点推定と区間推定
Stage 4 — 第2章| 統計学基礎カリキュラム 推定学習時間:50〜60分 | 難易度:★★★★☆
この章で学ぶこと
標本から母集団のパラメータ(母平均・母比率など)を推定する方法を学びます。 推定には「1つの値で答える」点推定と「幅で答える」区間推定の2種類があります。
この章を終えると、こんなことができるようになります:
- 点推定量の望ましい性質(不偏性・一致性)を説明できる
- 信頼区間の正しい意味を説明できる(よくある誤解を避けられる)
- 母平均の信頼区間を $\sigma$ 既知・未知の両方で計算できる
- 母比率の信頼区間を計算できる
- 標本サイズと信頼区間の幅の関係を説明できる
1. 点推定
1.1 推定量と推定値
母集団のパラメータ $\theta$(母平均 $\mu$、母分散 $\sigma^2$ など)を、標本から計算した1つの値で推定することを点推定(point estimation)といいます。
- 推定量(estimator):推定のために使う統計量(確率変数)。例:$\bar{X}$
- 推定値(estimate):実際のデータから計算した具体的な値。例:$\bar{x} = 172.3$
同じ推定量でも、取り出す標本によって推定値は変わります。
1.2 よい推定量の性質
すべての推定量が同じように「よい」わけではありません。代表的な基準を2つ示します。
不偏性(Unbiasedness):
推定量の期待値が真のパラメータと一致する性質。「平均的に当たっている」。
標本平均 $\bar{X}$ は母平均 $\mu$ の不偏推定量です(前章で確認済み)。 標本分散 $s^2 = \frac{1}{n-1}\sum(X_i - \bar{X})^2$ は母分散 $\sigma^2$ の不偏推定量です($n-1$ で割る理由)。
一致性(Consistency):
標本サイズを大きくするほど、推定量が真の値に近づく性質。大数の法則により $\bar{X}$ は一致性を持ちます。
📘 補足:有効性(Efficiency)
同じパラメータの不偏推定量が複数ある場合、分散が最小のものが最も「効率よい」推定量です。
例えば、母平均の不偏推定量として標本平均 $\bar{X}$ と標本中央値 $\tilde{X}$ の両方が使えますが、正規母集団では $\bar{X}$ のほうが分散が小さく、より有効な推定量です。
「不偏かつ分散最小」の推定量をUMVUE(Uniformly Minimum Variance Unbiased Estimator)と呼び、推定理論の目標の一つです。
2. 区間推定と信頼区間
関連教材(青の統計学)
2.1 なぜ区間で推定するか
点推定は1つの値を与えますが、「どれくらい信頼できるか」という情報がありません。 区間推定では「真の値がこの幅の中に入っている」という区間を提示します。
信頼区間(Confidence Interval, CI):
信頼係数(信頼水準)$1 - \alpha$(例:95%)で、真のパラメータ $\theta$ が含まれると期待される区間。
2.2 信頼区間の正しい解釈
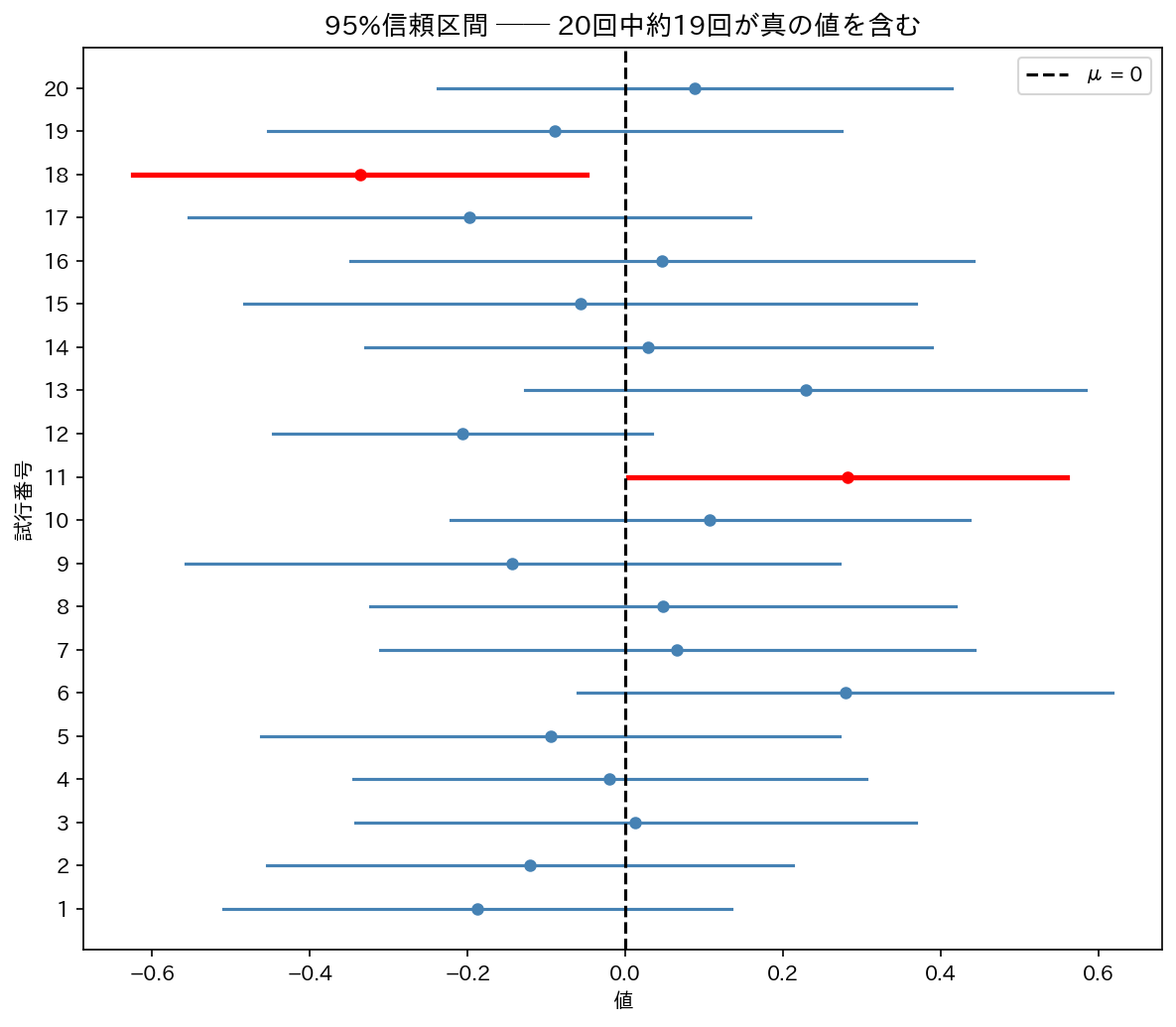
よくある誤解:「95%信頼区間とは、真の値が95%の確率でこの区間に入っている」
正しい解釈: 真の $\mu$(母平均)は固定した値であって、確率的に動くものではありません。「95%信頼区間」とは、「同じ手順で標本を取り直して区間を100回作ると、そのうち約95回が真の $\mu$ を含む」という意味です。
特定の1つの区間について「真の値が95%の確率でここに入る」とは言えません。特定の区間は真の値を含むか含まないかのどちらかです。
[図1] 信頼区間の意味
3. 母平均の区間推定($\sigma$ 既知)
母標準偏差 $\sigma$ が既知のとき、CLT より:
信頼係数 $1 - \alpha$ の信頼区間を求めます。上側 $\alpha/2$ 点を $z_{\alpha/2}$ とすると:
変形すると:
よく使う $z_{\alpha/2}$ の値:
| 信頼係数 | $\alpha$ | $z_{\alpha/2}$ |
|---|---|---|
| 90% | 0.10 | 1.645 |
| 95% | 0.05 | 1.960 |
| 99% | 0.01 | 2.576 |
区間の幅: $2 \times z_{\alpha/2} \times \frac{\sigma}{\sqrt{n}}$
幅を狭くしたい(精度を上げたい)なら:
- $n$ を大きくする(幅 $\propto 1/\sqrt{n}$)
- 信頼係数を下げる(95% → 90%)
例) ある地域の成人女性の身長を調査。母標準偏差 $\sigma = 5.5$ cm が既知。 $n = 49$ 人を無作為抽出し、標本平均 $\bar{x} = 158.3$ cm を得た。 母平均 $\mu$ の 95% 信頼区間を求めよ。
4. 母平均の区間推定($\sigma$ 未知)
実際には母標準偏差 $\sigma$ が未知の場合がほとんどです。この場合、$\sigma$ を標本標準偏差 $s = \sqrt{\frac{1}{n-1}\sum(X_i - \bar{X})^2}$ で置き換えます。
ただし $\sigma$ を $s$ で置き換えると、統計量は正規分布ではなく$t$ 分布(Student の $t$ 分布)に従います:
$t(n-1)$ は自由度 $n-1$ の $t$ 分布です。
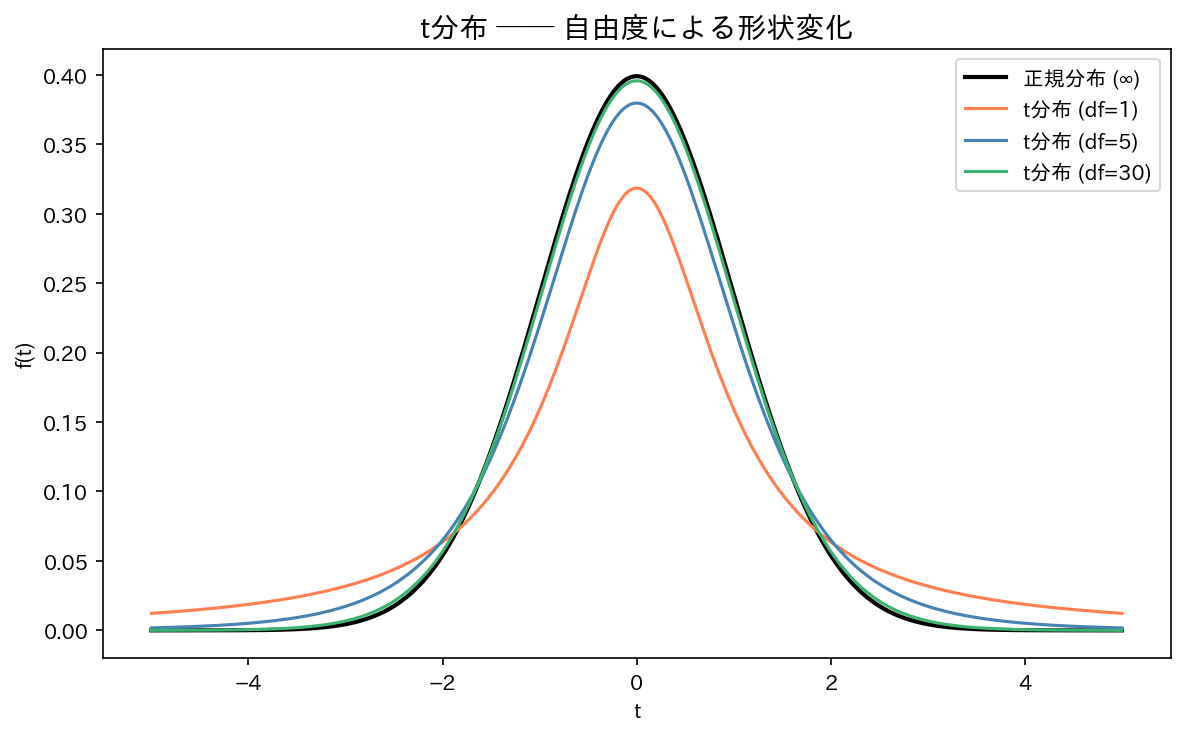
$t$ 分布の特徴
- 標準正規分布と同様に左右対称・釣り鐘型
- 正規分布より裾が重い(外れた値が出やすい)
- 自由度が大きくなると正規分布に近づく($n \geq 30$ 程度で実用上ほぼ同じ)
[図2] t分布と正規分布の比較
$t$ 分布を使った信頼区間:
$t_{\alpha/2}(n-1)$:自由度 $n-1$ の $t$ 分布の上側 $\alpha/2$ 点($t$ 表から引く)
例) $n = 16$ のとき $t_{0.025}(15) = 2.131$($n = 30$ のとき $t_{0.025}(29) = 2.045$、正規近似の $1.960$ に近づく)
例) 新しい教授法の効果を検証するため、16人の生徒にテストを実施。 標本平均 $\bar{x} = 75.4$ 点、標本標準偏差 $s = 8.0$ 点。 母平均の 95% 信頼区間を求めよ($t_{0.025}(15) = 2.131$)。
5. 母比率の区間推定
関連教材(青の統計学)
「支持率」「不良品率」「回答率」など、割合(比率)を推定したい場合です。
標本比率 $\hat{p} = X/n$($X$:対象の個数)は、$n$ が大きいとき CLT より:
$p$ が未知なので $\hat{p}$ で代替して標準化:
母比率の信頼区間:
近似が有効な条件: $n\hat{p} \geq 5$ かつ $n(1-\hat{p}) \geq 5$
例) 1000人への調査で480人が賛成。賛成率の 95% 信頼区間を求めよ。
📘 補足:信頼区間の幅と必要標本サイズ
母比率の信頼区間の幅は $2 \times z_{\alpha/2} \sqrt{\hat{p}(1-\hat{p})/n}$ です。 必要な精度(半幅 $e$)と信頼係数 $1-\alpha$ を決めると、必要標本サイズを逆算できます:
\[ n \geq \left(\frac{z_{\alpha/2}}{e}\right)^2 \hat{p}(1-\hat{p}) \]$\hat{p}$ が不明なら最も保守的な $\hat{p} = 0.5$(分散最大)を使います:
\[ n \geq \left(\frac{z_{\alpha/2}}{e}\right)^2 \times 0.25 \]例)95%信頼区間の半幅を3%以内にしたい:
\[ n \geq \left(\frac{1.960}{0.03}\right)^2 \times 0.25 = (65.3)^2 \times 0.25 \approx 1067 \text{ 人} \]世論調査で「1000〜1200人」というサンプルサイズがよく使われる理由がこれです。
6. 演習問題
問題1(母平均の区間推定・$\sigma$ 既知)
ある自動販売機が注ぐコーヒーの量は、標準偏差 $\sigma = 3$ ml で安定しています。 36杯を無作為に抽出したところ、平均が 148.2 ml でした。
(1)母平均の 95% 信頼区間を求めてください。 (2)99% 信頼区間を求めてください。 (3)95% 信頼区間の幅を 1.5 ml 以内にするには、最低何杯サンプリングする必要がありますか?
💡 解答・解説を見る
$\bar{x} = 148.2$、$\sigma = 3$、$n = 36$
(1)95%信頼区間($z_{0.025} = 1.960$):
(2)99%信頼区間($z_{0.005} = 2.576$):
信頼係数を上げると(95%→99%)区間が広がることを確認できます。
(3)必要な標本サイズ:
半幅 $e = 1.5/2 = 0.75$ ml 以内にしたい:
最低62杯のサンプリングが必要です。
問題2(母平均の区間推定・$\sigma$ 未知)
新薬の投与後、9人の患者の血圧低下値(mmHg)を測定したところ:
母平均の 95% 信頼区間を求めてください($t_{0.025}(8) = 2.306$)。
💡 解答・解説を見る
まず標本平均と標本標準偏差を計算します。
各偏差の2乗:
| $x_i$ | $x_i - \bar{x}$ | $(x_i - \bar{x})^2$ |
|---|---|---|
| 10 | −0.67 | 0.449 |
| 8 | −2.67 | 7.129 |
| 15 | 4.33 | 18.749 |
| 12 | 1.33 | 1.769 |
| 9 | −1.67 | 2.789 |
| 11 | 0.33 | 0.109 |
| 7 | −3.67 | 13.469 |
| 13 | 2.33 | 5.429 |
| 11 | 0.33 | 0.109 |
| 合計 | 50.001 |
95%信頼区間は [8.75, 12.59] mmHg。区間が0を含まないので、この薬は血圧を下げる効果がある可能性が高いといえます(次章の仮説検定で正式に検証します)。
問題3(母比率の区間推定)
ある市でオンライン投票システムへの賛成率を調査しました。 500人のうち 310 人が賛成と回答しました。
(1)賛成率の 95% 信頼区間を求めてください。 (2)信頼区間が「賛成多数(50%超)」を支持しているか判断してください。 (3)半幅を 2% 以内にするには何人必要ですか?
💡 解答・解説を見る
(1)95%信頼区間:
近似条件確認:$500 \times 0.62 = 310 \geq 5$、$500 \times 0.38 = 190 \geq 5$ ✓
(2)賛成多数の判断:
信頼区間の下限が 57.8% > 50% であるため、区間全体が50%を超えています。 賛成多数(50%超)を95%の信頼水準で支持しています。
(3)半幅 2%(= 0.02)以内の必要標本サイズ:
最低2263人が必要です。精度を2倍(4%→2%)にするには標本サイズを約4.5倍に増やす必要があることがわかります($n \propto 1/e^2$)。
まとめ
| 項目 | 内容 |
|---|---|
| 点推定 | 1つの値でパラメータを推定。不偏性・一致性が重要な基準 |
| 区間推定 | 幅でパラメータを推定。信頼係数 $1-\alpha$ の信頼区間を構成 |
| 信頼区間の解釈 | 「この手順を繰り返すと $(1-\alpha)$ 割の区間が真の値を含む」 |
| $\sigma$ 既知 | 正規分布($z$ 値)を使う |
| $\sigma$ 未知 | $t$ 分布($t$ 値)を使う。自由度 $n-1$ |
| 母比率 | CLT で正規近似。$n\hat{p} \geq 5$ かつ $n(1-\hat{p}) \geq 5$ を確認 |
| 幅と精度 | 幅 $\propto 1/\sqrt{n}$。精度を2倍にするには $n$ を4倍にする |
次の章へ
区間推定で「幅で答える」方法を学びました。次は「仮説が正しいか判断する」仮説検定に進みます。
→ 次: 仮説検定の考え方