ロジスティック回帰:分類問題への確率的アプローチ
Stage 2 — 第2章| 機械学習基礎カリキュラム 推定学習時間:60〜70分 | 難易度:★★★☆☆
この章で学ぶこと
「この顧客は商品を購入するか?」「このメールはスパムか?」「この患者は病気を持っているか?」——これらはすべて「Yes/No」で答える分類問題です。しかし、単に分類するだけでなく「どの程度の確信を持って分類したか」を知りたいことがよくあります。
前章では線形回帰を学びましたが、線形回帰は連続値の予測のための手法でした。では、分類問題に線形回帰をそのまま使えるでしょうか?実は、いくつかの根本的な問題があります。ロジスティック回帰は、線形回帰の考え方を活かしながら、これらの問題を解決する洗練された手法です。
この章を終えると、こんなことができるようになります:
- なぜ分類問題に線形回帰が適さないかを数学的に説明できる
- シグモイド関数の役割と性質を理解し、確率的な予測の仕組みを説明できる
- 最尤推定法による学習の原理を理解し、実装できる
- オッズ比を使って係数の解釈ができる
- 多クラス分類への拡張方法を理解できる
1. なぜロジスティック回帰が必要か
分類問題の難しさ
[図2] 分類問題の難しさ
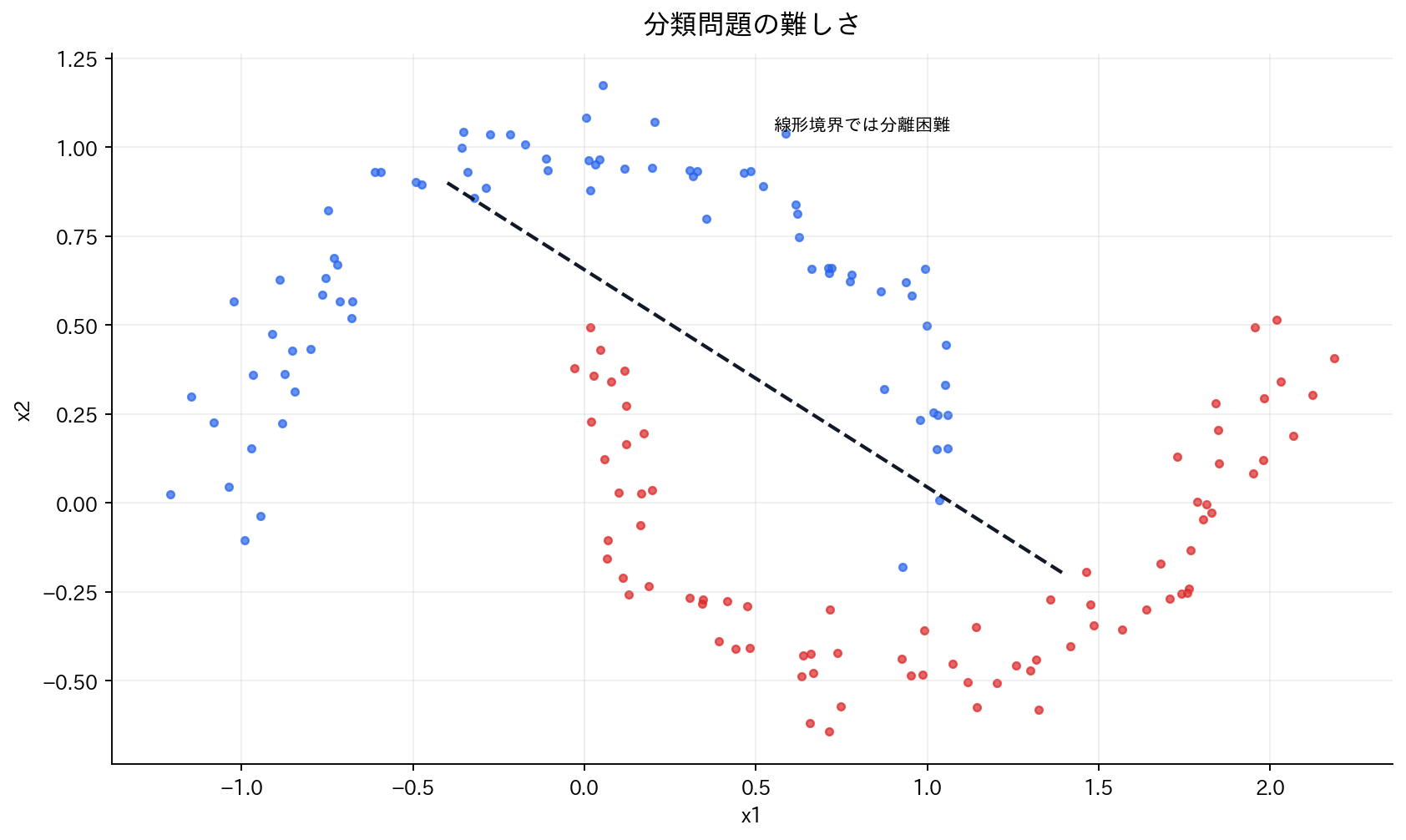
私たちが扱いたいのは、入力特徴量 $\mathbf{x}$ から、離散的なクラス(例:$y \in \{0, 1\}$)を予測する問題です。最初に思いつくのは、線形回帰をそのまま使う方法かもしれません。クラス0を数値の0、クラス1を数値の1として扱い、線形回帰で予測した後、0.5を閾値として分類する——一見合理的に見えます。
しかし、この素朴なアプローチには致命的な問題があります。
線形回帰の限界
2クラス分類($y \in \{0, 1\}$)に線形回帰を適用すると:
この予測値 $\hat{y}$ には次のような問題が生じます:
第一の問題:範囲の逸脱 線形回帰の予測値は $(-\infty, +\infty)$ の任意の値を取りえます。しかし、私たちが欲しいのは「クラス1である確率」であり、これは必ず $[0, 1]$ の範囲に収まるべきです。予測値が1.5や-0.3といった値になったとき、これをどう解釈すればよいでしょうか?
第二の問題:外れ値への過敏性 線形回帰は二乗誤差を最小化するため、外れ値の影響を強く受けます。分類問題では、明確に分離された2つのクラスがあっても、片方のクラスに極端な値があると、決定境界が大きくずれてしまいます。
第三の問題:確率的解釈の欠如 分類の確信度を知りたい場合、「このサンプルがクラス1である確率は70%」といった情報が欲しくなります。線形回帰の出力をそのまま確率として解釈することはできません。
[図3] 線形回帰とロジスティック回帰の出力比較
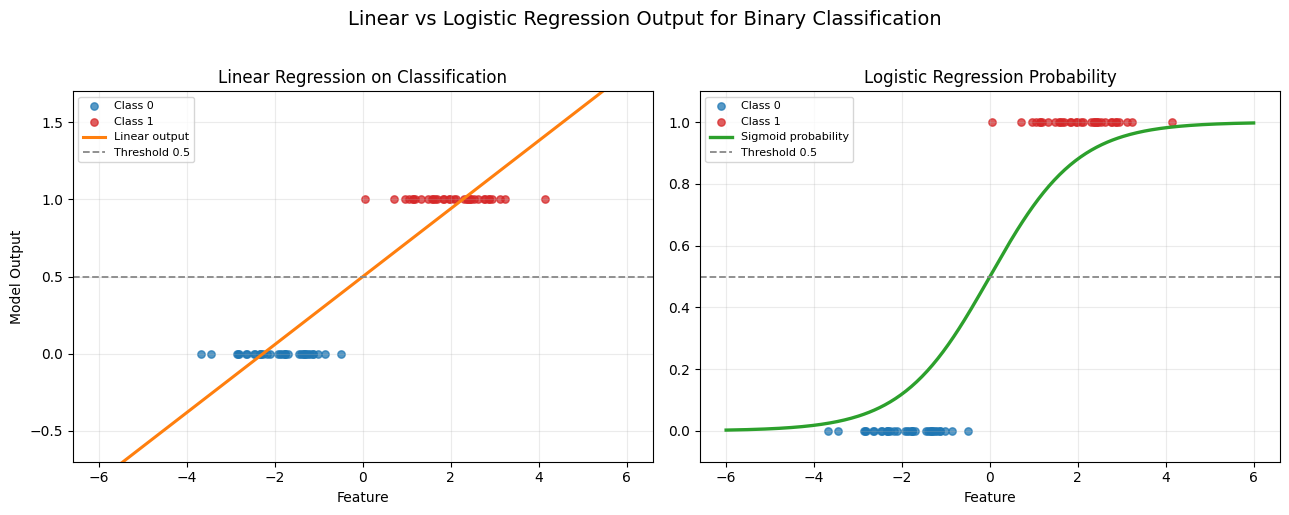
左図(線形回帰)では予測が0未満や1超になり得るのに対し、右図(ロジスティック回帰)ではシグモイド変換により常に0〜1へ収まります。
この「範囲制約が自然に入る」点が、分類問題でロジスティック回帰を使う最大の理由です。
これらの問題を解決するため、線形予測を確率に変換する巧妙な仕組みが必要になります。それがロジスティック回帰です。
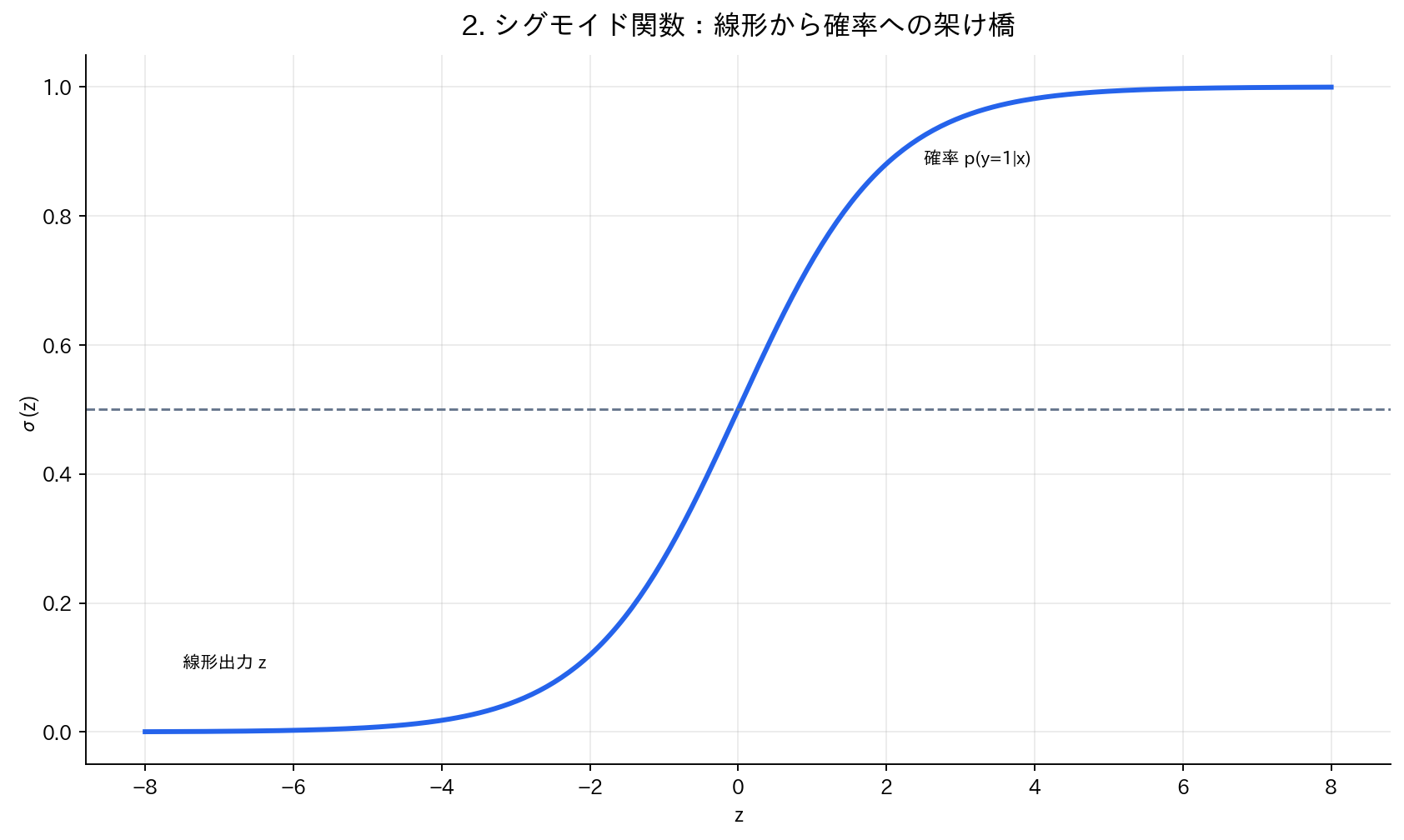
2. シグモイド関数:線形から確率への架け橋
関連教材(青の統計学)
[図4] 2. シグモイド関数:線形から確率への架け橋
理想的な変換関数の条件
[図5] 理想的な変換関数の条件
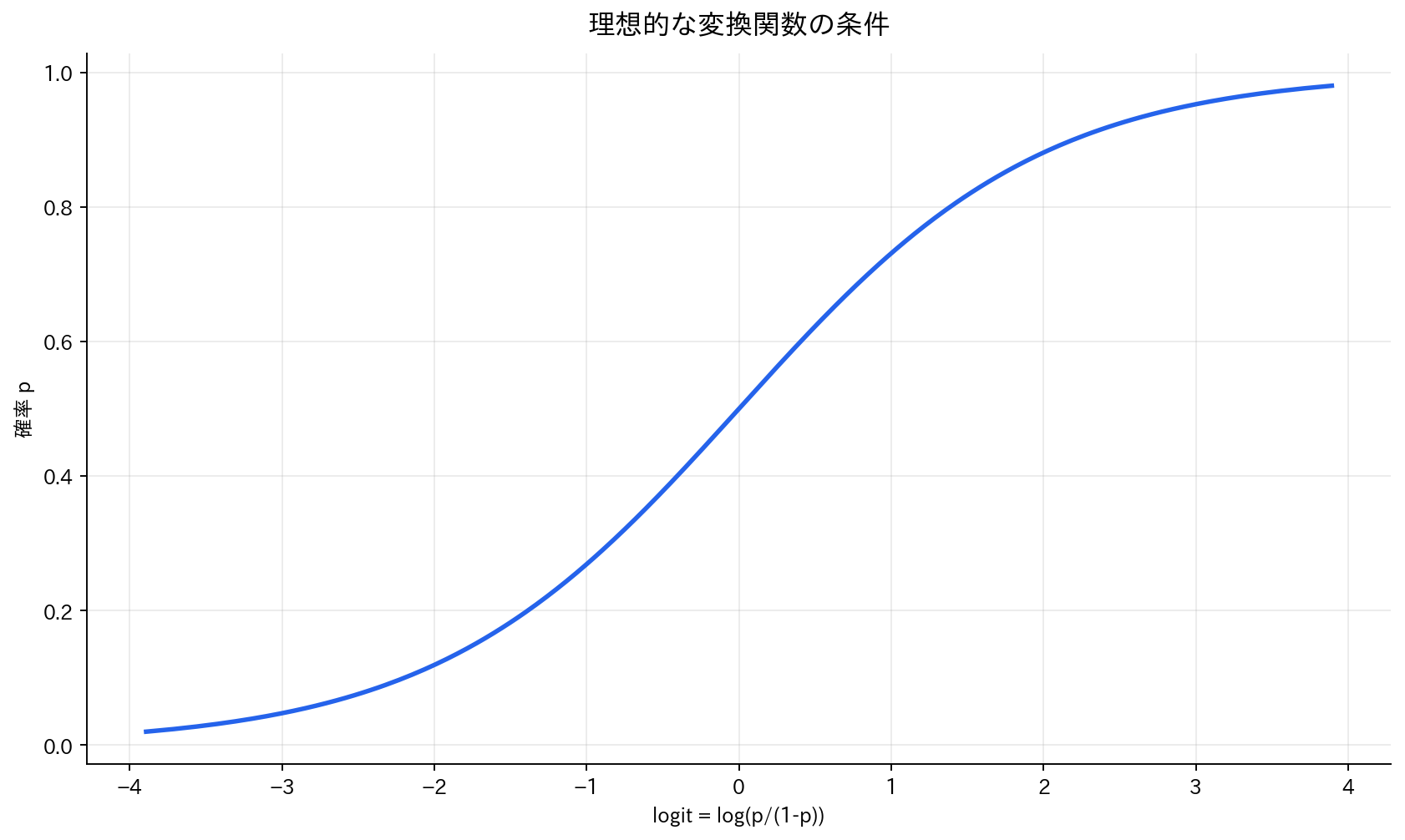
線形予測 $\mathbf{x}^T\boldsymbol{\beta}$ を確率に変換する関数を探しています。この関数には、どのような性質が必要でしょうか?
まず、出力は必ず0から1の範囲に収まる必要があります。また、線形予測が大きくなるほどクラス1の確率が高くなり、小さくなるほどクラス0の確率が高くなるという単調性も必要です。さらに、数学的に扱いやすい(微分可能で、微分が簡単な形になる)ことも重要です。
これらすべての条件を満たす理想的な関数が、シグモイド関数(ロジスティック関数とも呼ばれます)です。
シグモイド関数の定義と直感
シグモイド関数は次のように定義されます:
この関数がなぜ理想的なのか、その振る舞いを見てみましょう。$z$ が非常に大きい正の値のとき、$e^{-z}$ はほぼ0になるため、$\sigma(z) \approx 1$ となります。逆に $z$ が非常に小さい負の値のとき、$e^{-z}$ は非常に大きくなるため、$\sigma(z) \approx 0$ となります。そして $z = 0$ のとき、$\sigma(0) = 1/(1+1) = 0.5$ となり、ちょうど中間の確率を示します。
この S 字型の曲線は、線形予測を滑らかに確率に変換します。極端な予測値に対しても、確率は0や1に漸近するだけで、決してその範囲を超えることはありません。
シグモイド関数の美しい性質
シグモイド関数には、数学的に扱いやすい美しい性質があります:
対称性の性質:
この性質は、クラス0とクラス1の確率が対称的な関係にあることを示しています。線形予測の符号を反転させると、2つのクラスの確率が入れ替わります。
微分の性質:
驚くべきことに、シグモイド関数の微分は、元の関数値だけで表現できます。この性質により、勾配の計算が非常に効率的になり、学習アルゴリズムの実装が簡潔になります。
ロジスティック回帰モデルの構築
シグモイド関数を使って、入力 $\mathbf{x}$ からクラス1の確率を予測するモデルを構築します:
ここで $\mathbf{x}^T\boldsymbol{\beta}$ は線形回帰と同じ線形結合ですが、その出力をシグモイド関数で変換することで、確率として解釈可能な値を得ています。
オッズとロジット:別の視点から見たロジスティック回帰
ロジスティック回帰には、もう一つの興味深い解釈があります。「オッズ」という概念を使った解釈です。
オッズとは、ある事象が起こる確率と起こらない確率の比です:
ロジスティック回帰モデルを使うと、このオッズは次のようになります:
さらに、両辺の対数を取ると:
この左辺を「対数オッズ」または「ロジット」と呼びます。つまり、ロジスティック回帰は対数オッズが入力の線形結合になるモデルとして解釈できます。これは係数の解釈において重要な視点を提供します。
3. パラメータの学習:最尤推定法
関連教材(青の統計学)
最適なパラメータをどう見つけるか
モデルの形が決まったので、次はパラメータ $\boldsymbol{\beta}$ を学習する方法を考えます。線形回帰では最小二乗法を使いましたが、ロジスティック回帰では確率モデルなので、より自然なアプローチがあります。それが最尤推定法です。
最尤推定法の基本的な考え方は「観測されたデータが得られる確率(尤度)を最大にするパラメータを選ぶ」というものです。実際のデータが観測される確率が高いパラメータほど、そのデータをうまく説明できるパラメータだと考えるのです。
尤度関数の構築
訓練データ $\{(\mathbf{x}_i, y_i)\}_{i=1}^n$ が与えられたとき、各データ点が観測される確率を考えます。
データ点 $i$ について:
- $y_i = 1$ の場合、その確率は $P(y_i=1|\mathbf{x}_i) = p_i$
- $y_i = 0$ の場合、その確率は $P(y_i=0|\mathbf{x}_i) = 1 - p_i$
これを統一的に書くと:
この式の巧妙さに注目してください。$y_i = 1$ のときは $p_i$ だけが残り、$y_i = 0$ のときは $(1-p_i)$ だけが残ります。
すべてのデータ点が独立に生成されたと仮定すると、全データの尤度は個々の確率の積になります:
ここで $p_i = \sigma(\mathbf{x}_i^T\boldsymbol{\beta})$ です。
対数尤度への変換
尤度 $L(\boldsymbol{\beta})$ は確率の積なので、データが多いと非常に小さな値になり、数値計算上の問題(アンダーフロー)が生じます。また、積の微分は複雑です。
そこで、対数を取ることでこれらの問題を解決します。対数は単調増加関数なので、対数尤度を最大化することは尤度を最大化することと等価です:
対数により積が和に変換され、計算が安定かつ簡単になりました。
損失関数としての定式化
機械学習では慣例的に最小化問題として扱うため、負の対数尤度を損失関数とします。また、データ数で正規化することで、異なるデータセットサイズでも比較可能にします:
この損失関数は交差エントロピー損失(binary cross-entropy loss)と呼ばれます。情報理論の観点から見ると、真の分布($y_i$)と予測分布($p_i$)の間の距離を測っていることになります。
4. 勾配降下法による最適化
なぜ閉形式解が存在しないのか
線形回帰では、正規方程式により閉形式解(解析解)を得ることができました。しかし、ロジスティック回帰の損失関数には対数やシグモイド関数が含まれているため、$\nabla J(\boldsymbol{\beta}) = 0$ を解析的に解くことができません。
そこで、数値最適化手法を使います。幸いなことに、ロジスティック回帰の損失関数は凸関数であることが証明できるため、勾配降下法により必ず大域最適解に到達できます。これは、どこから始めても同じ最適解に収束することを保証する重要な性質です。
勾配の導出
損失関数 $J(\boldsymbol{\beta})$ を最小化するため、その勾配を計算します。驚くほど美しいことに、複雑に見える損失関数の勾配は非常にシンプルな形になります。
まず、一つのデータ点に対する損失の微分を考えます。連鎖律とシグモイド関数の微分の性質 $\sigma'(z) = \sigma(z)(1-\sigma(z))$ を使うと:
この導出は技術的ですが、結果は直感的です:予測確率 $p_i$ と実際のラベル $y_i$ の差に、特徴量 $x_{ij}$ を掛けたものです。
全データに対する勾配は:
ここで $\mathbf{p} = [p_1, p_2, \ldots, p_n]^T$ は全データ点の予測確率ベクトルです。
この式の美しさに注目してください。線形回帰の勾配と形式的に同じで、違いは予測値が線形出力ではなくシグモイド変換後の確率になっているだけです。
実装
import numpy as np
class LogisticRegression:
def __init__(self, learning_rate=0.01, epochs=1000, regularization=0):
self.lr = learning_rate
self.epochs = epochs
self.lambda_ = regularization # L2正則化
def sigmoid(self, z):
"""シグモイド関数(数値的に安定な実装)"""
return np.where(z >= 0,
1 / (1 + np.exp(-z)),
np.exp(z) / (1 + np.exp(z)))
def fit(self, X, y):
"""勾配降下法による学習"""
n, p = X.shape
# バイアス項を追加
X_with_bias = np.c_[np.ones(n), X]
self.beta = np.zeros(p + 1)
# 学習履歴
self.loss_history = []
for epoch in range(self.epochs):
# 予測確率
z = X_with_bias @ self.beta
p = self.sigmoid(z)
# 損失計算(交差エントロピー + L2正則化)
loss = -np.mean(y * np.log(p + 1e-7) +
(1 - y) * np.log(1 - p + 1e-7))
loss += self.lambda_ * np.sum(self.beta[1:]**2) / (2 * n)
self.loss_history.append(loss)
# 勾配計算
gradient = X_with_bias.T @ (p - y) / n
# L2正則化項の勾配
gradient[1:] += self.lambda_ * self.beta[1:] / n
# パラメータ更新
self.beta -= self.lr * gradient
# 収束判定
if epoch > 0 and abs(self.loss_history[-1] - self.loss_history[-2]) < 1e-6:
print(f"収束しました(エポック {epoch})")
break
def predict_proba(self, X):
"""確率予測"""
X_with_bias = np.c_[np.ones(X.shape[0]), X]
return self.sigmoid(X_with_bias @ self.beta)
def predict(self, X, threshold=0.5):
"""クラス予測"""
return (self.predict_proba(X) >= threshold).astype(int)
多クラス分類への拡張
One-vs-Rest(OvR)
$K$ クラス分類を $K$ 個の2値分類問題として解く:
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsRestClassifier
# K個の2値分類器を学習
ovr = OneVsRestClassifier(LogisticRegression())
ovr.fit(X_train, y_train)
ソフトマックス回帰(多項ロジスティック回帰)
$K$ クラスの確率を同時にモデル化:
損失関数(交差エントロピー):
ここで $y_{ik}$ はone-hotエンコーディング。
実装例
def softmax(z):
"""ソフトマックス関数(数値的に安定)"""
z_exp = np.exp(z - np.max(z, axis=1, keepdims=True))
return z_exp / np.sum(z_exp, axis=1, keepdims=True)
class MulticlassLogisticRegression:
def __init__(self, n_classes, learning_rate=0.01, epochs=1000):
self.n_classes = n_classes
self.lr = learning_rate
self.epochs = epochs
def fit(self, X, y):
n, p = X.shape
# One-hot encoding
Y = np.eye(self.n_classes)[y]
# パラメータ初期化(各クラスに対して)
self.W = np.zeros((p + 1, self.n_classes))
X_with_bias = np.c_[np.ones(n), X]
for epoch in range(self.epochs):
# 予測確率
Z = X_with_bias @ self.W
P = softmax(Z)
# 勾配
gradient = X_with_bias.T @ (P - Y) / n
# 更新
self.W -= self.lr * gradient
def predict_proba(self, X):
X_with_bias = np.c_[np.ones(X.shape[0]), X]
Z = X_with_bias @ self.W
return softmax(Z)
def predict(self, X):
return np.argmax(self.predict_proba(X), axis=1)
特徴量の重要度と解釈
係数の解釈
ロジスティック回帰の係数 $\beta_j$ は対数オッズの変化を表す:
- $\beta_j > 0$:特徴量 $x_j$ が増加すると、クラス1の確率が増加
- $\beta_j < 0$:特徴量 $x_j$ が増加すると、クラス1の確率が減少
- $|\beta_j|$:影響の強さ
オッズ比での解釈: $x_j$ が1単位増加したときのオッズ比の変化 = $e^{\beta_j}$
特徴量重要度の可視化
import matplotlib.pyplot as plt
import pandas as pd
def plot_feature_importance(model, feature_names):
"""係数の可視化"""
coef = model.beta[1:] # バイアス項を除く
# データフレーム作成
importance_df = pd.DataFrame({
'feature': feature_names,
'coefficient': coef,
'abs_coefficient': np.abs(coef),
'odds_ratio': np.exp(coef)
}).sort_values('abs_coefficient', ascending=True)
# プロット
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 係数
axes[0].barh(importance_df['feature'], importance_df['coefficient'])
axes[0].axvline(x=0, color='black', linestyle='--', alpha=0.5)
axes[0].set_xlabel('係数')
axes[0].set_title('ロジスティック回帰の係数')
# オッズ比
axes[1].barh(importance_df['feature'], importance_df['odds_ratio'])
axes[1].axvline(x=1, color='black', linestyle='--', alpha=0.5)
axes[1].set_xlabel('オッズ比')
axes[1].set_title('オッズ比(exp(係数))')
plt.tight_layout()
return importance_df
正則化とパラメータ調整
L1正則化(Lasso)
スパースな解(多くの係数が0)を得る:
L2正則化(Ridge)
係数の大きさを制限:
Elastic Net
L1とL2の組み合わせ:
交差検証による選択
from sklearn.linear_model import LogisticRegressionCV
from sklearn.model_selection import GridSearchCV
# L2正則化の強さを交差検証で選択
model = LogisticRegressionCV(
Cs=np.logspace(-4, 4, 20), # 正則化パラメータの候補
cv=5, # 5分割交差検証
penalty='l2',
solver='liblinear',
random_state=42
)
model.fit(X_train, y_train)
print(f"最適な正則化パラメータ: C={model.C_[0]:.4f}")
print(f"交差検証スコア: {model.scores_[1].mean():.3f}")
実装例:信用リスク評価
# データ準備
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, roc_auc_score, roc_curve
# 合成データ生成(信用リスクを模擬)
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=15,
n_redundant=5,
n_classes=2,
weights=[0.7, 0.3], # 不均衡データ
random_state=42
)
# データ分割と標準化
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# モデル学習
model = LogisticRegression(learning_rate=0.1, epochs=1000, regularization=0.01)
model.fit(X_train_scaled, y_train)
# 予測と評価
y_pred_proba = model.predict_proba(X_test_scaled)
y_pred = model.predict(X_test_scaled)
# 評価指標
print("分類レポート:")
print(classification_report(y_test, y_pred))
print(f"\nAUC-ROC: {roc_auc_score(y_test, y_pred_proba):.3f}")
# ROC曲線の描画
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, label=f'ROC Curve (AUC = {roc_auc_score(y_test, y_pred_proba):.3f})')
plt.plot([0, 1], [0, 1], 'k--', label='Random')
plt.xlabel('偽陽性率(FPR)')
plt.ylabel('真陽性率(TPR)')
plt.title('ROC曲線')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 閾値の調整
best_threshold = thresholds[np.argmax(tpr - fpr)]
print(f"\n最適な閾値: {best_threshold:.3f}")
利点と欠点
関連教材(青の統計学)
利点
- 確率的予測:分類結果だけでなく確信度も得られる
- 解釈性:係数から特徴量の影響を理解できる
- 計算効率:凸最適化問題で大域最適解が保証される
- 正則化:過学習を防ぐ仕組みが組み込みやすい
欠点
- 線形分離仮定:非線形な決定境界を扱えない
- 特徴量エンジニアリング:適切な特徴量変換が必要
- 外れ値の影響:極端な値に敏感
- 多重共線性:相関の高い特徴量で不安定
非線形への拡張
from sklearn.preprocessing import PolynomialFeatures
# 多項式特徴量の生成
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X)
# 非線形決定境界の学習が可能に
model_poly = LogisticRegression()
model_poly.fit(X_poly, y)
まとめ
ロジスティック回帰は、線形モデルの解釈性を保ちながら確率的な分類を実現する強力な手法です。シグモイド関数により線形予測を確率に変換し、最尤推定により最適なパラメータを学習します。
重要なポイント:
- シグモイド関数により $[0, 1]$ の確率予測が可能
- 係数はオッズ比の対数として解釈できる
- 多クラス分類にはソフトマックス回帰を使用
- 正則化により過学習を防ぎ、特徴選択も可能
次章では、非線形な決定境界を扱える「決定木とランダムフォレスト」について学習します。