連続型確率分布:正規分布と標準化
Stage 3 — 第3章| 統計学基礎カリキュラム 推定学習時間:50〜60分 | 難易度:★★★☆☆
この章で学ぶこと
正規分布は統計学で最もよく使われる分布です。身長・体重・測定誤差・テストの点数など、現実の多くのデータが正規分布に近い形を示します。また、後の推定・検定の計算でも中心的に使います。
この章を終えると、こんなことができるようになります:
- 正規分布の確率密度関数の形と性質を説明できる
- 標準正規分布への変換($z$ 値)を計算できる
- 正規分布表を使って確率を求められる
- 二項分布の正規近似を適用できる
- なぜ多くのデータが正規分布に近くなるか(中心極限定理の入口)を説明できる
1. 正規分布の定義
関連教材(青の統計学)
1.1 確率密度関数
確率変数 $X$ が正規分布(Normal Distribution)に従うとき、$X \sim N(\mu, \sigma^2)$ と書き、確率密度関数は:
パラメータは2つ:
- $\mu$:平均(分布の中心)
- $\sigma^2$:分散(分布の広がり)
1.2 形状の特徴
正規分布の曲線には次の性質があります。
対称性: $x = \mu$ を軸として左右対称。そのため:
裾の広がりと $\sigma$ の関係:
これを68-95-99.7ルールと呼びます。例えば $\mu=170$cm、$\sigma=8$cm の身長分布なら、154〜186cmの範囲に95%以上が収まります。
$\sigma$ による形の違い:
$\sigma$ が小さいほど細く高い山型、$\sigma$ が大きいほど幅広く低い形になります。ただし曲線の下の面積(確率の総和)は常に1です。
[図1] パラメータの違いによる正規分布の形状
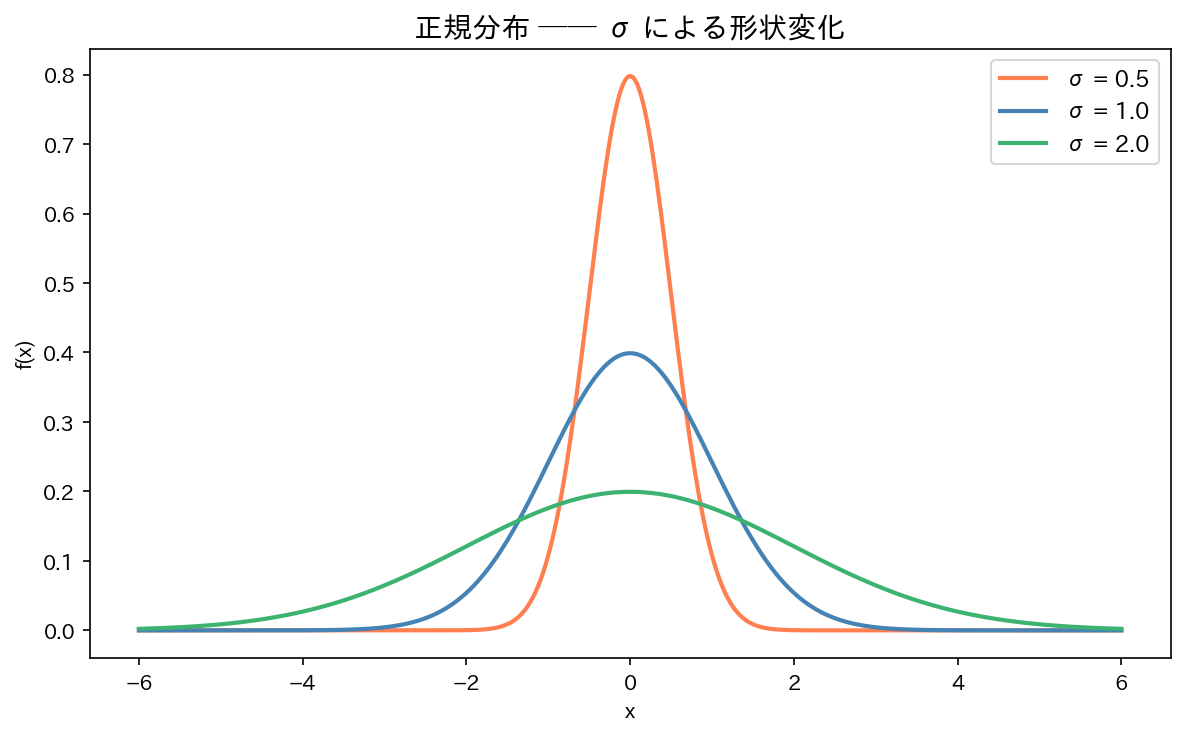
2. 標準正規分布
2.1 定義
$\mu = 0$、$\sigma^2 = 1$ の正規分布を標準正規分布と呼び、$Z \sim N(0, 1)$ と書きます。
2.2 標準化(z変換)
$X \sim N(\mu, \sigma^2)$ を標準正規分布に変換する操作:
この変換は前章(s3-p1)で学んだ標準化と同じです。$Z$ は「平均から何標準偏差分離れているか」を表す無次元の値で、$z$ 値($z$-score)とも呼びます。
なぜ標準化するか: 正規分布 $N(\mu, \sigma^2)$ の確率計算は $\mu$ と $\sigma$ の組み合わせごとに異なりますが、標準化すれば一種類の正規分布表(標準正規分布表)だけで $N(\mu, \sigma^2)$ の確率を全て求められます。
2.3 正規分布表の使い方
標準正規分布表は、$P(Z \leq z)$ の値(累積確率)を $z$ 値から引くための表です。
例) $Z \sim N(0,1)$ のとき、$P(Z \leq 1.96)$ を求める。
表から $z = 1.96$ の行と列を読む → $P(Z \leq 1.96) = 0.9750$
よく使う $z$ 値:
| $z$ | $P(Z \leq z)$ | よく使う場面 |
|---|---|---|
| 1.645 | 0.9500 | 片側5%点 |
| 1.960 | 0.9750 | 両側5%点(片側2.5%点) |
| 2.326 | 0.9900 | 片側1%点 |
| 2.576 | 0.9950 | 両側1%点(片側0.5%点) |
[図2] 標準正規分布と面積(確率)
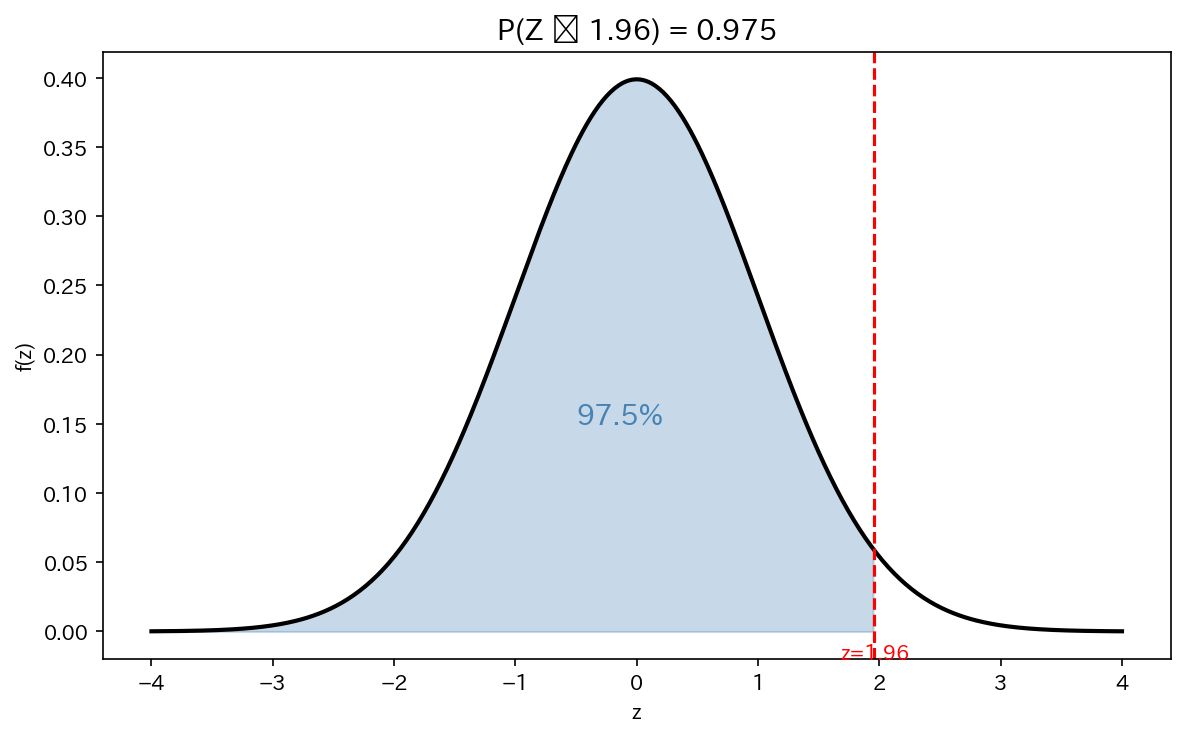
2.4 確率の計算パターン
正規分布の確率計算は3パターンに整理できます。
パターン①:$P(Z \leq a)$(表から直接読む)
パターン②:$P(Z \geq a)$(余事象)
パターン③:$P(a \leq Z \leq b)$(引き算)
対称性から $P(Z \leq -1.96) = 1 - P(Z \leq 1.96) = 0.0250$ を使うと:
これが「両側95%」の意味です。
📘 補足:正規分布表の種類
正規分布表にはいくつかの形式があります。
- 累積型:$P(Z \leq z)$ を表記(最も一般的)
- 上側確率型:$P(Z \geq z)$ を表記
- 0からzまでの面積型:$P(0 \leq Z \leq z)$ を表記
試験で提供される表がどの形式かを最初に確認することが重要です。形式が違っても、対称性($P(Z \leq -z) = P(Z \geq z) = 1 - P(Z \leq z)$)を使えばどれからでも他の値を求められます。
3. 一般の正規分布から確率を求める
$X \sim N(\mu, \sigma^2)$ の確率は、$z$ 変換で標準正規分布表を使います。
手順:
- $X$ の確率の範囲を $z$ 値に変換
- 標準正規分布表で確率を読む
例) 身長 $X \sim N(170, 8^2)$(cm)のとき、$P(166 \leq X \leq 178)$ を求める。
166〜178cmの人は全体の約53%です。
4. 二項分布の正規近似
関連教材(青の統計学)
$n$ が大きい二項分布は正規分布で近似できます。
目安: $np \geq 5$ かつ $n(1-p) \geq 5$ のとき近似が有効
連続修正(continuity correction): 離散型(二項)を連続型(正規)で近似するとき、精度を上げるために 0.5 の修正を加えます:
($Y$ は近似に使う正規分布)
例) コインを100回投げて表が60回以上出る確率($X \sim B(100, 0.5)$)。
連続修正を使うと $P(X \geq 60) \approx P(Y \geq 59.5)$:
📘 補足:なぜ正規分布が至るところに現れるか(中心極限定理の入口)
多くの現実データが正規分布に近い理由は、中心極限定理(CLT: Central Limit Theorem)で説明できます。
大雑把に言うと:「独立な多数の要因の足し算でできている量は、元の分布の形によらず正規分布に近づく」
例えば、身長は遺伝・栄養・運動・睡眠など無数の要因の足し算で決まるため、正規分布に近くなります。測定誤差も無数の微小な誤差の足し算です。
CLT の正確な定式化は次のステージ(推定・標本分布)で扱いますが、「多くのデータが正規分布に近い理由」としてここで押さえておいてください。
5. 演習問題
問題1(標準正規分布の確率計算)
$Z \sim N(0, 1)$ のとき、以下の確率を求めてください。
(1)$P(Z \leq 1.28)$ (2)$P(Z \geq 0.84)$ (3)$P(-1.65 \leq Z \leq 1.65)$
標準正規分布表:$P(Z \leq 0.84) = 0.7995$、$P(Z \leq 1.28) = 0.8997$、$P(Z \leq 1.65) = 0.9505$
💡 解答・解説を見る
(1)$P(Z \leq 1.28)$:
表から直接読む。
(2)$P(Z \geq 0.84)$:
余事象を使う。
(3)$P(-1.65 \leq Z \leq 1.65)$:
対称性から $P(Z \leq -1.65) = 1 - P(Z \leq 1.65) = 1 - 0.9505 = 0.0495$
両側を合わせると約90%の面積になります。$\pm 1.65\sigma$ の範囲に全体の90%が収まるという数値は、後の信頼区間(90%信頼区間)の計算でそのまま使います。
問題2(一般の正規分布)
ある製品の重量 $X$ は $N(500, 10^2)$(g)に従います。
(1)重量が490g以下になる確率を求めてください。 (2)重量が480g以上520g以下になる確率を求めてください。 (3)上位5%に入る重量の値(上側5%点)を求めてください。
標準正規分布表:$P(Z \leq 1.0) = 0.8413$、$P(Z \leq 1.645) = 0.9500$、$P(Z \leq 2.0) = 0.9772$
💡 解答・解説を見る
$\mu = 500$、$\sigma = 10$
(1)$P(X \leq 490)$:
(2)$P(480 \leq X \leq 520)$:
これは $\pm 2\sigma$ の範囲なので、68-95-99.7ルールの「95%」に対応します(より正確には95.44%)。
(3)上側5%点:
上位5%とは $P(X \geq x) = 0.05$、すなわち $P(X \leq x) = 0.95$ を満たす $x$ です。
$P(Z \leq 1.645) = 0.9500$ より $z = 1.645$
問題3(二項分布の正規近似)
ある工場の製品の良品率は80%です。500個製造したとき、良品数が410個以上になる確率を正規近似で求めてください(連続修正を適用)。
$P(Z \leq 1.12) = 0.8686$、$P(Z \leq 1.23) = 0.8907$ を使ってよい。
💡 解答・解説を見る
$X \sim B(500, 0.8)$正規近似のパラメータ:
$np = 400 \geq 5$、$n(1-p) = 100 \geq 5$ なので近似有効。
連続修正を適用:
$z = 1.06$ が表にない場合、1.12 と 1.23 の間の値として補間するか、近い値を使います。ここでは $z \approx 1.06$ として:
実際には $P(Z \leq 1.06) \approx 0.8554$ を使うと:
連続修正なしで計算した場合($z = (410-400)/8.944 \approx 1.118$)と比較すると、連続修正によって $z$ が小さくなり(確率が大きくなる)、離散→連続の近似誤差が補正されることがわかります。
まとめ
| 項目 | 内容 |
|---|---|
| 正規分布 | $N(\mu, \sigma^2)$、左右対称の釣り鐘型 |
| 68-95-99.7ルール | $\pm 1\sigma$:68%、$\pm 2\sigma$:95%、$\pm 3\sigma$:99.7% |
| 標準正規分布 | $N(0,1)$、$z=(X-\mu)/\sigma$ で変換 |
| 確率計算の3パターン | $P(Z \leq a)$(表)、$P(Z \geq a)$(余事象)、$P(a \leq Z \leq b)$(引き算) |
| 二項分布の正規近似 | $np \geq 5$ かつ $n(1-p) \geq 5$ のとき。連続修正で精度向上 |
| CLT(入口) | 独立な多数の要因の和が正規分布に近づく理由 |
Stage 3 を終えて: 確率変数・期待値・分散という基礎の上に、二項分布・ポアソン分布・正規分布という3つの重要な分布を学びました。次のステージでは、これらの分布を使って「データから母集団を推論する」推定と検定に進みます。
次のステージへ
→ Stage 4へ:推定と検定 — データから母集団を語る