機械学習とは何か
機械学習(Machine Learning)は、21世紀において最も重要な技術革新の一つです。この技術は、コンピュータがデータから自動的にパターンを学習し、新しいデータに対して予測や判断を行う能力を与えます。人間が明示的にルールを記述する従来のプログラミングとは根本的に異なるアプローチを採用しており、現代のAI(人工知能)技術の中核を担っています。
機械学習の基本概念
[図1] 機械学習の基本概念
機械学習の核心は、経験からの自動学習です。人間が明示的にルールを記述する代わりに、データから自動的にパターンを発見し、そのパターンを使って新しい状況で予測や判断を行います。
機械学習の数学的前提
機械学習が有効に機能するためには、以下の重要な前提条件があります:
1. パターンの存在性 データには学習可能なパターンが存在する必要があります。完全にランダムなデータからは有用なモデルを構築できません。
2. 独立同分布仮定(i.i.d.仮定) 訓練データと未来のデータが同じ確率分布から生成されると仮定します。この仮定が破れると汎化性能が大幅に低下します。
3. 十分なサンプル数 統計的に信頼できるパターンを発見するには、十分な量のデータが必要です。一般的に、特徴量の数に対してサンプル数が十分多い必要があります。
従来のプログラミング vs 機械学習
[図2] 従来のプログラミング vs 機械学習
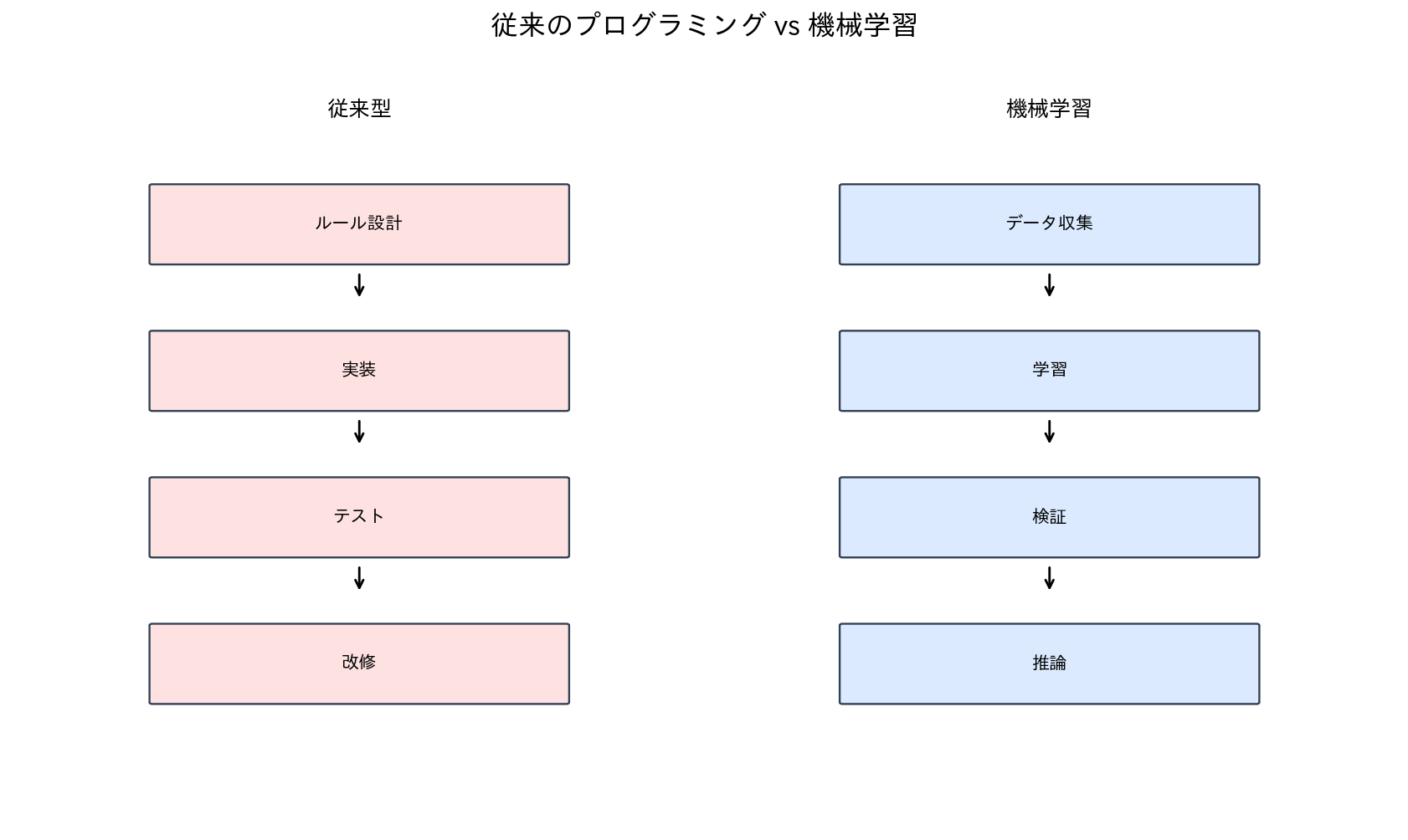
従来のプログラミングアプローチ
従来のプログラミングでは、プログラマーが問題解決のための明確な手順(アルゴリズム)を設計し、それをコードとして実装します。
基本的な流れ:
入力データ + プログラム(明示的ルール)→ 出力
具体例: 気温判定システム
def temperature_judgment(temp):
if temp >= 25:
return "暑い"
else:
return "涼しい"
このアプローチの特徴:
- 決定論的:同じ入力に対して常に同じ出力
- 透明性:ロジックが明確で説明可能
- 限定性:想定された状況でのみ有効
しかし、複雑な現実世界の問題では、すべての条件を事前に想定してルールを記述することは困難です。例えば、「暑い」と感じる温度は湿度、風速、個人差、地域差など多くの要因に依存します。
機械学習アプローチ
機械学習では、明示的なルールを記述する代わりに、データから自動的にパターンを学習します。
基本的な流れ:
入力データ + 正解データ(例)→ プログラム(学習されたモデル)
具体例: 同じ気温判定システムを機械学習で実現
# 学習データ:(温度, 湿度, 風速) → 感想
training_data = [
([22, 60, 2], "涼しい"),
([28, 70, 1], "暑い"),
([24, 50, 3], "涼しい"),
# ... 数千〜数万のデータ
]
# 機械学習モデルが自動的にパターンを学習
model = learn_from_data(training_data)
# 新しいデータに対して予測
prediction = model.predict([26, 65, 2])
このアプローチの特徴:
- 適応性:新しいデータで継続的に改善
- 発見性:人間が気づかないパターンの発見
- 汎用性:様々な問題に同じフレームワークを適用
機械学習の数学的基盤
関連教材(青の統計学)
関数近似としての機械学習
[図4] 関数近似としての機械学習
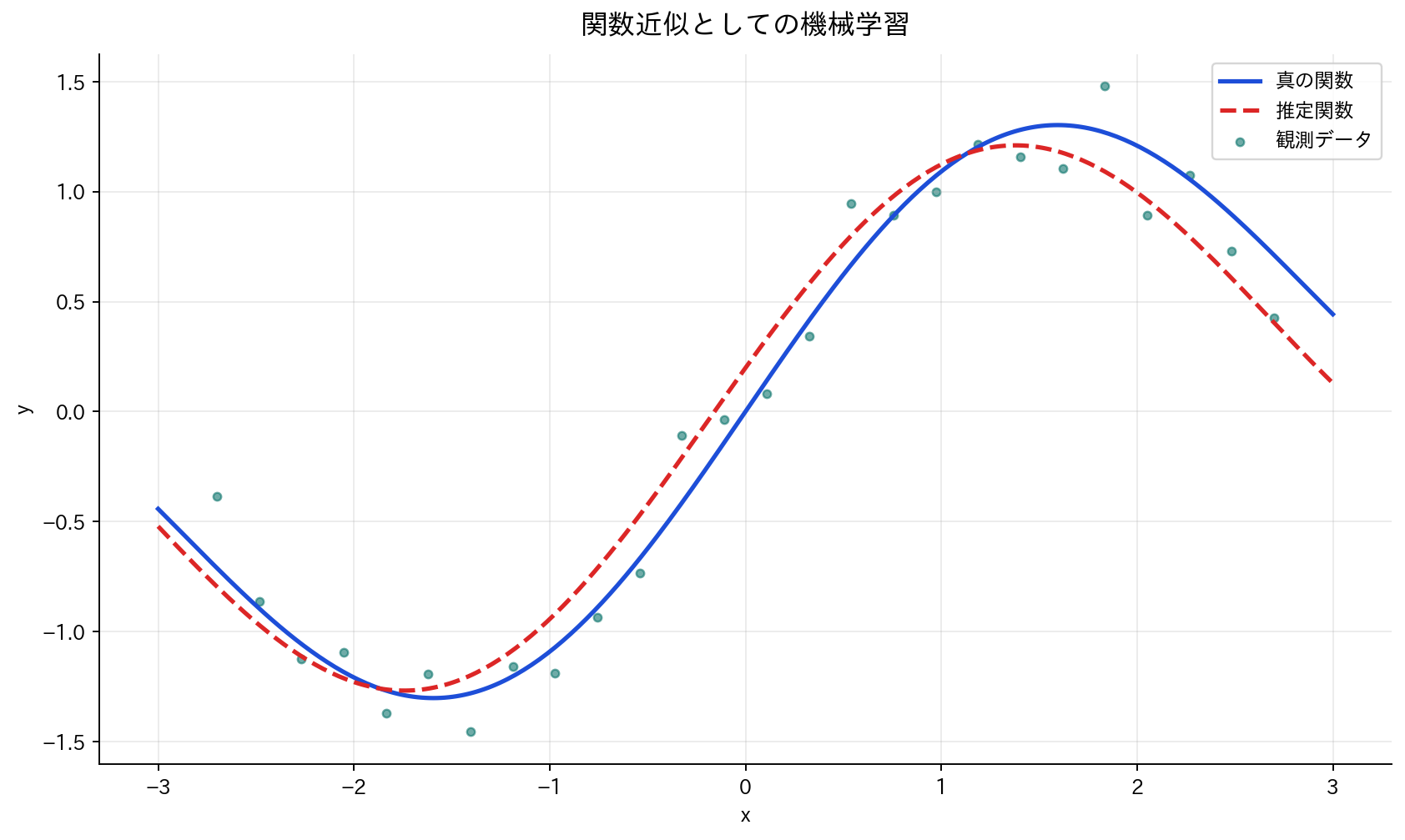
機械学習の本質は統計的関数近似です。現実世界の現象は、多くの場合、入力変数と出力変数の間に何らかの関数関係が存在します。
数学的表現:
ここで:
- $x$:入力データ(特徴量ベクトル)
- $y$:出力データ(目標変数)
- $f$:未知の真の関数
- $\varepsilon$:観測不可能なノイズ項
📚 直感的な理解
簡単に言うと、この式は「現実世界の現象は、完璧な法則($f(x)$)にランダムなノイズ($\varepsilon$)が加わったもの」という考え方を表しています。
例えば、身長から体重を予測する場合:
- $x$ = 身長(170cm)
- $y$ = 実際の体重(65kg)
- $f(x)$ = 「身長170cmの人の理想的な体重」(例:62kg)
- $\varepsilon$ = 個人差によるばらつき(+3kg)
つまり、機械学習は「多くの人のデータから、身長と体重の一般的な関係(関数$f$)を見つけ出す作業」です。完璧な予測は不可能(ノイズ$\varepsilon$があるため)ですが、できるだけ正確な関係性を発見しようとします。
機械学習の目標は、限られた訓練データ $\mathcal{D} = \{(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\}$ から、真の関数 $f$ に近い関数 $\hat{f}$ を推定することです。
汎化性能の重要性
単に訓練データに適合するだけでは不十分です。重要なのは、未知のデータに対する予測性能(汎化性能)です。この概念は統計学習理論の核心であり、以下の要素が関与します:
- バイアス:モデルの表現力の限界による誤差
- 分散:データのサンプリングによる予測のばらつき
- ノイズ:データに含まれる本質的な不確実性
優れた機械学習モデルは、これらのバランスを適切に調整して高い汎化性能を実現します。
機械学習の3つの主要分類
関連教材(青の統計学)
1. 教師あり学習(Supervised Learning)
教師あり学習は、入力と正解出力のペアから構成される訓練データを用いて学習する手法です。「教師」とは、各入力に対する正しい答えを提供する存在を意味します。
理論的基盤
教師あり学習の目標は、条件付き確率分布 $P(Y|X)$ を推定することです。これにより、新しい入力 $x$ に対して最も確からしい出力 $y$ を予測できます。
回帰問題(Regression)
回帰は連続値を予測する問題です。目標変数が実数値をとる場合に適用されます。
- 数学的定義:$y \in \mathbb{R}$(実数空間)
- 損失関数:通常は平均二乗誤差 $L(y, \hat{y}) = (y - \hat{y})^2$
- 典型例:
- 不動産価格予測:立地、面積、築年数から価格を予測
- 需要予測:過去の売上、季節性から将来の需要を予測
- 株価予測:過去の価格、取引量、経済指標から価格変動を予測
分類問題(Classification)
分類は離散的なクラス(カテゴリ)を予測する問題です。目標変数が有限個の値をとる場合に適用されます。
- 数学的定義:$y \in \{1, 2, \ldots, K\}$(有限集合)
- 損失関数:通常は交差エントロピー損失
- 典型例:
- 画像認識:画像から物体の種類を特定
- テキスト分類:文書の内容からカテゴリを判定
- 医療診断:症状や検査結果から疾患を特定
2. 教師なし学習(Unsupervised Learning)
教師なし学習は、正解ラベルが提供されない状況で、データの潜在的な構造やパターンを発見する手法です。
理論的背景
教師なし学習の目標は、観測データの背後にある確率分布 $P(X)$ や潜在構造を推定することです。これは密度推定や 構造発見 の問題として定式化されます。
クラスタリング(Clustering)
クラスタリングは、類似性に基づいてデータを自然なグループに分割する手法です。
- 目標:データ点間の類似性を最大化し、異なるグループ間の類似性を最小化
- 応用例:
- 顧客セグメンテーション:購買行動の類似性による顧客グループ化
- 遺伝子解析:類似した発現パターンを持つ遺伝子の同定
- 文書整理:内容の類似性による文書の自動分類
次元削減(Dimensionality Reduction)
次元削減は、高次元データを低次元空間に射影しながら重要な情報を保持する手法です。
- 目標:$d$ 次元データを $k$ 次元($k \ll d$)に圧縮
- 利点:可視化の容易さ、計算コストの削減、ノイズの除去
- 応用例:
- データ可視化:高次元データの2次元・3次元表示
- 特徴選択:重要な特徴量の自動選択
- データ圧縮:情報量を保持した効率的なデータ表現
3. 強化学習(Reinforcement Learning)
強化学習は、環境との相互作用を通じて最適な行動戦略を学習する手法です。試行錯誤を通じて報酬を最大化する方策を発見することが目標です。
マルコフ決定過程
強化学習は数学的にはマルコフ決定過程(MDP)として定式化されます:
- $\mathcal{S}$:状態空間
- $\mathcal{A}$:行動空間
- $\mathcal{P}$:状態遷移確率
- $\mathcal{R}$:報酬関数
- $\gamma$:割引率($0 \leq \gamma \leq 1$)
目標:累積割引報酬 $G_t = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1}$ の期待値を最大化する方策 $\pi$ を発見
応用分野:
- ゲームAI:囲碁、チェス、ポーカーなどの戦略ゲーム
- ロボティクス:歩行、操作、ナビゲーション
- 最適化問題:リソース配分、スケジューリング
- 金融:ポートフォリオ最適化、アルゴリズム取引
半教師学習:実用的な拡張
現実世界での課題
実際の機械学習プロジェクトでは、ラベル付きデータの不足が深刻な問題となります。正解ラベルの作成には、専門知識、時間、コストが必要だからです。
典型的な状況:
- 医療分野:膨大な医療画像データが存在するが、専門医による診断ラベルは限定的
- 自然言語処理:Web上のテキストは豊富だが、人手による分類作業は高コスト
- 製造業:センサーデータは大量だが、品質判定には専門技術者が必要
半教師学習のアプローチ
半教師学習(Semi-Supervised Learning)は、少量のラベル付きデータと大量のラベルなしデータを効果的に組み合わせる技術です。
数学的設定:
- ラベル付きデータ:$\mathcal{D}_l = \{(x_1, y_1), \ldots, (x_l, y_l)\}$
- ラベルなしデータ:$\mathcal{D}_u = \{x_{l+1}, \ldots, x_{l+u}\}$
- 通常 $u \gg l$(ラベルなしデータが圧倒的に多い)
基本的な仮定:
- 平滑性仮定:近いデータ点は同じラベルを持つ傾向
- クラスター仮定:同じクラスのデータは密な領域を形成
- 多様体仮定:データは低次元多様体上に分布
代表的手法:
- 自己学習:高信頼度の予測をラベルとして追加
- 協調学習:複数のモデルが互いに教え合う
- グラフベース手法:データ点間の類似度グラフを利用
機械学習の限界と課題
得意な問題領域
機械学習が威力を発揮するのは以下のような問題です:
大量データの存在
- パターン発見には十分な統計的サンプルが必要
- データの質と量が性能を大きく左右
複雑な非線形関係
- 人間が明示的にルールを記述することが困難
- 高次元空間での複雑な相互作用
継続的な変化への適応
- 環境の変化に応じてモデルを更新可能
- オンライン学習による継続的改善
苦手な問題領域
一方で、機械学習が不適切または非効率な場面も存在します:
データ不足の問題
- 希少事象や新しい領域では学習が困難
- 少数サンプルからの汎化は本質的に困難
解釈可能性の要求
- 医療診断、法的判断など説明責任が重要な分野
- ブラックボックスモデルの限界
単純な決定論的問題
- 明確なルールが存在する計算問題
- 機械学習の複雑さが不要な場合
機械学習プロジェクトのワークフロー
標準的なプロセス
実際の機械学習プロジェクトは、以下のような段階的なプロセスで進行します:
1. 問題設定と要件定義
- ビジネス目標の明確化
- 成功指標の設定
- 制約条件の整理
2. データ収集と探索的分析
- データソースの特定
- データの品質評価
- 統計的特性の把握
3. データ前処理と特徴量エンジニアリング
- 欠損値・外れ値の処理
- 特徴量の選択・生成・変換
- データの正規化・標準化
4. モデル選択と学習
- 問題特性に応じたアルゴリズム選択
- ハイパーパラメータの調整
- 交差検証による性能評価
5. 評価と改善
- テストデータでの最終評価
- エラー分析と改善方向の特定
- モデルの解釈と説明
6. 運用とメンテナンス
- 本番環境への展開
- 性能モニタリング
- 継続的な改善とアップデート
コラム:ノーフリーランチ定理
機械学習において最も重要な理論的結果の一つがノーフリーランチ定理(No Free Lunch Theorem)です。
定理の内容: すべての可能な問題に対して普遍的に優れた学習アルゴリズムは存在しない。ある問題で優秀なアルゴリズムも、別の問題では劣る可能性がある。
数学的表現: アルゴリズム $A$ と $B$ について、すべての問題の集合 $\mathcal{P}$ に対して:
実践的含意:
- 問題の性質を理解してアルゴリズムを選択する重要性
- ドメイン知識と事前仮定の価値
- 万能な機械学習手法は存在しないという認識
この定理は、機械学習の適用において問題理解が技術的手法と同等に重要であることを示しています。
バイアス-分散分解の数理
[図5] バイアス-分散トレードオフ
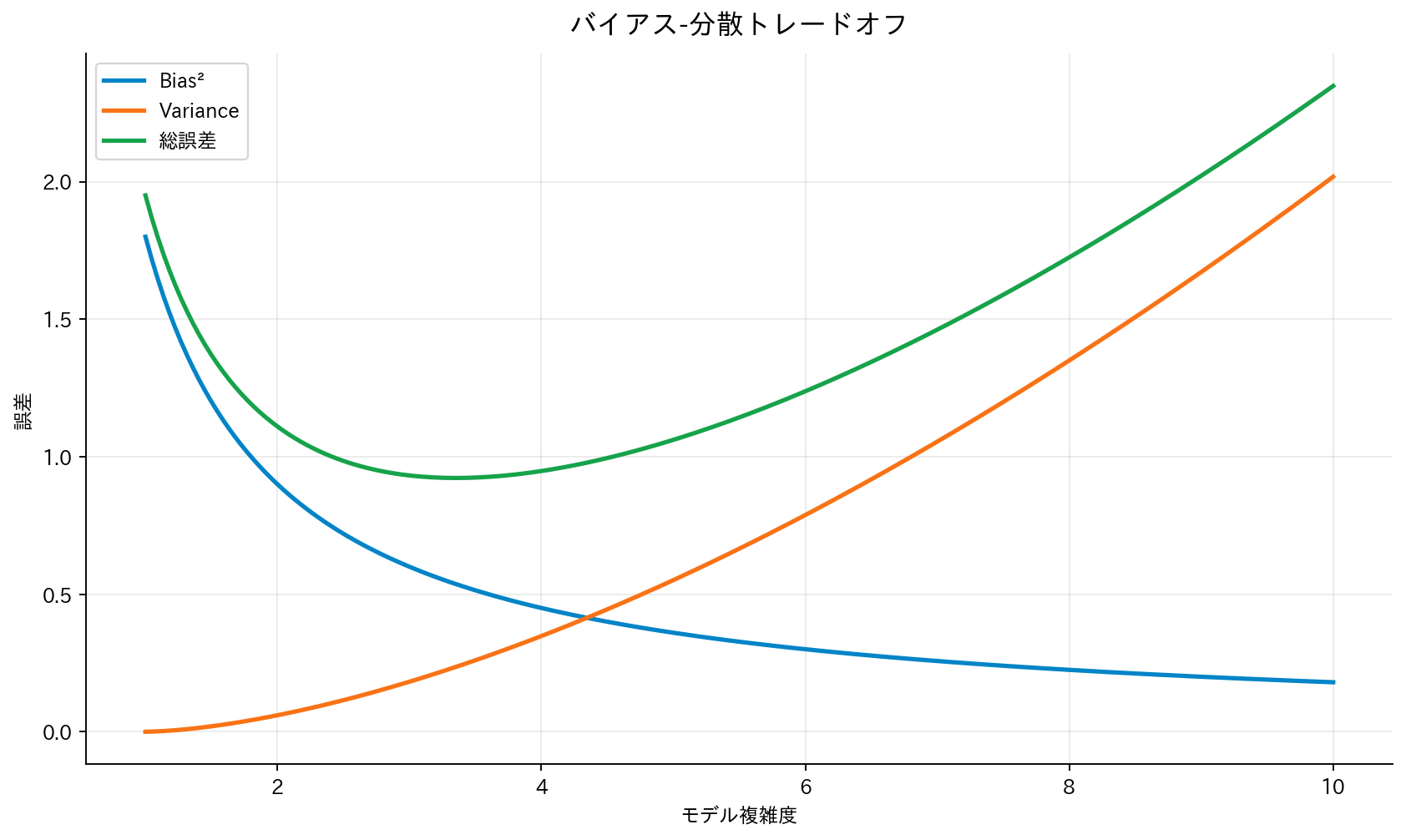
機械学習における予測誤差は、以下の3つの成分に分解できます:
バイアス(Bias): モデルの表現力不足による系統的な誤差。単純すぎるモデルで生じる。
分散(Variance): 訓練データの変化に対するモデル予測の敏感性。複雑すぎるモデルで生じる。
既約誤差(Irreducible Error): データに含まれる本質的なノイズ。どんなモデルでも削減不可能。
最適なモデルは、バイアスと分散のトレードオフを適切に調整したものです。
まとめ
機械学習は、データからパターンを自動的に発見し、予測や意思決定を行う強力な技術です。従来のルールベースアプローチでは対処困難だった複雑な問題に対し、統計的学習により効果的な解決策を提供します。
重要なポイント:
- パラダイムシフト:明示的ルールからデータ駆動アプローチへ
- 3つの学習タイプ:教師あり、教師なし、強化学習それぞれの特性
- 理論的基盤:統計学習理論に基づく関数近似問題
- 実用的考慮:データ品質、汎化性能、倫理的配慮の重要性
機械学習の成功は、適切な問題設定、良質なデータ、妥当な手法選択、慎重な評価の組み合わせによって達成されます。技術の進歩とともに、ますます多様で複雑な問題への応用が期待されています。
次章では、教師あり学習の中核を構成する「回帰と分類」について、より詳細に学習していきます。