回帰と分類の基本
機械学習の中でも最も基本的で重要な手法が回帰(Regression)と 分類(Classification) です。これらは教師あり学習の中核を成し、日常の様々な問題解決に幅広く応用されています。本章では、これらの基本概念と実用的な手法について学習します。
この章で学ぶこと
- 回帰と分類の違いを「出力空間」と「損失関数」の観点で説明できる
- OLSの仮定とロジスティック回帰の仮定を、推論・予測への影響まで含めて理解する
- 混同行列、ROC/AUC、閾値設計を使って、分類器の運用判断ができる
- 数式・評価・実装を一つの流れとして説明できる
前提知識チェック
- 線形代数:内積、行列、逆行列
- 微分:偏微分、勾配降下法の基本
- 確率統計:条件付き確率、ベルヌーイ分布、尤度
回帰と分類の違い
関連教材(青の統計学)
[図1] 回帰と分類の違い
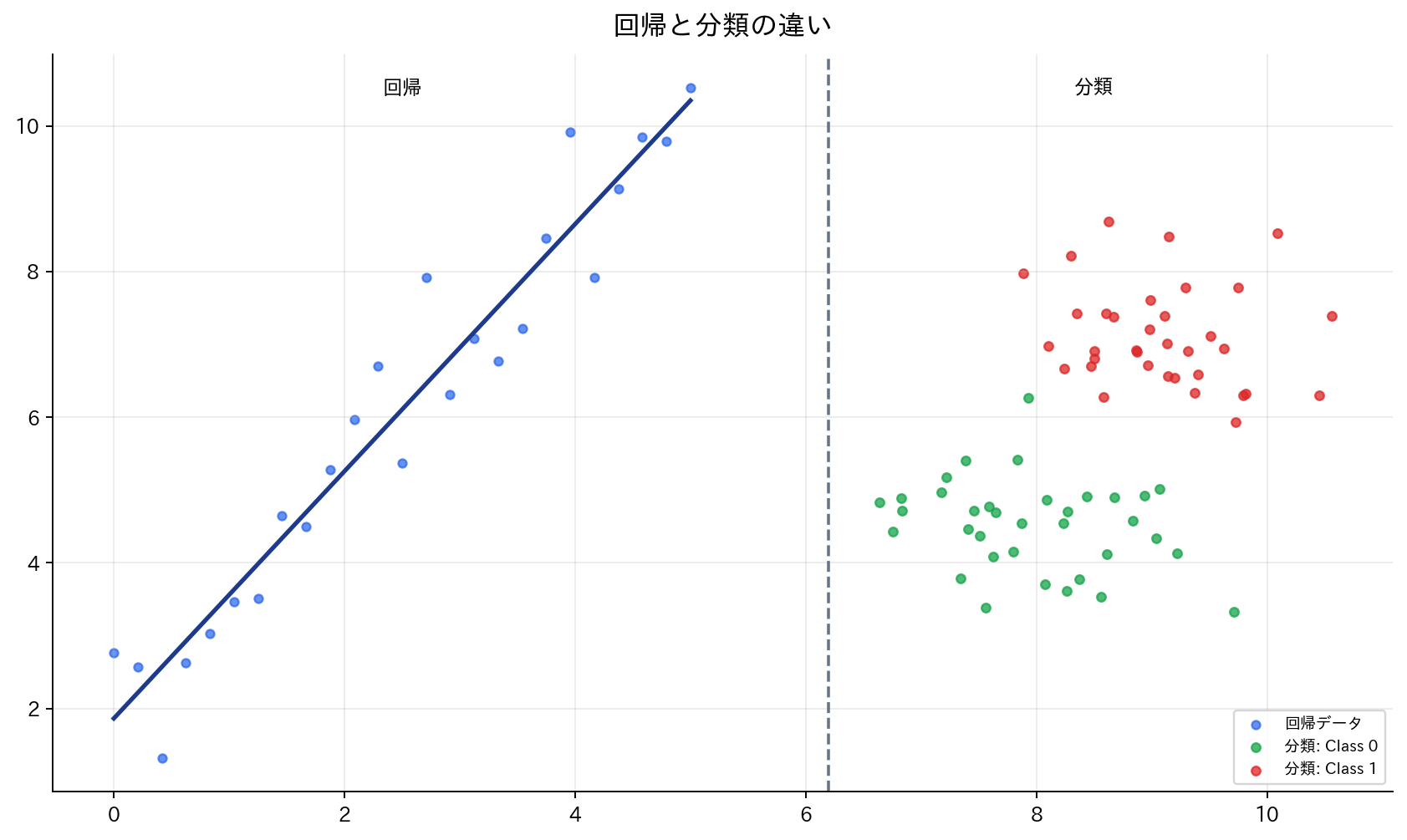
問題の種類
機械学習の問題は、予測したい出力の種類によって大きく2つに分けられます。
回帰問題:
- 連続値を予測する問題
- 例:住宅価格、気温、売上金額の予測
分類問題:
- カテゴリやラベルを予測する問題
- 例:メールのスパム判定、正常/異常検知、商品カテゴリ分類
回帰問題の基本
線形回帰の概念
最も基本的な回帰手法である線形回帰は、入力変数と出力変数の間に線形関係があると仮定する手法です。
基本式:
ここで:
- $y$: 予測したい目的変数
- $x_1, x_2, \ldots, x_n$: 入力変数(特徴量)
- $w_0, w_1, \ldots, w_n$: モデルのパラメータ(重み)
- $\varepsilon$: 誤差項(ノイズ)
最小二乗法
[図3] 線形回帰の最小二乗法
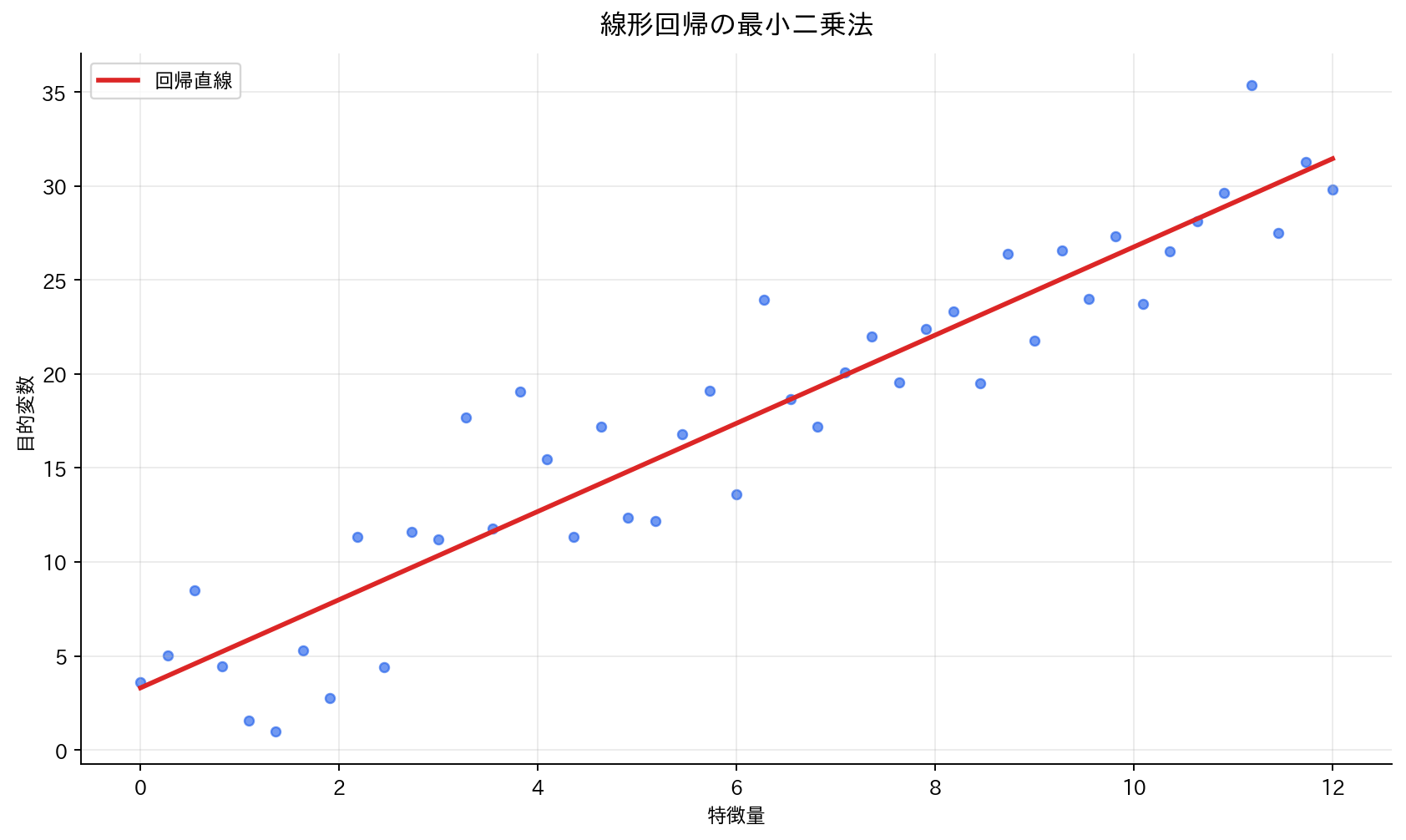
線形回帰のパラメータ推定で最も基本となるのが 最小二乗法(Ordinary Least Squares, OLS) です。
回帰モデルを次のように書きます:
ここで、$\varepsilon_i$ は「モデルで説明しきれない揺らぎ(誤差)」です。OLS は、残差 $r_i = y_i - \hat{y}_i$ の二乗和を最小にする $\boldsymbol{\beta}$ を選びます。
目的関数(残差平方和):
平均二乗誤差(MSE)は
計画行列 $\mathbf{X}$ を使うと、閉形式解は
OLS が前提とする代表的な仮定
最小二乗法は「計算手順」ですが、統計的に意味のある推定・検定を行うには仮定が重要です。
| 仮定 | 数理的な意味 | 何に影響するか |
|---|---|---|
| 線形性 | $E[y\mid \mathbf{x}] = \mathbf{x}^\top\boldsymbol{\beta}$ | モデル自体の妥当性 |
| 外生性 | $E[\varepsilon \mid \mathbf{X}] = 0$ | 係数の不偏性(バイアスの有無) |
| 完全多重共線性なし | 説明変数が完全には重ならない | 係数が一意に決まるか |
| 等分散性 | $\mathrm{Var}(\varepsilon \mid \mathbf{X})=\sigma^2$ | 標準誤差の精度・効率性 |
| 独立性 | 誤差同士が相関しない | 推論(信頼区間・検定)の信頼性 |
ガウス・マルコフ定理(なぜ OLS を使うのか)
上のうち主要な条件(線形性・外生性・等分散性・独立性)を満たすと、OLS 推定量は BLUE(Best Linear Unbiased Estimator)になります。
これは「線形かつ不偏な推定量の中で分散が最小」という意味です。
統計学的推論への接続
OLS では係数を求めるだけでなく、「その係数が統計的に有意か」を評価できます。
残差分散の推定量は
で、係数 $\hat{\beta}_j$ の標準誤差は
となり、$t$ 統計量
で有意性検定を行います。
機械学習では予測性能が主眼になりがちですが、実務では「どの要因がどれだけ効いているか」を説明するために、この推論部分が非常に重要です。
実例:住宅価格予測
住宅の価格を予測する例で考えてみましょう。
入力変数(特徴量):
- 部屋数
- 面積(m²)
- 築年数
- 駅からの距離
出力変数:
- 住宅価格(万円)
この場合の線形回帰式:
分類問題の基本
関連教材(青の統計学)
ロジスティック回帰
[図4] ロジスティック回帰のシグモイド関数
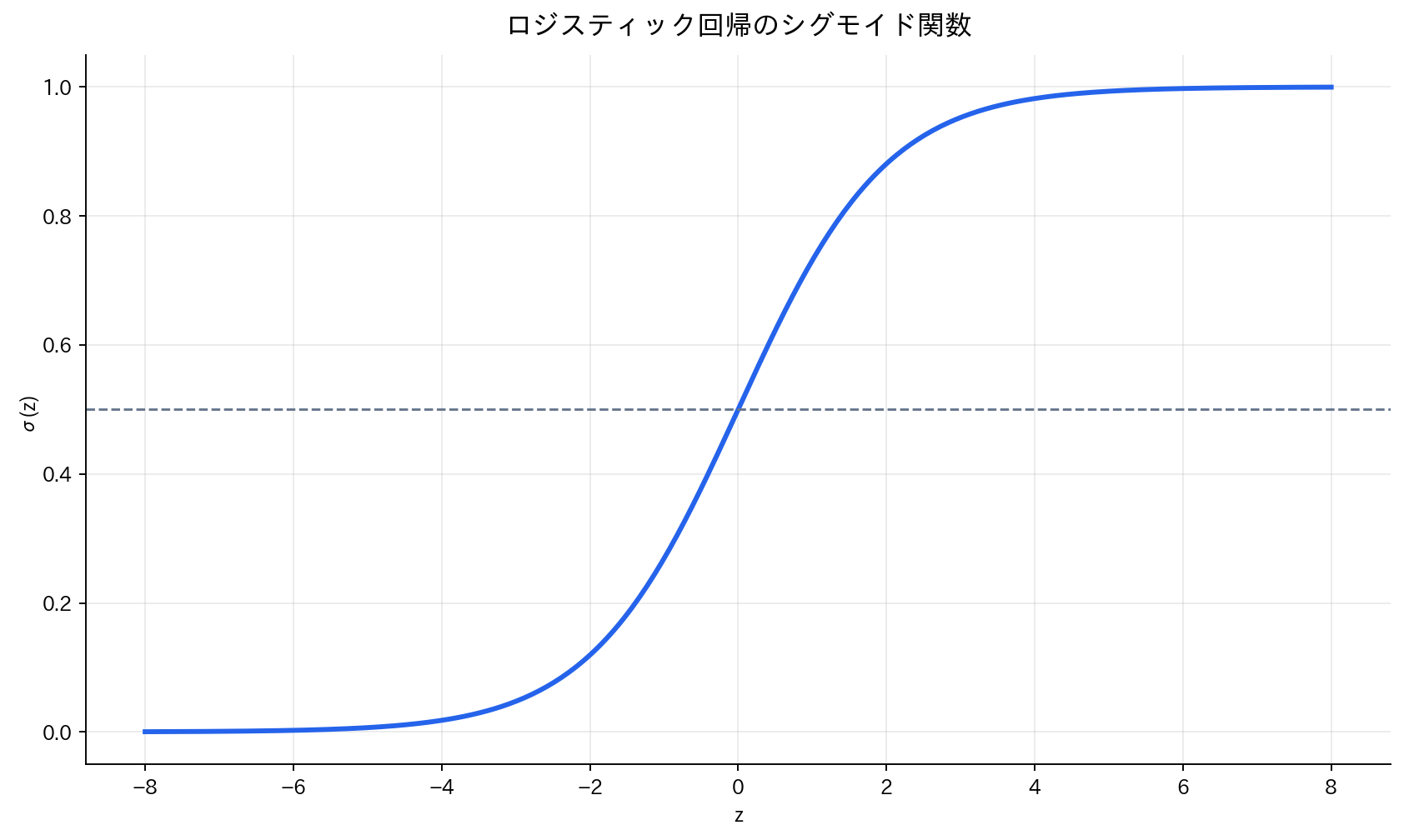
分類問題の代表的な手法が ロジスティック回帰 です。線形回帰と同様に線形結合を作りますが、そのまま出力せず確率へ写像します。
まず線形スコアを
シグモイド関数:
予測確率:
このとき、
係数の解釈(オッズ比)
他の特徴量を固定したとき、$x_j$ が1単位増えると対数オッズは $w_j$ だけ増加し、オッズは $e^{w_j}$ 倍になります。
- $w_j > 0$:クラス1になりやすくなる
- $w_j < 0$:クラス1になりにくくなる
- $e^{w_j}$:実務でよく使うオッズ比
学習原理:最尤推定と交差エントロピー
ロジスティック回帰は、各 $y_i\in\{0,1\}$ がベルヌーイ分布に従う確率モデルとして学習します。
この尤度を最大化することは、負の対数尤度を最小化することと同値で、損失関数は
になります。これは 交差エントロピー損失 そのものです。
つまりロジスティック回帰は「確率モデル」と「分類損失最小化」が一致する手法です。
ロジスティック回帰の主要な仮定
| 観点 | 代表的な仮定・条件 | 実務での確認ポイント |
|---|---|---|
| 目的変数 | 二値(または多クラス拡張) | ラベル定義の一貫性 |
| 独立性 | 観測が独立 | 同一ユーザー重複や時系列依存 |
| 線形性(logit空間) | 対数オッズが説明変数に線形 | 変換項・交互作用項の要否 |
| 共線性 | 強い多重共線性がない | VIF、係数の不安定性 |
| サンプル設計 | 極端な不均衡に注意 | クラス重み、閾値最適化 |
分類では閾値0.5が固定で正しいわけではありません。
医療・不正検知などでは、偽陰性/偽陽性コストに応じて閾値を最適化します。
決定境界
[図2] 決定境界の例
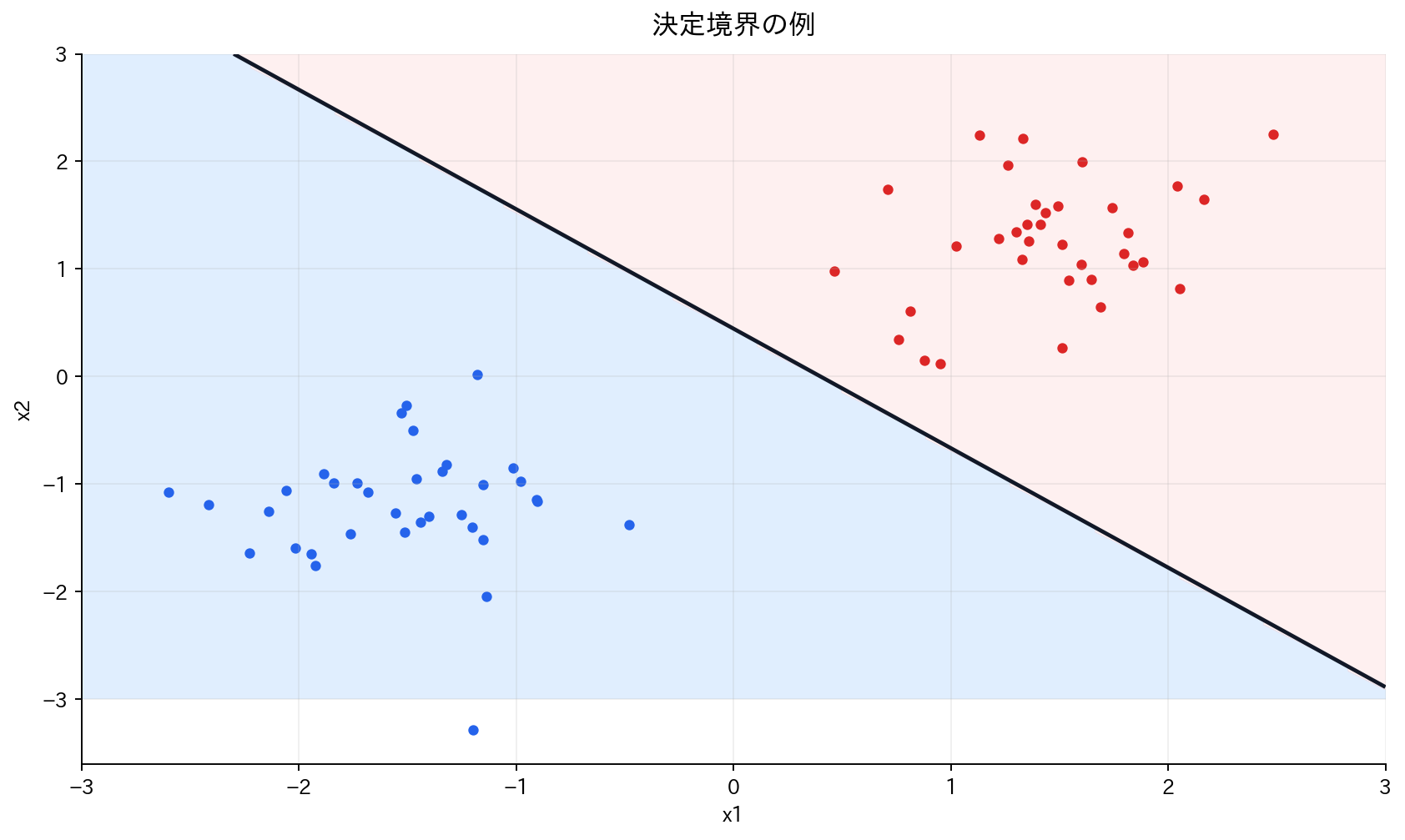
分類器は、データ空間を異なるクラスの領域に分割します。この境界を決定境界と呼びます。
- 線形分類器:直線(2次元)や超平面(高次元)で分割
- 非線形分類器:曲線や複雑な形状で分割
実例:メールスパム判定
メールがスパムかどうかを判定する例で考えてみましょう。
入力変数(特徴量):
- 件名に含まれる特定キーワードの数
- 送信者アドレスの形式
- 添付ファイルの有無
- メール本文の長さ
出力:
- スパム(1)または正常メール(0)
この場合、ロジスティック回帰でスパムである確率を計算し、閾値(例:0.5)を超えたらスパムと判定します。
さらに実務では、誤検知コストと見逃しコストを反映して閾値 $\tau$ を設計します。
例として、不正検知では見逃しコストが高いため $\tau$ を下げて再現率を重視する、といった運用判断が行われます。
コラム:混同行列の重要性
分類問題では、単純に正解率だけを見るのではなく、混同行列(Confusion Matrix)を使って詳細な分析を行うことが重要です。
2クラス分類の混同行列
| 予測:正常 | 予測:異常 | |
|---|---|---|
| 実際:正常 | TN(真陰性) | FP(偽陽性) |
| 実際:異常 | FN(偽陰性) | TP(真陽性) |
重要な指標
[図5] 混同行列から指標を計算する位置関係
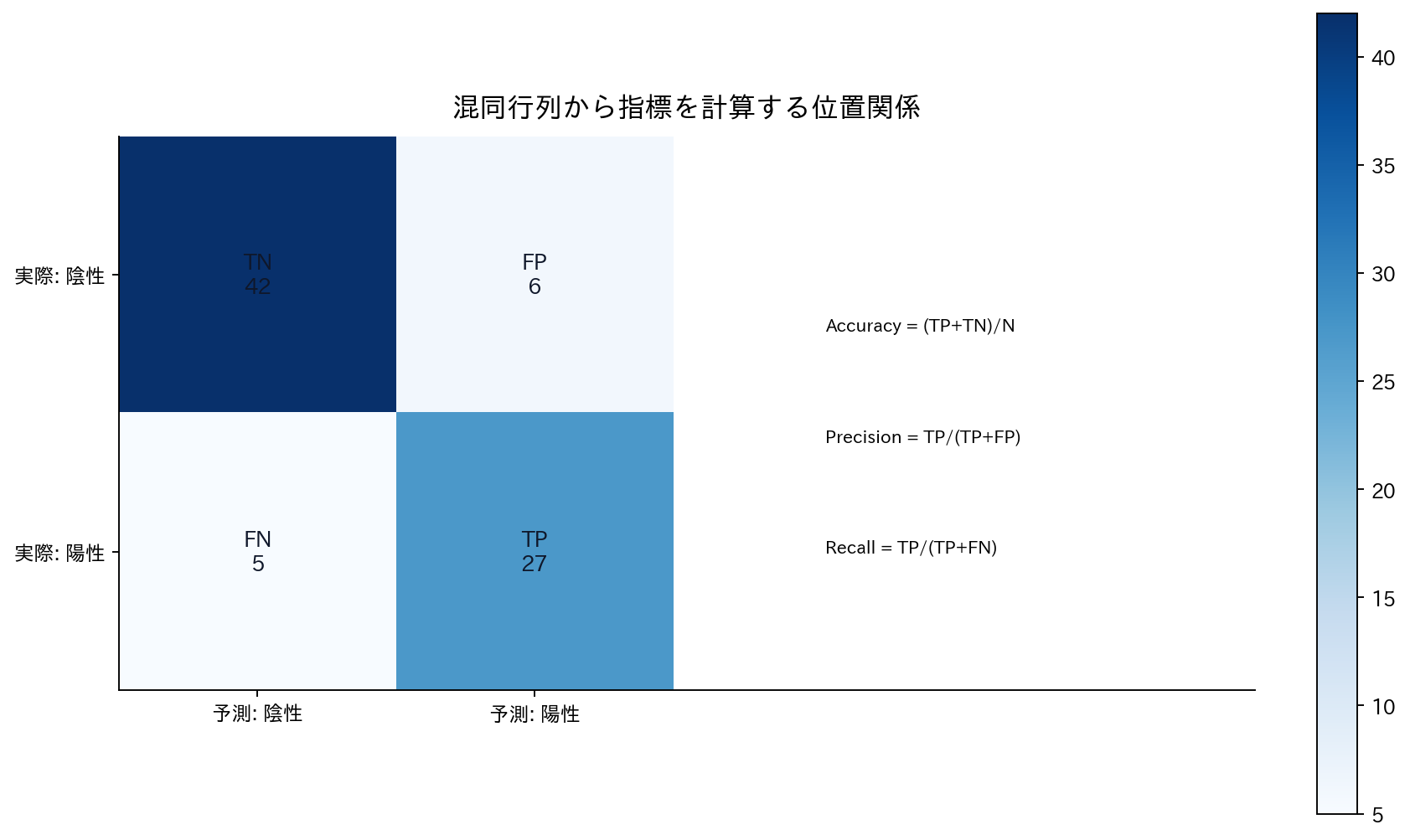
正解率(Accuracy):
適合率(Precision):
再現率(Recall):
F1スコア:
なぜ正解率だけでは不十分なのか
例えば、がん検診で99%が健康な人の場合:
- 「全員健康」と予測しても正解率99%
- しかし、がん患者を1人も発見できない
このような不均衡データでは、適合率・再現率のバランスが重要になります。
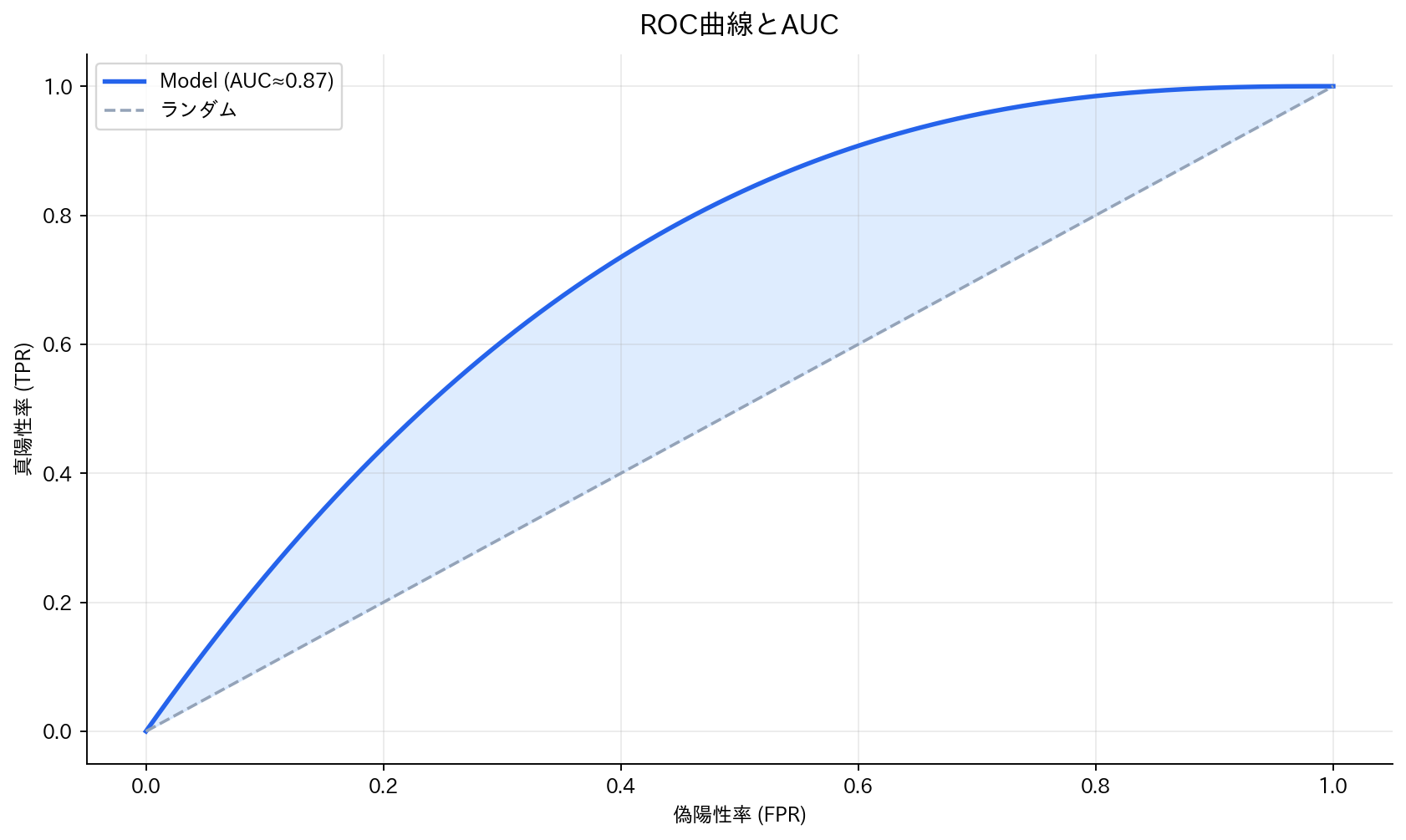
また、閾値を動かしたときの判別性能を確認するために、ROC曲線とAUCも併せて確認します。
[図6] ROC曲線とAUC
コラム:特徴量エンジニアリング
機械学習の性能を大きく左右するのが特徴量エンジニアリングです。
基本的な前処理
正規化・標準化:
- 異なるスケールの特徴量を統一
- 例:年収(万円)と年齢(歳)を同じスケールに
カテゴリ変数の処理:
- ワンホットエンコーディング
- 例:「赤」「青」「緑」→ [1,0,0], [0,1,0], [0,0,1]
特徴量の作成
多項式特徴量:
- $x_1, x_2$ から $x_1^2, x_2^2, x_1 \times x_2$ を作成
- 非線形な関係をモデル化
ドメイン知識の活用:
- 住宅価格予測で「面積/部屋数」(1部屋あたり面積)を作成
- 時系列データで「曜日」「月」などの周期性を考慮
実装ミニノート(評価と閾値設計)
正解率だけでモデルを選ぶと、不均衡データで失敗しやすくなります。
最小限、PR曲線 と ROC曲線 を見て、業務コストに応じて閾値を決めます。
import numpy as np
from sklearn.metrics import precision_recall_curve, f1_score
# y_score: モデルが出すクラス1の確率
precision, recall, thresholds = precision_recall_curve(y_true, y_score)
f1 = 2 * precision[:-1] * recall[:-1] / (precision[:-1] + recall[:-1] + 1e-12)
best_idx = np.argmax(f1)
best_threshold = thresholds[best_idx]
y_pred = (y_score >= best_threshold).astype(int)
print("best_threshold:", float(best_threshold))
print("f1:", float(f1_score(y_true, y_pred)))
実装例
Pythonでの基本的な実装
import numpy as np
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, accuracy_score
# 線形回帰の例
# データの準備(住宅価格データセット)
X = np.array([[3, 70, 5], [4, 90, 3], [2, 50, 10]]) # [部屋数, 面積, 築年数]
y = np.array([3000, 4500, 2000]) # 価格(万円)
# 訓練・テスト分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデル学習
model = LinearRegression()
model.fit(X_train, y_train)
# 予測と評価
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"平均二乗誤差: {mse}")
# ロジスティック回帰の例
# データの準備(スパム判定データセット)
X_cls = np.array([[5, 100], [1, 20], [10, 200], [0, 10]]) # [特定語数, 文字数]
y_cls = np.array([1, 0, 1, 0]) # スパム(1) or 正常(0)
# モデル学習
cls_model = LogisticRegression()
cls_model.fit(X_cls, y_cls)
# 予測と評価
y_cls_pred = cls_model.predict(X_cls)
accuracy = accuracy_score(y_cls, y_cls_pred)
print(f"正解率: {accuracy}")
まとめ
回帰と分類は機械学習の基本的な問題設定です。重要なポイント:
- 問題の種類の理解:連続値予測(回帰)vs カテゴリ予測(分類)
- 適切な手法の選択:線形回帰、ロジスティック回帰など
- 評価指標の重要性:MSE(回帰)、正解率・適合率・再現率(分類)
- 前処理の必要性:正規化、特徴量エンジニアリング
これらの基礎を理解することで、より高度な機械学習手法への理解が深まります。
次章では、これらの問題を解くための最適化手法である「損失関数と最適化」について学習します。
練習して定着(DS Playground)
- G検定演習(機械学習): /practice/g-certification/machine-learning/
- G検定演習(基礎): /practice/g-certification/basic/
- 分布可視化(誤差分布の理解に活用): /tool/probability-distribution-visualizer/