第5章:最尤推定と推定量の性質
Stage 5:回帰・分散分析・応用
この章で学ぶこと
前章のロジスティック回帰で「最尤推定(MLE)で係数を推定する」と述べました。この章では MLE の考え方を体系的に学びます。
MLE は統計学の推定手法の中で最も広く使われているものの一つで、正規分布・二項分布・ポアソン分布・ロジスティック回帰など、多くのモデルの推定基盤になっています。
また、Stage 4 で扱った推定量の性質(不偏性・一致性・有効性)を MLE の文脈で改めて整理します。
1. 尤度とは何か
関連教材(青の統計学)
考え方の逆転
通常の確率計算:「パラメータが既知のとき、データが得られる確率は?」
最尤推定の視点:「データが与えられたとき、それを最もよく説明するパラメータは何か?」
尤度(likelihood)
観測データ $x_1, x_2, \ldots, x_n$ が得られたとき、パラメータ $\theta$ の関数として確率(密度)を見たものを尤度関数と言います。
(データが互いに独立の場合、同時確率は各確率の積になります)
重要な視点の転換:$L(\theta)$ はデータを固定してパラメータ $\theta$ を動かす関数です。「このデータが得られる確率が最も高くなるような $\theta$ はどれか」を探します。
2. 尤度関数と対数尤度
積から和へ
$n$ 個のデータの積を直接最大化するのは計算が大変です(積は微分が複雑)。そこで対数をとります。
対数尤度(log-likelihood):
対数は単調増加関数なので、$L(\theta)$ を最大化する $\theta$ と $\ell(\theta)$ を最大化する $\theta$ は一致します。
最大尤度推定量(MLE)
対数尤度を $\theta$ で微分して 0 とおいた方程式(尤度方程式)を解きます:
3. MLE の計算例
例1:コイン投げ(二項分布)
コインを $n = 10$ 回投げて表が $k = 7$ 回出た。表の確率 $p$ の MLE を求めよ。
尤度関数(二項係数は $p$ に依存しないので省略可):
対数尤度:
微分して 0 とおく:
MLE:$\hat{p} = 7/10 = 0.7$(観測された表の割合、つまり標本比率が MLE です)
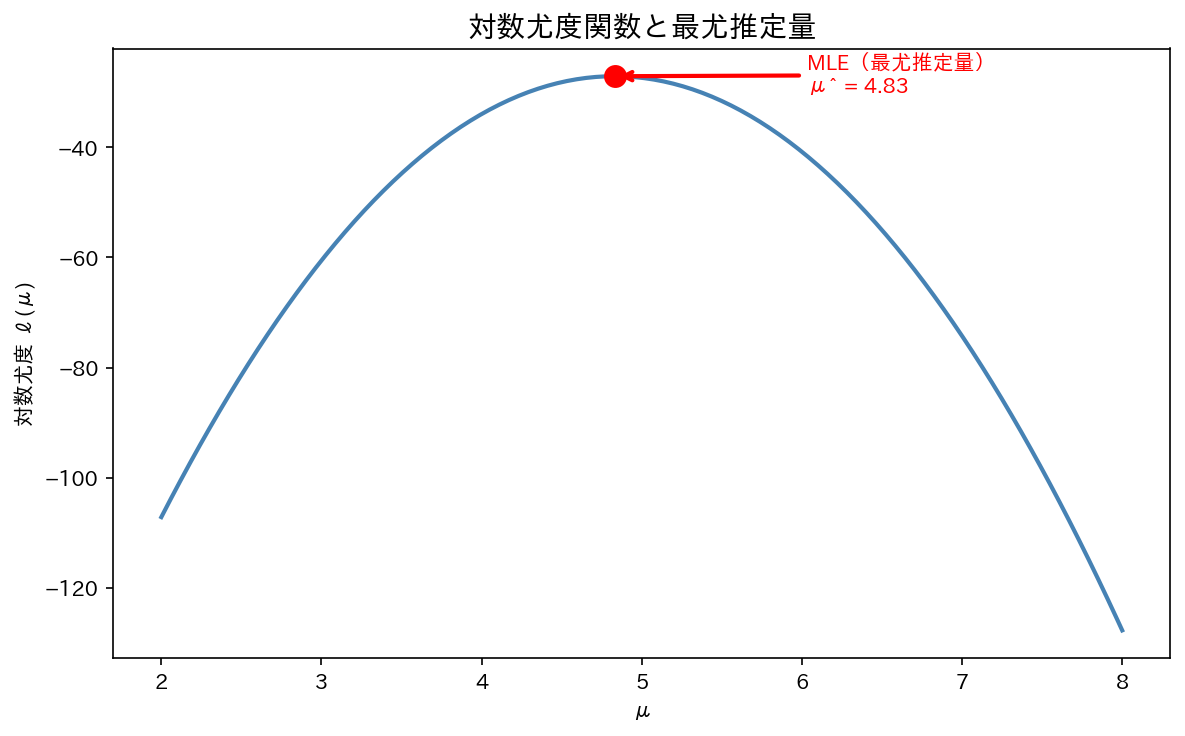
例2:正規分布の MLE
$x_1, \ldots, x_n$ が $N(\mu, \sigma^2)$ に従うとき、$\mu$ と $\sigma^2$ の MLE を求めよ。
対数尤度:
$\mu$ の MLE($\partial \ell / \partial \mu = 0$):
$\sigma^2$ の MLE($\partial \ell / \partial \sigma^2 = 0$):
注意:MLE の分散推定量は $n$ で割ります(不偏分散は $n-1$ で割る)。MLE は不偏ではない点に注意してください(詳しくは次節)。
4. 推定量の性質
関連教材(青の統計学)
Stage 4 で学んだ推定量の性質を MLE の文脈で整理します。
不偏性(Unbiasedness)
推定量の期待値が真のパラメータと一致する性質です。
- 標本平均 $\bar{x}$ は $\mu$ の不偏推定量
- 不偏分散 $s^2 = \frac{1}{n-1}\sum(x_i-\bar{x})^2$ は $\sigma^2$ の不偏推定量
- MLE の $\hat{\sigma}^2_{\text{MLE}} = \frac{1}{n}\sum(x_i-\bar{x})^2$ は $\sigma^2$ の不偏推定量ではない(少し過小推定する)
一致性(Consistency)
$n$ が増えるほど推定値が真の値に近づく性質です。MLE は一般に一致推定量です。
有効性(Efficiency)
同じクラスの不偏推定量の中で分散が最小である性質です。
クラメール-ラオの下限(Cramér-Rao lower bound):
ここで $I(\theta)$ はフィッシャー情報量(Fisher information)です:
クラメール-ラオの下限に等しい分散を持つ推定量を有効推定量(efficient estimator)と言います。
漸近正規性(Asymptotic Normality)
MLE の大きな性質として、$n$ が大きいとき:
標本サイズが大きければ MLE が正規分布に近似できることを意味します。これが MLE の Wald 検定や信頼区間の基礎になっています。
5. MLE の良い性質まとめ
MLE が広く使われる理由は以下の理論的な性質にあります。
一致性
$n \to \infty$ で MLE は真のパラメータに確率収束します。
漸近有効性
$n$ が大きいとき、MLE はクラメール-ラオの下限を達成します。つまり、漸近的には最も分散が小さい推定量です。
不変性(Invariance property)
$\hat{\theta}$ が $\theta$ の MLE なら、$g(\hat{\theta})$ は $g(\theta)$ の MLE です。
例:$\hat{p} = 0.7$ が $p$ の MLE なら、オッズ $p/(1-p)$ の MLE は $0.7/0.3 = 7/3$ です。
6. MLE と最小二乗法の関係
正規分布の誤差 $\varepsilon \sim N(0, \sigma^2)$ を仮定した線形回帰モデルにおいて、最尤推定と最小二乗法は同じ回帰係数の推定値を与えます。
最小二乗法は「残差の2乗和を最小化」し、MLE は「正規分布の対数尤度を最大化」しますが、どちらも同じ方程式に帰着します。
正規誤差の仮定のもとでは:
これを最大化することは $\sum(y_i - \hat{y}_i)^2$ を最小化することと同等です。
演習問題
問題1
サイコロを $n = 30$ 回振り、1の目が $k = 4$ 回出た。1の目が出る確率 $p$ の MLE を求めてください。また、$p = 1/6$ という「公正なサイコロ」の仮説は尤もらしいか考察してください。
解答を見る
MLE の計算:
二項分布に従うため、例1と同じ手順で:
考察:
公正なサイコロなら $p_0 = 1/6 \approx 0.167$ のはずです。MLE $\hat{p} = 0.133$ は $p_0 = 0.167$ より小さい値ですが、これが偶然かどうかを判断するには仮説検定が必要です。
二項比率の検定($H_0: p = 1/6$)を行うと:
$|z| = 0.50 < 1.96$ なので有意水準5%では棄却できません。観測された差は偶然の範囲内です。
問題2
指数分布 $f(x \mid \lambda) = \lambda e^{-\lambda x}$($x > 0$)に従う $n$ 個の独立な観測値 $x_1, \ldots, x_n$ が得られた。$\lambda$ の MLE を求めてください。
解答を見る
対数尤度:
尤度方程式:
MLE:$\hat{\lambda}_{\text{MLE}} = 1/\bar{x}$(標本平均の逆数)
不変性より、平均 $\mu = 1/\lambda$ の MLE は $\hat{\mu} = \bar{x}$ です。
問題3
次の推定量について、不偏性があるかどうかを答えてください。
(1) 母平均 $\mu$ の推定量として $\bar{x} = \frac{1}{n}\sum x_i$
(2) 母分散 $\sigma^2$ の MLE として $\hat{\sigma}^2_{\text{MLE}} = \frac{1}{n}\sum(x_i - \bar{x})^2$
(3) 母分散 $\sigma^2$ の推定量として $s^2 = \frac{1}{n-1}\sum(x_i - \bar{x})^2$
解答を見る
(1) $\bar{x}$:不偏
(2) $\hat{\sigma}^2_{\text{MLE}}$:不偏でない(過小推定)
真の値 $\sigma^2$ より小さく推定されます。これが MLE の分散推定量が不偏でない理由です。
(3) $s^2$:不偏
$n-1$ で割ることでバイアスが補正されます。この補正が「不偏分散」と呼ばれる理由です(Stage 1 で学んだ内容の確認)。
まとめ
| 概念 | 内容 |
|---|---|
| 尤度関数 $L(\theta)$ | データを固定し、$\theta$ の関数として確率を見る |
| 対数尤度 $\ell(\theta)$ | 積 → 和。微分しやすく数値的に安定 |
| MLE | $\ell(\theta)$ を最大化するパラメータの推定法 |
| 不偏性 | $E[\hat{\theta}] = \theta$。MLE の分散推定量は不偏でない |
| 一致性 | $n \to \infty$ で真値に収束。MLE は満たす |
| 漸近有効性 | $n$ が大きいとき MLE は最小分散を達成 |
| 不変性 | $g(\hat{\theta})$ は $g(\theta)$ の MLE |
次の章では、3グループ以上の平均を同時に比較する分散分析(ANOVA)を学びます。これがカリキュラム全体の最終章です。