interval for mean response)
「$x = x^*$ のとき、$y$ の平均はどの範囲にあるか」
個値の予測区間(prediction interval)
「$x = x^*$ のとき、新たな1つの観測値はどの範囲に入るか」
2つの区間の比較
予測区間は信頼区間より常に広くなります。個値の予測には「1つの観測値固有のランダム変動」が加わるためです。
| 対象 | 幅 | |
|---|---|---|
| 平均応答の信頼区間 | $E[y \mid x^*]$(平均値) | 狭い |
| 個値の予測区間 | 新たな1つの $y$ 値 | 広い |
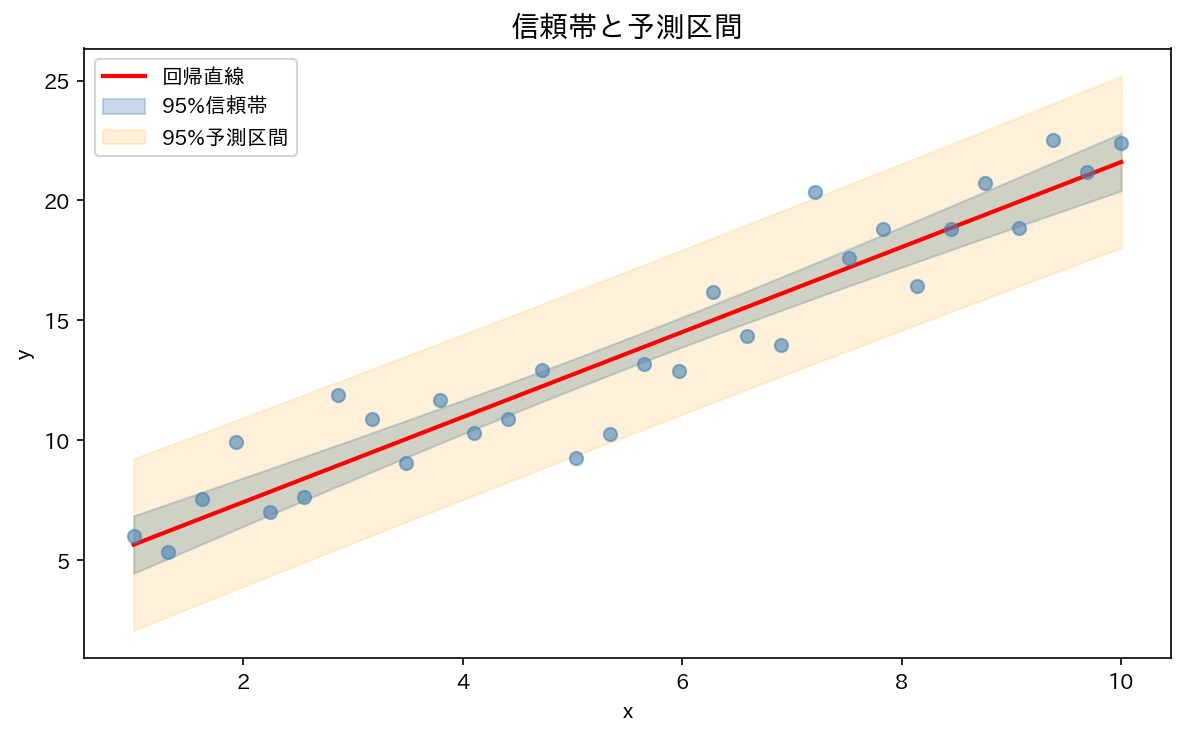
注意:$x^*$ が観測データの範囲から大きく外れると、どちらの区間も急激に広がります(外挿の危険性)。
5. 回帰分析の前提条件(LINE)
関連教材(青の統計学)
最小二乗法の統計的推論(t 検定・F 検定・信頼区間)が有効であるためには、4つの前提条件が必要です。頭文字をとってLINEと覚えます。
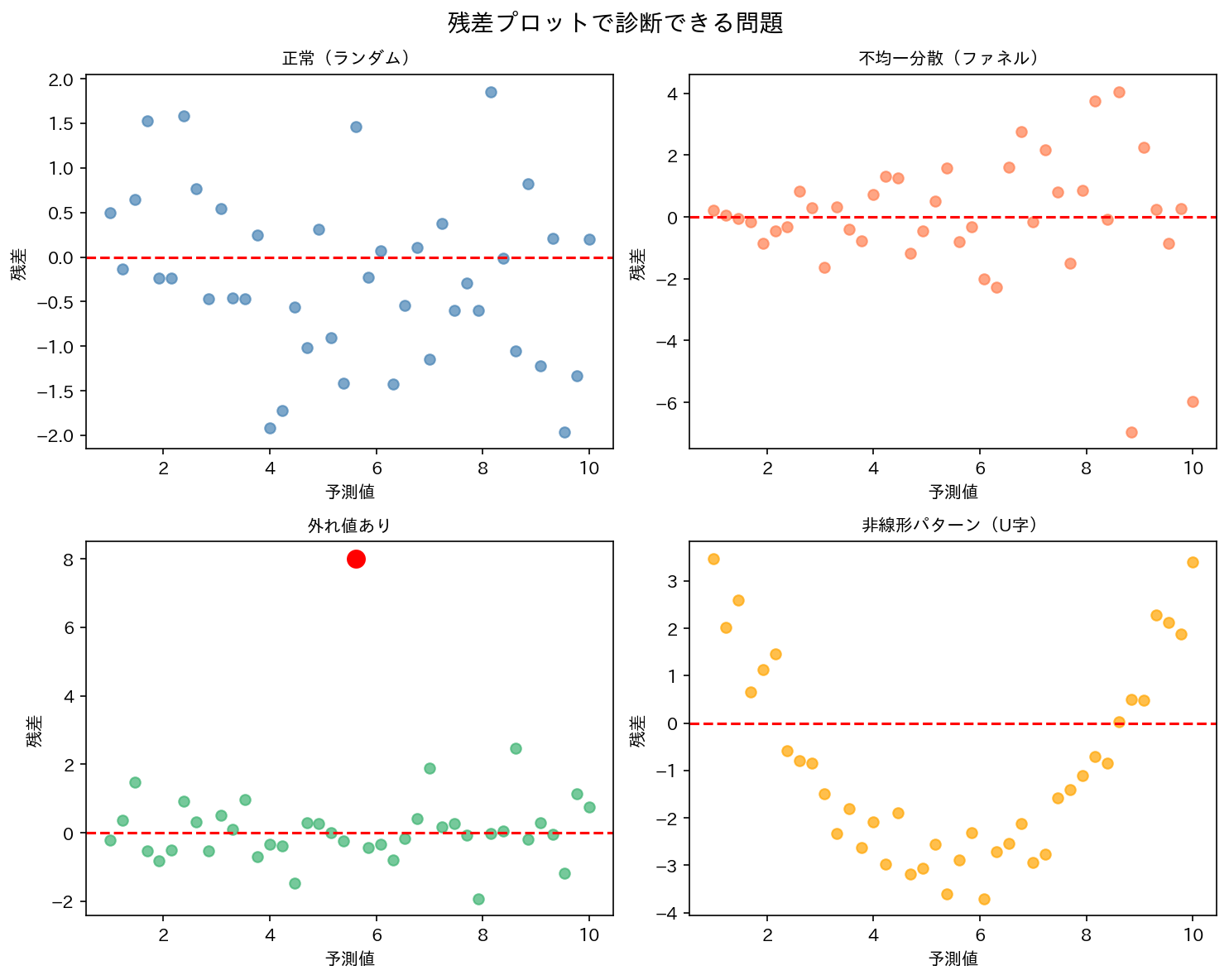
L — Linearity(線形性)
$y$ と $x$ の関係が線形であること。散布図と残差プロットで確認します。
U字型などのパターンが見られたら、変数変換や多項式項の追加を検討します。
I — Independence(独立性)
各観測値が互いに独立であること。時系列データでは自己相関が生じることがあります。
Durbin-Watson 検定で確認できます。
N — Normality(正規性)
誤差項 $\varepsilon$ が正規分布に従うこと。残差の Q-Q プロットやヒストグラムで確認します。
標本サイズが大きければ中心極限定理により多少の外れは許容されます。
E — Equal variance(等分散性)
誤差の分散が $x$ の値によらず一定であること(均一分散、homoscedasticity)。残差プロットでラッパー形状がないか確認します。
等分散が崩れている場合(不均一分散)は加重最小二乗法(WLS)や標準誤差のロバスト推定を使います。
演習問題
問題1
単回帰分析の結果、次の ANOVA テーブルが得られた($n = 22$)。
| 変動要因 | 平方和 | 自由度 |
|---|---|---|
| 回帰 | 450 | 1 |
| 残差 | 200 | 20 |
| 合計 | 650 | 21 |
(1) $R^2$ を求めてください。 (2) F 値を計算し、有意水準5%で検定してください($F_{0.05}(1, 20) = 4.35$)。
解答を見る
(1) $R^2$ の計算
$y$ の変動の約69.2%をこのモデルが説明しています。
(2) F 値の計算と検定
$F = 45.0 > 4.35 = F_{0.05}(1, 20)$ なので、有意水準5%で帰無仮説($\beta_1 = 0$)を棄却します。
モデル全体として統計的に有意です。
問題2
ある回帰分析で $\hat{\beta}_1 = 3.2$、$\text{SE}(\hat{\beta}_1) = 0.8$、$n = 25$(自由度23)だった。$t_{0.025}(23) = 2.069$ として、$\beta_1$ の95%信頼区間を求め、解釈してください。
解答を見る
解釈:この手続きを繰り返せば、95%の区間が真の $\beta_1$ を含みます。信頼区間が0を含まないため、$\beta_1 = 0$ の帰無仮説を棄却でき、$x$ は $y$ の有意な予測因子と言えます。
また、$x$ が1単位増えたとき $y$ は平均1.545〜4.855の範囲で増加すると推定できます。
問題3
残差プロットを確認したところ、$x$ が大きくなるにつれて残差のばらつきも大きくなる「ラッパー型(扇形)」のパターンが見られた。
(1) LINE のどの前提が崩れているか答えてください。 (2) この問題が存在する場合、最小二乗法の推定量への影響を説明してください。
解答を見る
(1) E(Equal variance:等分散性)の違反
分散が $x$ の値に応じて変化する不均一分散(heteroscedasticity)の状態です。
(2) 最小二乗法への影響
不均一分散が存在しても、最小二乗推定量 $\hat{\beta}_0$、$\hat{\beta}_1$ は不偏性を保ちます(Gauss-Markov 定理の等分散が崩れた場合)。
ただし、等分散性が成立しないと:
- 最小二乗推定量は最良線形不偏推定量(BLUE)ではなくなる(効率性を失う)
- 標準誤差の推定が偏り、t 検定・F 検定・信頼区間が不正確になる
対処法としては:
- 目的変数や説明変数に対数変換を施す
- 加重最小二乗法(WLS)を使用する
- ロバスト標準誤差(HC 標準誤差)を使用する
まとめ
| 概念 | 内容 |
|---|---|
| 分散分解 | TSS = RegSS + RSS |
| F 検定 | モデル全体の有意性。$F = \text{MSR}/\text{MSE}$ |
| $R^2$ の限界 | 変数を増やすと必ず上がる。単独での評価は不十分 |
| 回帰係数の信頼区間 | $\hat{\beta}_1 \pm t \cdot SE$。0を含まなければ有意 |
| 予測区間 > 信頼区間 | 個値の予測は平均の推定より不確かさが大きい |
| LINE | 線形性・独立性・正規性・等分散性の4前提 |
次の章では、複数の説明変数を扱う重回帰分析を学びます。調整済み $R^2$ と多重共線性が新たなテーマになります。