標本分布と中心極限定理
Stage 4 — 第1章| 統計学基礎カリキュラム 推定学習時間:50〜60分 | 難易度:★★★★☆
この章で学ぶこと
Stage 3 まで「1つの確率変数がどんな分布に従うか」を学びました。 ここからは「データから母集団を語る」推測統計に入ります。
その出発点となるのが標本分布です。「標本から計算した統計量(例:標本平均)も、それ自体が確率変数であり、固有の分布を持つ」という考え方です。
この章を終えると、こんなことができるようになります:
- 標本平均の期待値・分散・標準誤差を求められる
- 中心極限定理(CLT)の内容と意味を説明できる
- 大数の法則と CLT の違いを説明できる
- CLT を使って標本平均に関する確率を計算できる
- 標準誤差と標準偏差の違いを明確に説明できる
1. 統計量もランダムである
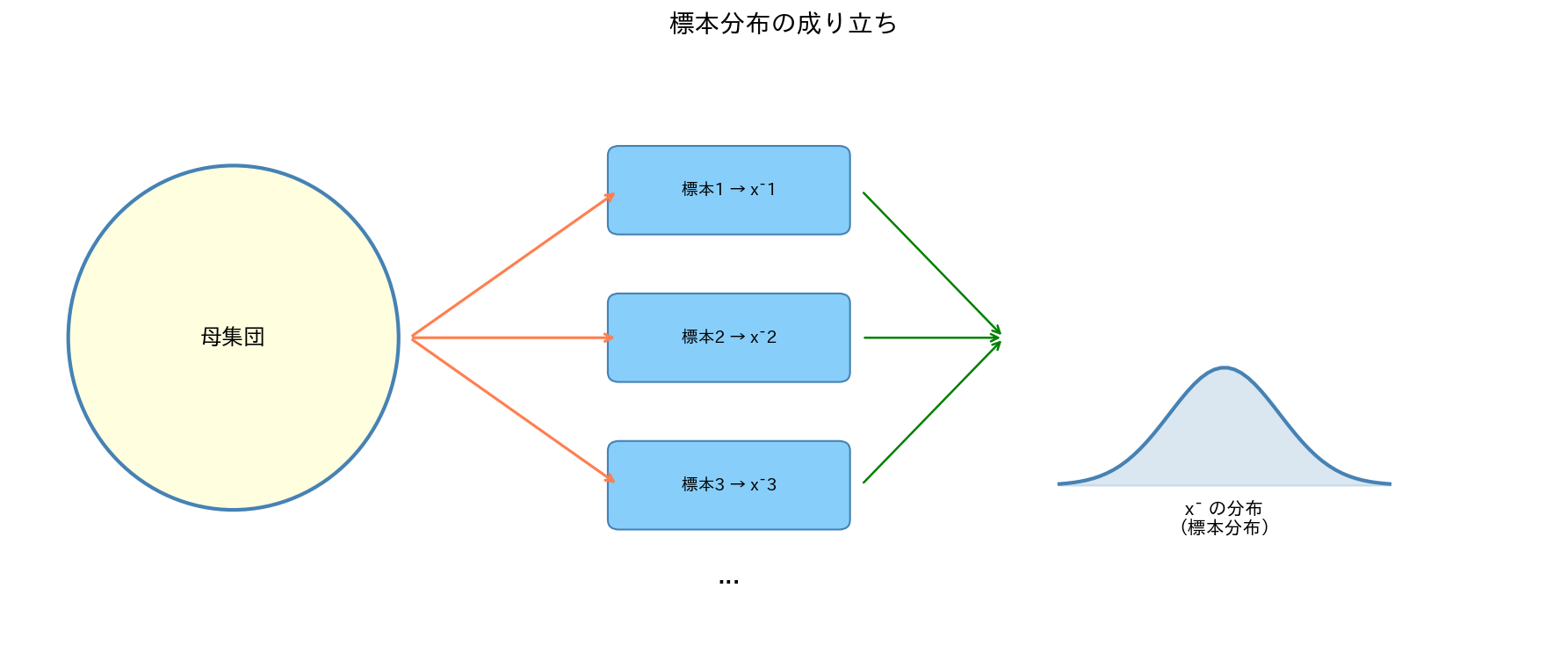
母集団から標本を抽出するたびに、計算される平均値は変わります。
例) 日本人成人男性の身長(母平均 $\mu = 171$ cm)から10人ずつ無作為抽出を繰り返すと:
- 1回目の標本平均:169.3 cm
- 2回目の標本平均:172.1 cm
- 3回目の標本平均:170.8 cm
- …
この標本平均 $\bar{X}$ 自体が確率変数です。そして確率変数である以上、分布・期待値・分散が定義できます。これを標本分布(sampling distribution)といいます。
[図1] 標本を繰り返し取るイメージ
2. 標本平均の期待値と分散
関連教材(青の統計学)
母集団の平均を $\mu$、分散を $\sigma^2$ とします。この母集団から大きさ $n$ の標本を無作為抽出したとき、標本平均 $\bar{X} = \frac{1}{n}\sum_{i=1}^n X_i$ について次が成り立ちます。
$SE$(Standard Error)を標準誤差と呼びます。
導出
$X_1, X_2, \ldots, X_n$ は互いに独立で、同じ母集団から引かれているので:
標準偏差 vs 標準誤差
混同しやすいので明確に区別します:
| 標準偏差(SD) | 標準誤差(SE) | |
|---|---|---|
| 対象 | 個々のデータの散らばり | 標本平均の散らばり |
| 式 | $\sigma$ | $\sigma / \sqrt{n}$ |
| $n$ を増やすと | 変わらない | 小さくなる(推定精度が上がる) |
| 意味 | 個人差の大きさ | 標本平均の信頼性の指標 |
例) 身長の標準偏差 $\sigma = 6$ cm、標本サイズ $n = 36$ のとき:
36人の平均身長は、1cm 程度の誤差範囲で推定できることを意味します。
3. 大数の法則
大数の法則(Law of Large Numbers, LLN):
$n \to \infty$ のとき、標本平均 $\bar{X}$ は母平均 $\mu$ に(確率的に)収束する。
これは $V[\bar{X}] = \sigma^2 / n \to 0$($n$ が増えるにつれて標本平均のばらつきがゼロに近づく)から直感的に理解できます。
日常の例:
- コインを100回投げれば、表の割合は0.5に近い
- コインを1万回投げれば、さらに0.5に近い
- 大規模な世論調査ほど、真の支持率に近くなる
注意: 大数の法則は「$n$ が大きければ標本平均が $\mu$ に近い値をとる」という話です。「分布の形」については何も言っていません。それを言うのが次の中心極限定理です。
4. 中心極限定理(Central Limit Theorem, CLT)
関連教材(青の統計学)
4.1 定理の内容
中心極限定理:
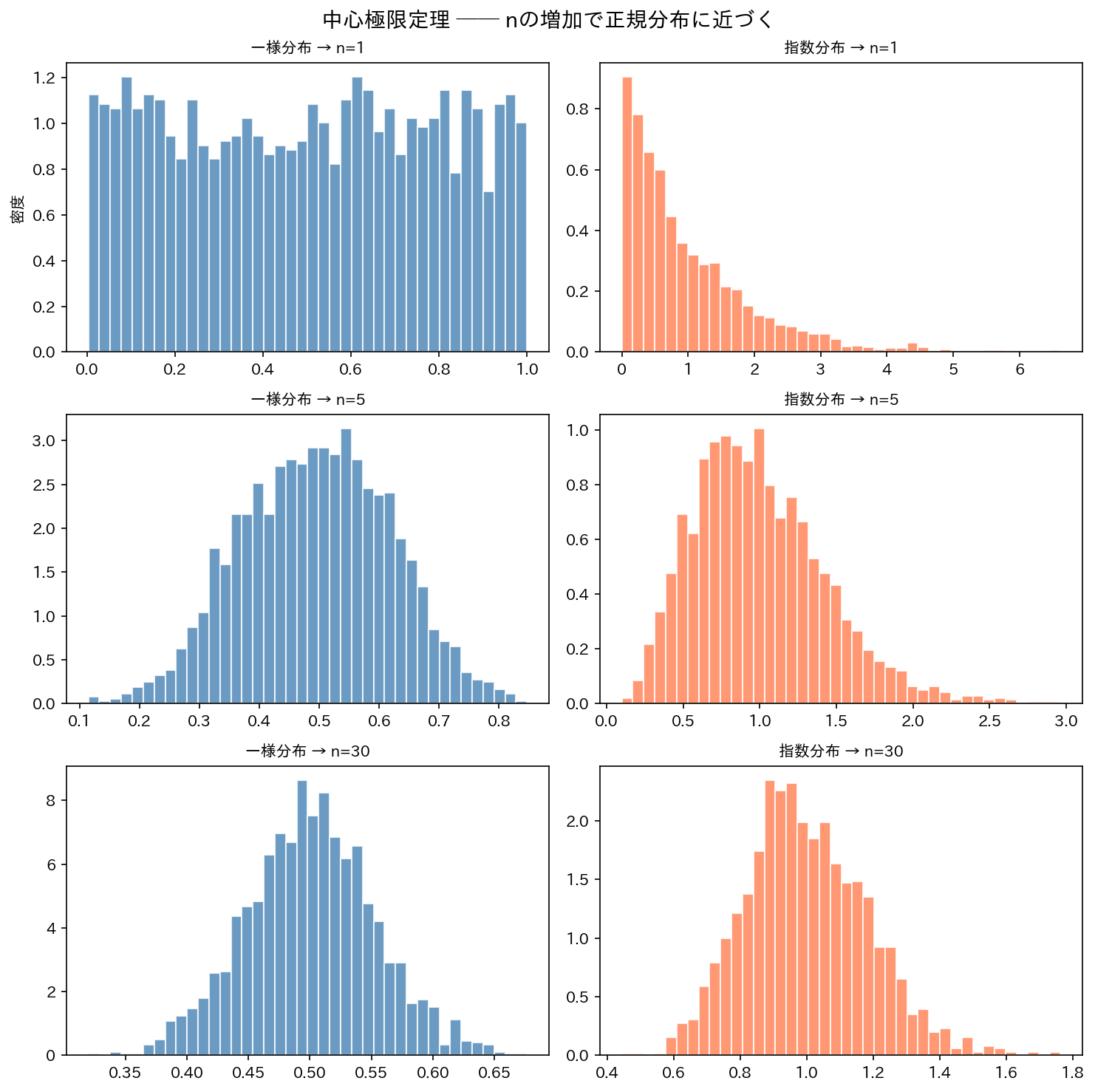
母集団の分布の形によらず、標本サイズ $n$ が十分大きいとき、標本平均 $\bar{X}$ の分布は近似的に正規分布に従う:
標準化すると:
「十分大きい」の目安: $n \geq 30$ が一般的な目安。ただし元の分布が正規分布に近ければ小さい $n$ でも成立し、大きく歪んでいれば $n \geq 50$ 以上が必要なこともあります。
[図2] 中心極限定理のイメージ
4.2 CLT がなぜ重要か
CLT が重要な理由は2つです。
①推定・検定の計算基盤になる: 後の章で学ぶ信頼区間・仮説検定の計算は、「標本平均が正規分布に従う」という仮定の上に成り立っています。CLT があるから、元の母集団の分布を知らなくても推測ができます。
②現実データへの適用を正当化する: 身長・体重・気温・製品の寸法など、「独立した多数の要因の足し算」で決まる量は、元の分布によらず正規分布に近くなります。CLT はこの現象の数学的な説明です。
4.3 大数の法則と CLT の違い
| 大数の法則 | 中心極限定理 | |
|---|---|---|
| 何を言うか | $\bar{X}$ が $\mu$ に収束する | $\bar{X}$ の分布が正規分布に近づく |
| $n$ の扱い | $n \to \infty$ の極限 | 有限の $n$($\geq 30$ 程度)でも成立 |
| 形の情報 | なし | 分布の「形」を正規分布で近似できる |
📘 補足:CLT の厳密な仮定
一般的な CLT(Lindeberg-Lévy の定理)の仮定は:
- $X_1, X_2, \ldots$ が独立同分布(i.i.d.)
- 母集団の平均 $\mu$ と分散 $\sigma^2$ が有限に存在する
分散が存在しない分布(例:コーシー分布)では CLT は成立しません。 また独立性が崩れる時系列データ(株価など)には修正版の定理が必要です。 実務では「独立かつ有限分散」の確認がデータ分析の前提チェックとなります。
5. CLT を使った確率計算
CLT を使えば、母集団の分布形がわからなくても標本平均に関する確率を正規分布で近似計算できます。
例) ある工場の部品の重量は、平均 $\mu = 50$ g、標準偏差 $\sigma = 8$ g(分布の形は不明)。 25個を無作為に取り出したとき、標本平均が 48 g 以上 52 g 以下になる確率を求めよ。
$n = 25 \geq 30$ に少し足りないですが近似として使います:
標準化:
標本平均が 48〜52g の範囲に収まる確率は約79%です。
6. 演習問題
問題1(標準誤差の計算)
母集団の標準偏差が $\sigma = 12$ のとき、標本サイズを以下に設定した場合の標準誤差を求めてください。
(1)$n = 4$ (2)$n = 36$ (3)$n = 144$
また、$n$ を4倍にするたびに標準誤差はどう変化するか答えてください。
💡 解答・解説を見る
(1)$n = 4$:
(2)$n = 36$:
(3)$n = 144$:
$n$ を4倍にするたびの変化:
$n$ を4倍にすると $SE$ は $\frac{1}{\sqrt{4}} = \frac{1}{2}$ 倍(半分)になります。 標準誤差を半分にするには標本サイズを4倍にする必要があります。精度向上のコストが大きいことがわかります。
問題2(大数の法則の確認)
サイコロを $n$ 回振るとき、目の平均値(標本平均)の標準誤差を求めてください。 サイコロの目の分布では $\mu = 3.5$、$\sigma^2 = 35/12 \approx 2.917$ です。
(1)$n = 10$ のときの標準誤差 (2)$n = 100$ のときの標準誤差 (3)$n = 1000$ のときの標準誤差を求め、大数の法則を数値で確認してください。
💡 解答・解説を見る
$\sigma = \sqrt{35/12} \approx 1.708$(1)$n = 10$:
(2)$n = 100$:
(3)$n = 1000$:
大数の法則の確認:
$n = 1000$ では標準誤差が 0.054 まで小さくなります。$\bar{X}$ は $\mu = 3.5 \pm 0.054$ 程度の範囲に高確率で収まり、真の平均3.5にきわめて近い値をとることがわかります。$n$ を大きくするほど $SE \to 0$、つまり $\bar{X} \to \mu$ になります。これが大数の法則の数値的な確認です。
問題3(CLT による確率計算)
ある製品の1個あたりの利益は、平均 $\mu = 800$ 円、標準偏差 $\sigma = 200$ 円の分布に従うとします(分布の形は不問)。
(1)この製品を100個販売したとき、1個あたりの平均利益が 780 円以上になる確率を求めてください。 (2)平均利益が 760 円以上 840 円以下になる確率を求めてください。 (3)標本サイズを $n = 400$ に増やしたとき、(1)の確率はどう変わるか求めてください。
$P(Z \leq 1.0) = 0.8413$、$P(Z \leq 2.0) = 0.9772$ を使ってよい。
💡 解答・解説を見る
$n = 100 \geq 30$ なので CLT を適用。
(1)$P(\bar{X} \geq 780)$:
(2)$P(760 \leq \bar{X} \leq 840)$:
(3)$n = 400$ のとき $P(\bar{X} \geq 780)$:
$n$ を4倍(100→400)にすることで、$SE$ が半分(20→10)になり、確率が84.1%から97.7%に大幅に上がりました。標本サイズを増やすことで、推定の精度(信頼性)が向上することが数値で確認できます。
まとめ
| 概念 | 内容 |
|---|---|
| 標本分布 | 統計量(標本平均など)が従う確率分布 |
| 標本平均の期待値 | $E[\bar{X}] = \mu$(不偏性) |
| 標本平均の分散 | $V[\bar{X}] = \sigma^2/n$ |
| 標準誤差 | $SE = \sigma/\sqrt{n}$($n$ を大きくすると小さくなる) |
| 大数の法則 | $n \to \infty$ で $\bar{X} \to \mu$ |
| 中心極限定理 | 元の分布によらず、$n$ が大きければ $\bar{X} \approx N(\mu, \sigma^2/n)$ |
この章のポイント: 標準誤差と標準偏差を混同しないことが重要です。標準偏差はデータの散らばりで $n$ に無関係、標準誤差は標本平均の精度で $n$ が大きいほど小さくなります。
次の章へ
標本平均の分布がわかれば、そこから「母平均の推定」ができます。次章では区間推定と信頼区間を学びます。
→ 次: 点推定と区間推定