深層学習
深層学習(Deep Learning)は、多層のニューラルネットワークを用いて複雑なパターンを学習する機械学習の分野です。2010年代以降、画像認識、自然言語処理、音声認識などの様々な分野で従来手法を大幅に上回る性能を実現し、AI革命の中心的な技術となっています。本章では、深層学習の基本アーキテクチャから最新の技術まで体系的に学習します。
この章で学ぶこと
- 深層学習が「なぜ効くのか」を、関数近似と最適化の観点から説明できる
- CNN・RNN/LSTM・Attention の数式的な違いと使い分けを説明できる
- 勾配消失、過学習、学習不安定化に対する主要な対策を実装上の判断として理解できる
- 学習曲線と評価指標を使って、モデル改善の方向性を論理的に決められる
前提知識チェック
- 線形代数:行列積、転置、ノルム
- 微分:連鎖律、偏微分、勾配降下法
- 確率統計:尤度、交差エントロピー、バイアス・バリアンス
深層学習の基本概念
[図1] 深層学習のアーキテクチャ
なぜ「深い」ネットワークが有効なのか
深層学習における「深い」という概念は、単に層数が多いということ以上の重要な意味を持ちます。深いネットワークは、階層的な特徴表現を学習することができるのです。例えば、画像認識において、下位層では線や角度といった基本的な特徴を学習し、中間層ではこれらを組み合わせて形状や模様を認識し、上位層では物体全体の概念を理解します。
この階層的な学習は、人間の視覚システムが情報を処理する方法と類似しています。人間の視覚野でも、V1野では線分や方向性を、V2野では複雑な形状を、そしてより高次の領域では顔や物体を認識するという階層構造があります。深層学習はこの生物学的な情報処理の仕組みを模倣していると考えることができます。
表現学習の観点から見ると、深いネットワークは元の生データから段階的により抽象的で有用な特徴量を自動的に抽出します。これにより、従来は専門家が手作業で設計していた特徴量エンジニアリングの多くを自動化することが可能になりました。
数学的には、深層ネットワークは「関数の合成」として表現できます。
浅いモデルでも万能近似は可能ですが、実務では必要な表現を得るために巨大なユニット数が必要になりがちです。深いモデルは「中間表現を再利用」できるため、同じ複雑さの関数をより少ないパラメータで表現できる場合があります。
学習を支える最適化の見方
深層学習の訓練は、経験リスク最小化の問題として書けます。
ここで、$\ell$ はタスク固有の損失(分類なら交差エントロピーなど)、$\Omega$ は正則化項です。
実務では「訓練損失を下げる」だけでなく、検証データでの汎化誤差が改善しているかを同時に追います。
深層学習が成功した要因
深層学習の近年の成功には、理論的進歩、計算資源の向上、データの大量化という3つの要因が相互に作用しています。
理論面では、勾配消失問題を緩和するReLU活性化関数、効果的な重み初期化手法、バッチ正規化などの正則化技術、そしてドロップアウトなどの汎化手法が開発されました。これらにより、以前は訓練が困難だった深いネットワークを安定して学習させることが可能になりました。
計算資源の面では、GPU(Graphics Processing Unit)の活用が革命的な変化をもたらしました。もともと画像処理用に設計されたGPUの並列計算能力が、行列演算が中心となるニューラルネットワークの計算に非常に適していたのです。現在では、さらに専用化されたTPU(Tensor Processing Unit)なども開発されています。
データの面では、インターネットの普及により大量のラベル付きデータが利用可能になりました。ImageNetのような大規模データセットや、ウェブから収集された膨大なテキストデータが、深層学習モデルの訓練を可能にしています。
畳み込みニューラルネットワーク(CNN)
関連教材(青の統計学)
[図2] CNNの構造
畳み込み演算の基本原理
畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)は、画像データの処理に特化したニューラルネットワークアーキテクチャです。CNNの核心となる畳み込み演算は、画像の局所的な特徴を効率的に抽出するための仕組みです。
畳み込み演算では、小さなフィルタ(カーネル)を入力画像上で滑らせながら、各位置で要素ごとの積和演算を行います。このフィルタは学習可能なパラメータであり、訓練過程で特定のパターン(例:エッジ、角度、テクスチャ)を検出するように最適化されます。
数学的には、入力画像$I$とフィルタ$K$の畳み込み$(I * K)$は以下のように定義されます:
この演算により、画像全体にわたって同じパターンを検出できるため、平行移動不変性という重要な性質を獲得します。つまり、同じ物体が画像のどこに現れても、同じフィルタで検出することができるのです。
さらに、出力サイズは次式で決まります(高さ方向。幅方向も同様)。
ここで $P$ はパディング、$K$ はカーネルサイズ、$S$ はストライドです。
また、畳み込み層のパラメータ数は
となり、全結合層に比べてパラメータ効率が高い点がCNNの強みです。
プーリング層による次元削減
畳み込み層の後には、通常プーリング層が配置されます。プーリング層は、特徴マップのサイズを削減し、計算量を抑制するとともに、小さな位置変化に対する不変性を提供します。
最も一般的なマックスプーリング(Max Pooling)では、指定された領域内の最大値を選択します。これにより、その領域で最も強く反応した特徴が保持され、同時に位置情報が抽象化されます。平均プーリング(Average Pooling)では領域内の平均値を取り、より滑らかな特徴表現が得られます。
プーリング操作により、ネットワークは段階的により大きな受容野(receptive field)を持つようになり、より広範囲の文脈情報を捉えることができるようになります。
受容野は層を重ねるほど広がります。単純化した形では
で増加するため、浅い層の局所特徴と深い層の大域文脈を同時に学習できます。
代表的なCNNアーキテクチャ
LeNet-5(1998年): Yann LeCunらによって開発された初期のCNNアーキテクチャで、手書き数字認識に使用されました。畳み込み層、プーリング層、全結合層を組み合わせた基本的な構造は、現代のCNNの原型となっています。
AlexNet(2012年): ImageNetコンテストで従来手法を大幅に上回る性能を実現し、深層学習ブームの火付け役となったアーキテクチャです。ReLU活性化関数、ドロップアウト、データ拡張などの技術を組み合わせました。
VGGNet(2014年): 3×3の小さなフィルタを重ねることで深いネットワークを構築し、シンプルで理解しやすい設計思想を示しました。VGG-16、VGG-19など、深さによって複数のバリエーションがあります。
ResNet(2015年): 残差接続(residual connection)を導入することで、非常に深いネットワーク(152層)の訓練を可能にしました。勾配消失問題を劇的に改善し、現代の深層学習における重要な技術となっています。
リカレントニューラルネットワーク(RNN)
関連教材(青の統計学)
[図3] RNNの時間展開と勾配伝播
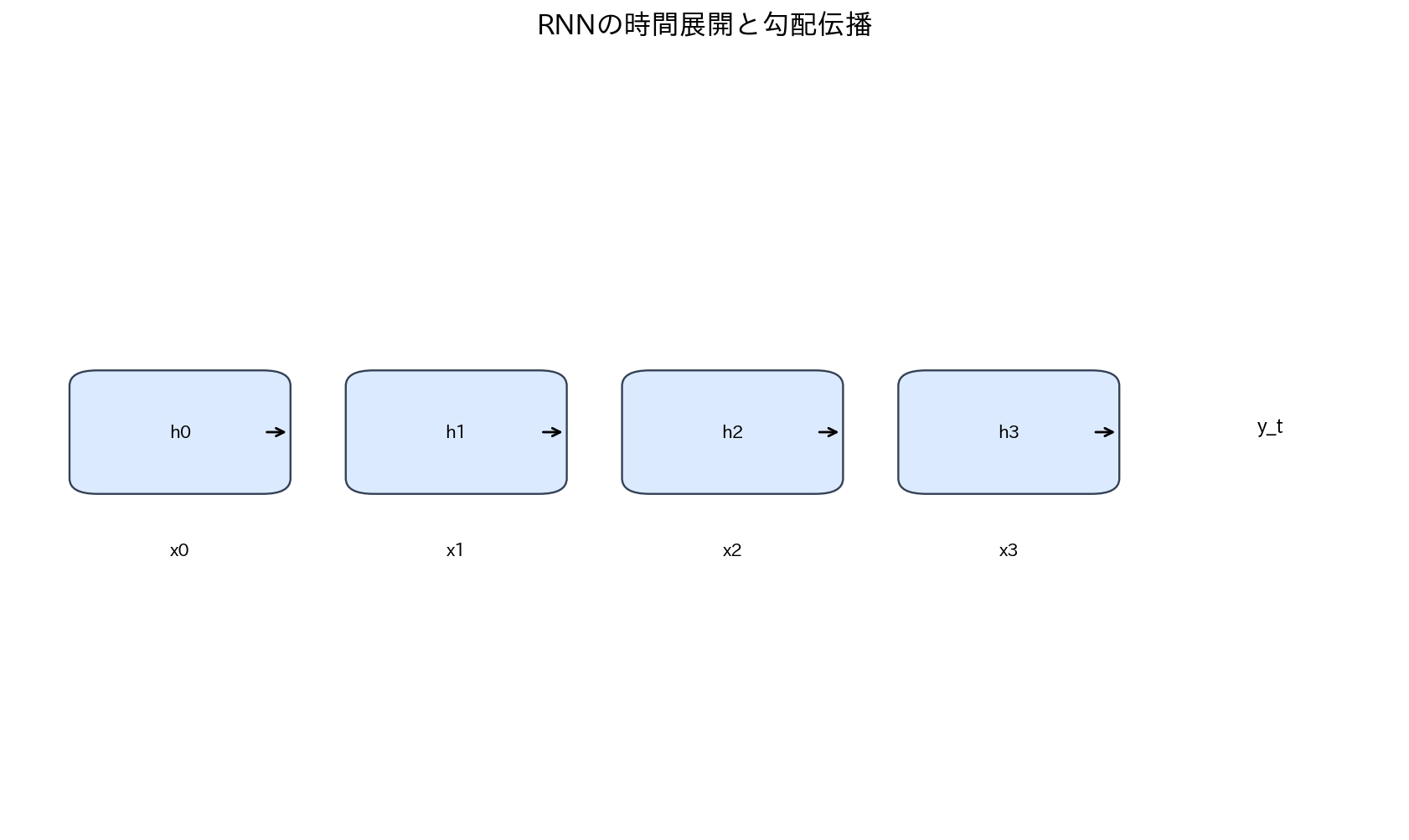
系列データの処理
リカレントニューラルネットワーク(Recurrent Neural Network, RNN)は、系列データの処理に特化したニューラルネットワークです。従来のフィードフォワード型ネットワークと異なり、RNNは内部状態(隠れ状態)を持ち、過去の情報を保持しながら現在の入力を処理します。
RNNの基本的な更新式は以下のようになります:
ここで、$h_t$は時刻$t$の隠れ状態、$x_t$は入力、$y_t$は出力を表します。この構造により、時系列データや自然言語のような系列データの複雑な依存関係をモデル化できます。
勾配消失・爆発問題
基本的なRNNには、長い系列を処理する際の勾配消失・爆発問題という重要な課題があります。誤差逆伝播を時間軸に沿って行う際、勾配が指数的に小さくなったり(勾配消失)、逆に大きくなりすぎたり(勾配爆発)する現象が発生します。
これは、同じ重み行列が時間ステップごとに繰り返し掛け合わされることが原因です。重み行列の固有値が1より小さければ勾配は消失し、1より大きければ爆発します。この問題により、基本的なRNNは長期的な依存関係を学習することが困難になります。
直感的には、BPTT(Backpropagation Through Time)で以下のような積が現れることが本質です。
この積のノルムが $0$ に近づくと勾配消失、発散すると勾配爆発が起こります。
LSTM(Long Short-Term Memory)
[図4] LSTMセルの内部構造
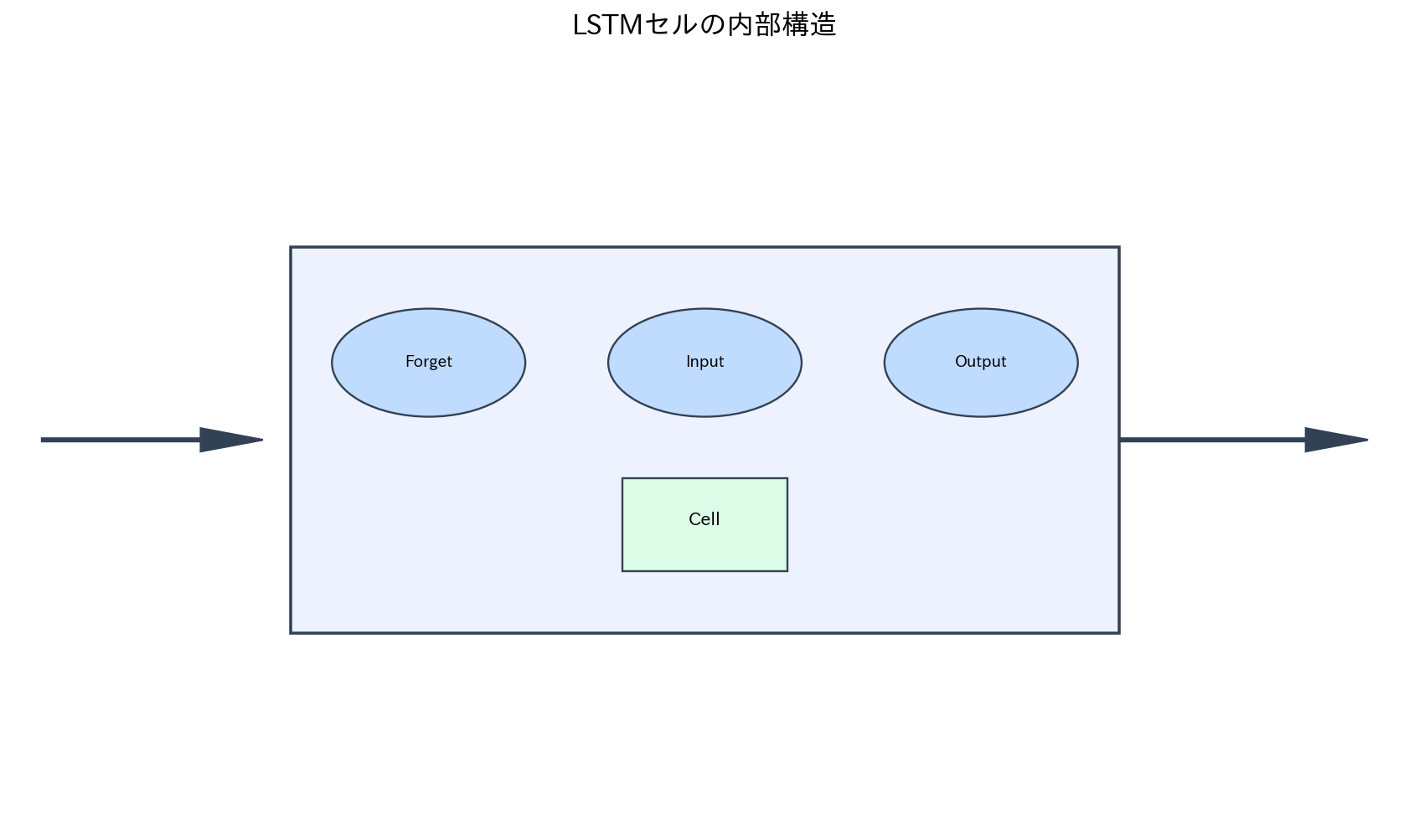
LSTM(Long Short-Term Memory)は、勾配消失問題を解決するために開発された特殊なRNNアーキテクチャです。LSTMは、情報の流れを制御する3つのゲート(忘却ゲート、入力ゲート、出力ゲート)とセル状態という仕組みを持っています。
忘却ゲートは、過去の情報のうち何を忘れるかを決定します。入力ゲートは、新しい情報のうち何をセル状態に保存するかを制御します。出力ゲートは、セル状態のどの部分を出力として使用するかを決定します。
セル状態は、重要な情報を長期間にわたって保持できる「記憶装置」として機能します。ゲートの制御により、関連性の低い情報は忘却され、重要な情報は保持されるため、長期的な依存関係を効果的に学習できます。
LSTM の主要更新式は次のとおりです。
特に $c_t$ の加法的更新が、長期依存の勾配伝播を助ける点が重要です。
GRU(Gated Recurrent Unit)
GRU(Gated Recurrent Unit)は、LSTMを簡略化したアーキテクチャです。LSTMの3つのゲートを2つ(リセットゲートと更新ゲート)に統合し、セル状態と隠れ状態を一つにまとめています。
GRUはLSTMよりもパラメータ数が少なく、計算効率が良いという利点があります。多くの実用的なタスクで、LSTMと同程度の性能を実現しながら、より高速に訓練・推論できます。
GRU の代表式は次のとおりです。
長系列でまず試す順序としては、計算コストが軽いGRUをベースラインにし、必要ならLSTMへ拡張するのが実務的です。
正則化手法
ドロップアウト
深層学習における最も重要な正則化手法の一つがドロップアウトです。これは、訓練時にランダムに選択されたニューロンの出力を0にする(つまり一時的に「無効化」する)技術です。
ドロップアウトの効果は、ネットワークが特定のニューロンに過度に依存することを防ぐことにあります。これにより、より汎化性能の高いモデルを学習できます。アンサンブル学習の観点から見ると、ドロップアウトは異なる部分ネットワークを暗黙的に組み合わせている効果があると解釈できます。
一般的に、全結合層では0.5、畳み込み層ではより小さな値(0.2-0.3)のドロップアウト率が使用されます。推論時にはドロップアウトは無効化され、全てのニューロンが使用されます。
訓練時の表現は
で、inverted dropout では推論時との整合のため訓練時に $\tilde{h}/(1-p)$ としてスケーリングします。
バッチ正規化
バッチ正規化(Batch Normalization)は、各層の入力を正規化することで学習を安定化・高速化する技術です。訓練中、各ミニバッチごとに活性化値を平均0、分散1に正規化します。
バッチ正規化の効果は多面的です。第一に、内部共変量シフト(internal covariate shift)を減少させることで、より安定した学習が可能になります。第二に、より大きな学習率を使用できるため、学習の高速化が実現されます。第三に、正則化効果により、ドロップアウトの必要性が減少します。
数式では、入力$x$に対して以下の変換が適用されます:
ここで、$\mu_B$と$\sigma_B^2$はバッチの平均と分散、$\gamma$と$\beta$は学習可能なパラメータです。
実装上の注意として、訓練時はバッチ統計量を使い、推論時は移動平均統計量を使います。
この切り替えが崩れると、学習中は良いのに本番精度が落ちる典型的な不具合になります。
その他の正則化技術
データ拡張(Data Augmentation)は、既存の訓練データに変換(回転、拡大縮小、反転など)を適用して、人工的にデータ数を増やす技術です。これにより、モデルの汎化性能を向上させることができます。
重み減衰(Weight Decay)は、L2正則化項を損失関数に追加することで、重みが大きくなりすぎることを防ぐ技術です。これにより、モデルの複雑度を制御し、過学習を抑制できます。
早期停止(Early Stopping)は、検証データでの性能が悪化し始めた時点で訓練を停止する技術です。これにより、過学習を防ぎながら最適なモデルを得ることができます。
コラム:Attention機構の革新
Attentionの基本概念
Attention機構は、入力の異なる部分に対して動的に重み付けを行う技術です。従来のRNNでは、長い系列の情報を固定長のベクトルに圧縮する必要がありましたが、Attention機構により、必要に応じて系列の任意の部分にアクセスできるようになりました。
基本的なAttention機構では、クエリ(Query)、キー(Key)、値(Value)という3つの概念を使用します。クエリに最も関連性の高いキーを見つけ、そのキーに対応する値を重み付き平均で統合します。
この仕組みにより、モデルは入力の重要な部分に「注意を向ける」ことができ、より効果的な情報処理が可能になります。
Multi-Head Attention では、異なる射影空間で複数の注意機構を並列に計算します。
これにより、構文的関係と意味的関係のような異なる依存を同時に捉えやすくなります。
Self-AttentionとTransformer
[図5] Self-AttentionとTransformerの計算フロー
Self-Attention(自己注意)は、同じ系列内の異なる位置間の関係をモデル化する技術です。これにより、系列内の長距離依存関係を効率的に捉えることができます。
Transformer アーキテクチャは、Self-Attentionを中心として構築された革新的なモデルです。従来のRNNやCNNを使わずに、Attention機構のみで系列変換を行います。Transformerの登場により、自然言語処理の分野では飛躍的な性能向上が実現されました。
コラム:転移学習とファインチューニング
事前訓練モデルの活用
転移学習は、大規模なデータセットで事前に訓練されたモデルを、異なるタスクに適用する技術です。深層学習では、特に画像認識分野でImageNetで事前訓練されたモデルを使用することが一般的になっています。
事前訓練されたモデルの下位層は、エッジや形状といった汎用的な特徴を学習しているため、多くのタスクで有用です。上位層をタスク固有のものに置き換えることで、少ないデータと計算資源で高性能なモデルを構築できます。
ファインチューニングの戦略
ファインチューニングでは、事前訓練されたモデルの重みを初期値として使用し、新しいタスクのデータで追加訓練を行います。この際、下位層の学習率を小さくし、上位層の学習率を大きくするのが一般的です。
データサイズに応じた戦略の選択も重要です。データが少ない場合は下位層を固定し、上位層のみを訓練します。データが十分にある場合は、全層をファインチューニングすることで最適性能を得られます。
深層学習モデルの選択基準
同じ深層学習でも、入力構造と制約条件で最適解は変わります。
この章の内容を実務に落とすときは、次の軸で選定すると判断が一貫します。
| 条件 | 優先するモデル | 補足 |
|---|---|---|
| 画像中心、局所パターン重視 | CNN系(ResNet/EfficientNetなど) | 計算効率が高く、学習データが中規模でも安定 |
| 系列長が短〜中程度、時系列予測 | RNN/LSTM/GRU | 時系列依存を扱いやすく、実装が比較的素直 |
| 長距離依存、文脈統合、汎用性 | Transformer系 | 高精度だが計算資源と推論コストが重い |
| 学習データが少ない | 事前学習モデル + 転移学習 | フルスクラッチより再現性が高い |
学習安定化の最小ループ
best_val = float("inf")
wait, patience = 0, 5
for epoch in range(max_epochs):
model.train()
optimizer.zero_grad()
loss = criterion(model(x_train), y_train)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
model.eval()
with torch.no_grad():
val_loss = criterion(model(x_val), y_val).item()
if val_loss < best_val:
best_val, wait = val_loss, 0
else:
wait += 1
if wait >= patience:
break
このループだけでも、勾配爆発と過学習の初期症状をかなり抑えられます。
理論章で扱った勾配制御・正則化は、実装上はこのような小さな分岐の集合として現れます。
転移学習での段階的解凍
# 1) まずはバックボーン凍結
for p in backbone.parameters():
p.requires_grad = False
optimizer = torch.optim.AdamW(head.parameters(), lr=1e-3)
# 2) 収束後に上位層だけ解凍して微調整
for p in backbone.layer4.parameters():
p.requires_grad = True
optimizer = torch.optim.AdamW([
{"params": backbone.layer4.parameters(), "lr": 1e-5},
{"params": head.parameters(), "lr": 1e-4},
])
全層を最初から更新すると、小規模データでは既存の表現を壊しやすくなります。
段階的解凍は、汎用表現を維持しつつタスク適応するための実務的な手順です。
まとめ
深層学習を使いこなす鍵は、モデル名を知ることではなく「どの条件でどの設計を選ぶか」を説明できることです。
CNN・RNN・Transformerの違いを、入力構造・計算コスト・汎化性能の観点で整理しておくと、実装判断がぶれにくくなります。
次のステップ
次章では、深層学習の主要応用分野である自然言語処理に進みます。
ここで学んだAttentionや転移学習の考え方が、NLPでどのように効くかを具体化していきます。