アンサンブル学習
機械学習において、単一のモデルの限界を打破する手法がアンサンブル学習です。複数のモデルを組み合わせることで、個々のモデルの弱点を補完し合い、より安定した高性能なモデルを構築できます。本章では、アンサンブル学習の理論的基盤から実用的な手法まで体系的に学習します。
アンサンブル学習の基本原理
なぜアンサンブルが有効なのか
アンサンブル学習の効果を理解するために、まず「集合知の原理」について考えてみましょう。これは、複数の「専門家」の意見を統合することで、個々の専門家よりも優れた判断を得られるという考え方です。日常生活でも、重要な決定をする際に複数の人に相談し、その意見を総合して判断することがありますが、これと同じ原理が機械学習においても成り立ちます。
統計学的な観点から見ると、この効果はより具体的に説明できます。個々のモデルが行う予測には必然的に誤差が含まれますが、これらの誤差が互いに独立であると仮定できる場合、複数のモデルの予測を平均することで全体の分散を大幅に削減することができます。中心極限定理が示すように、独立な確率変数の平均は、個々の変数よりもはるかに安定した値を示します。
数学的に表現すると、$n$個のモデルの平均予測$\bar{Y}$の分散は、個々のモデルの予測$Y$の分散の$1/n$倍になります:
これは、モデル数が増加すると予測の安定性が向上することを意味しており、アンサンブル学習の理論的基盤となっています。
バイアス・バリアンス分解との関係
[図3] バイアス・バリアンス分解との関係
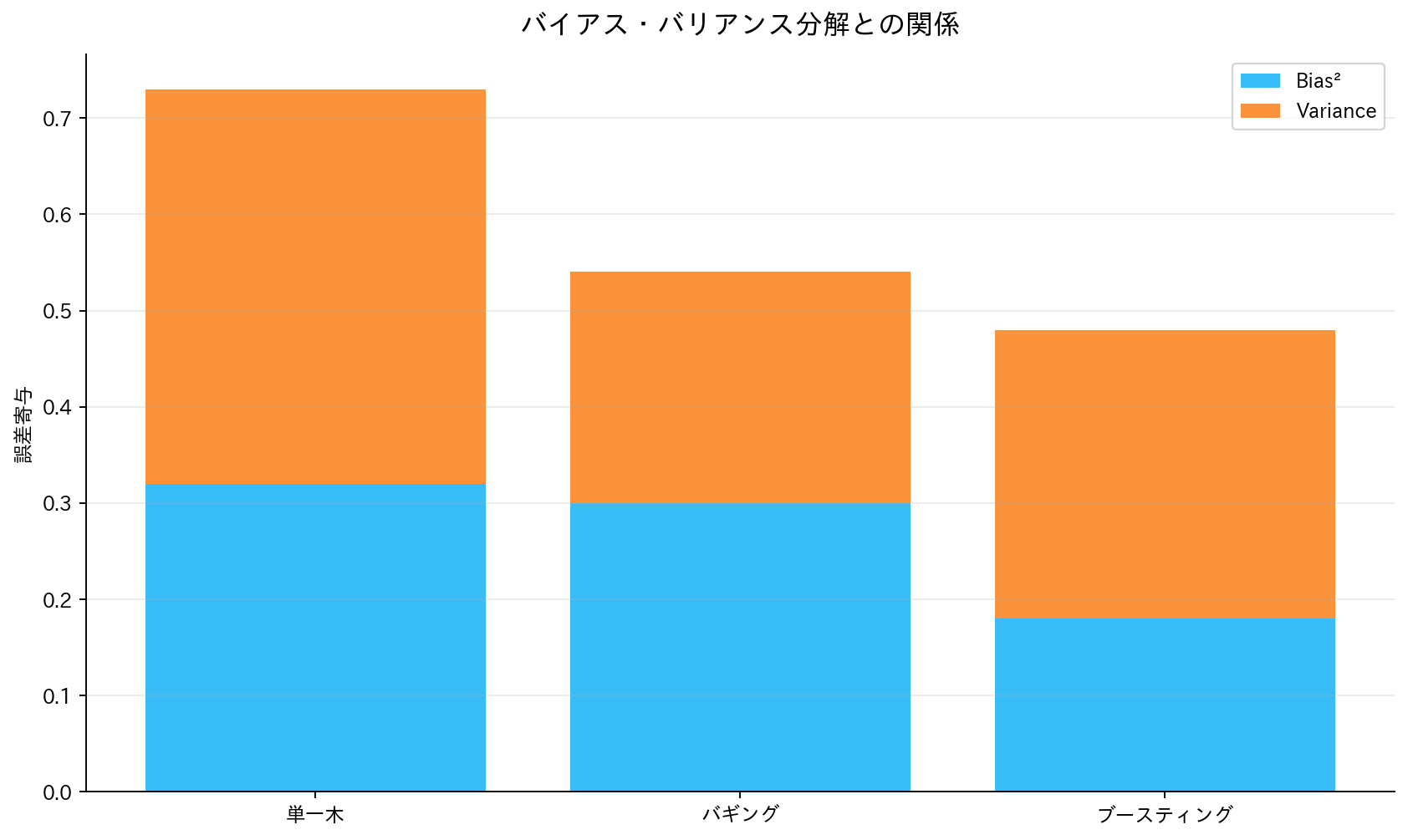
アンサンブル学習の効果をより深く理解するために、機械学習における重要な概念であるバイアス・バリアンス分解について説明します。機械学習モデルの予測誤差は、理論的に以下の3つの成分に分解することができます:
ここでバイアス(Bias)は、モデルが真の関係を捉えきれないことによる系統的な誤差を表し、バリアンス(Variance)は、訓練データの変化に対するモデルの感度を表します。ノイズ(Noise)は、データ自体に含まれる不可避の誤差です。
アンサンブル手法の主要な効果は、この分解式の中でも特にバリアンス成分の削減にあります。個々のモデルが訓練データに対して過度に敏感に反応する傾向があったとしても、複数のモデルの予測を平均化することで、このような不安定性を大幅に軽減できます。これにより、過学習を抑制し、新しいデータに対してより安定した予測を行うことが可能になります。
バギング(Bootstrap Aggregating)
関連教材(青の統計学)
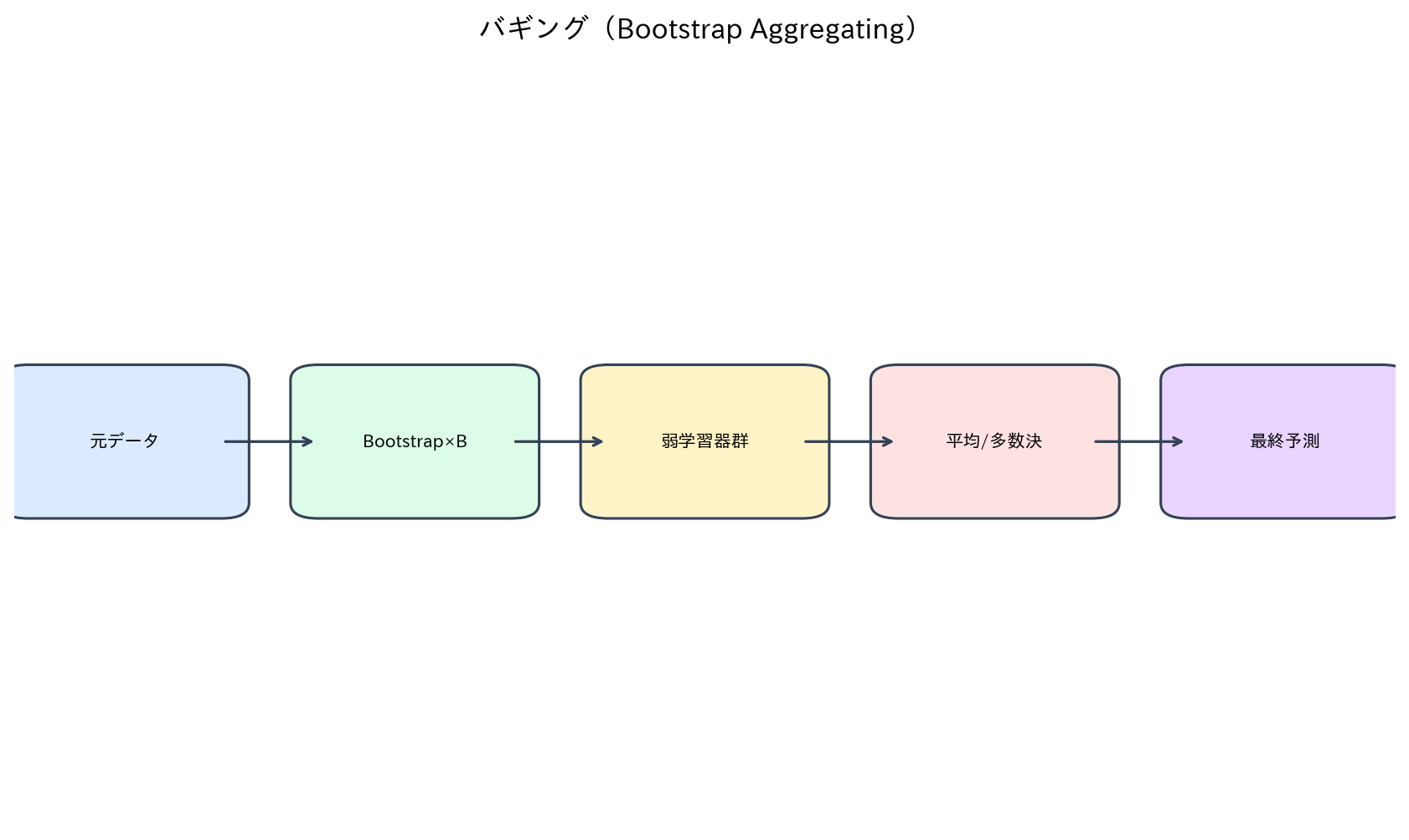
[図4] バギング(Bootstrap Aggregating)
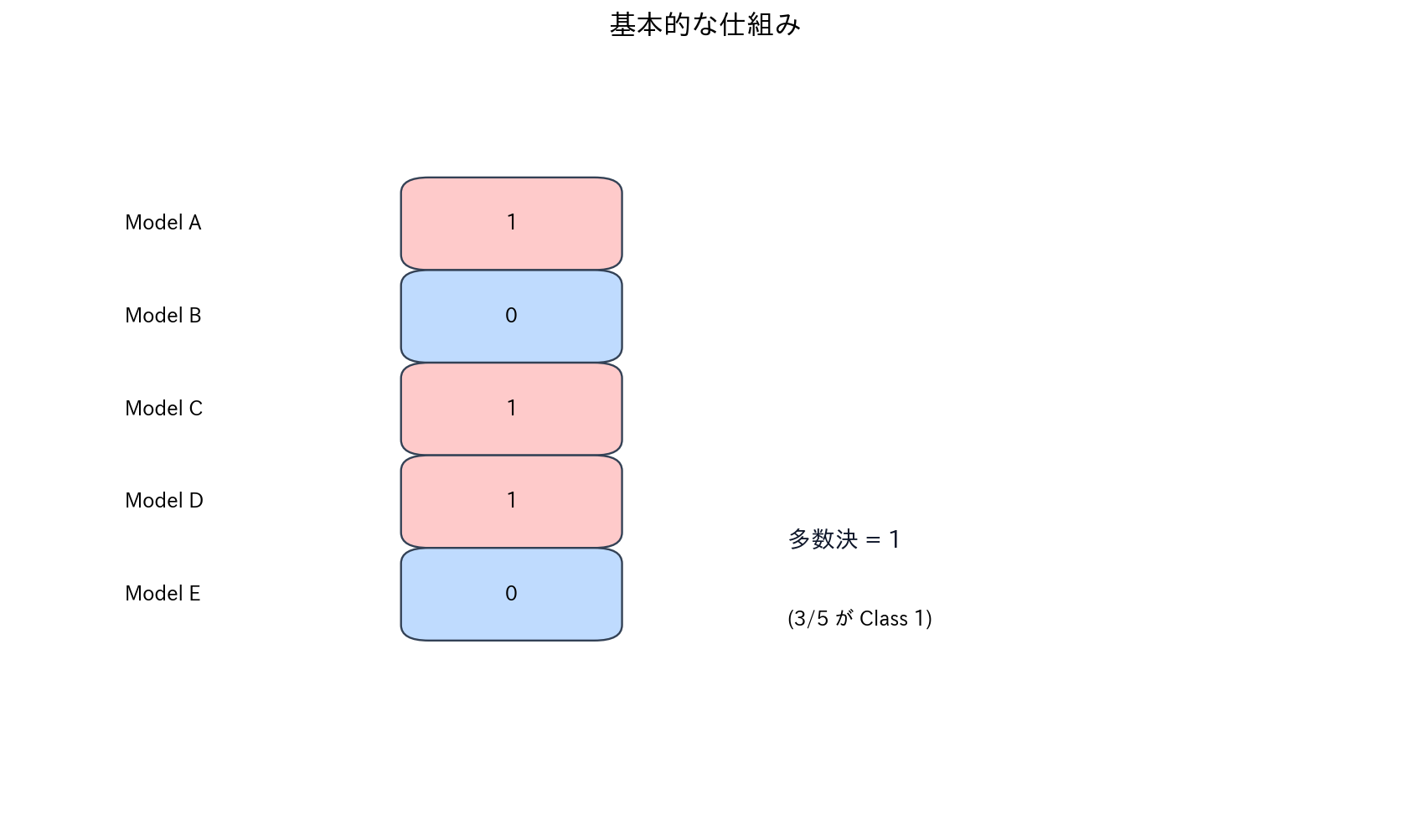
基本的な仕組み
[図5] 基本的な仕組み
バギング(Bootstrap Aggregating)は、アンサンブル学習の中でも最も基本的で理解しやすい手法の一つです。この手法の核心的なアイデアは、元のデータセットから統計学のブートストラップ法を用いて複数の異なるサンプルを作成し、それぞれのサンプルでモデルを訓練することにあります。
具体的な手順を詳しく見てみましょう。まず、元のデータセットから復元抽出(同じデータポイントを重複して選ぶことを許可)により、元のデータセットと同じサイズのブートストラップサンプルをB個作成します。この復元抽出により、各サンプルは元のデータセットとは異なる特徴を持つことになります。次に、それぞれのブートストラップサンプルを用いて同種のモデル(例えば決定木)を訓練します。最後に、予測を行う際には、全てのモデルの出力を統合します。回帰問題の場合は各モデルの予測値の平均を取り、分類問題の場合は多数決により最終的な予測を決定します。
この過程は数学的に以下のように表現されます:
ここで$\hat{f}_b(x)$は$b$番目のブートストラップサンプルで訓練されたモデルの予測値を表しています。
Random Forest
Random Forest(ランダムフォレスト)は、バギングの基本的なアイデアを決定木に適用し、さらに特徴量選択にランダム性を加えることで、より優れた性能を実現した手法です。この手法は、現在でも実用的な機械学習システムで広く使用されている非常に重要なアルゴリズムです。
Random Forestの特徴は、決定木のバギングに「特徴量ランダマイゼーション」を組み合わせた点にあります。通常のバギングでは、各モデルは全ての特徴量を使用してデータを分析しますが、Random Forestでは各決定木のノードで分割を行う際に、全特徴量の中からランダムに選択された一部の特徴量のみを候補として考慮します。一般的には、総特徴量数を$p$とした場合、$m = \sqrt{p}$個の特徴量をランダムに選択します。
この特徴量ランダマイゼーションには重要な意味があります。決定木間の相関をさらに削減することで、アンサンブル効果を最大化できるのです。また、Random Forestでは各特徴量の重要度を計算することができるため、データの理解や特徴量選択にも活用できます。さらに、Out-of-Bag(OOB)推定と呼ばれる手法により、別途テストデータを用意することなく汎化性能を評価することが可能です。
Out-of-Bag推定
Random Forestの優れた特徴の一つが、Out-of-Bag(OOB)推定による汎化性能の評価です。ブートストラップサンプリングの統計的性質により、各ブートストラップサンプルには元のデータセットの約63.2%のデータが選ばれ、残りの36.8%が除外されます。この除外されたデータをOOBサンプルと呼び、各決定木にとっては「見たことのないデータ」として機能します。
この性質を活用することで、別途検証用データを用意することなく、訓練過程でモデルの汎化性能を推定することができます。具体的には、各データポイントについて、そのデータを訓練に使用しなかった決定木のみで予測を行い、その平均を取ることで、クロス検証に近い効果を得ることができるのです。
ブースティング
関連教材(青の統計学)
基本概念
ブースティングは、バギングとは異なるアプローチを取るアンサンブル学習の手法です。この手法では、弱学習器(weak learner)と呼ばれる単純なモデルを逐次的に学習し、前のモデルが犯した誤りを次のモデルで修正していくというプロセスを繰り返します。このような「誤差の段階的修正」により、最終的に非常に高い性能を持つモデルを構築することができます。
弱学習器という概念は、ブースティングを理解する上で重要です。弱学習器とは、ランダムな推測よりもわずかに良い性能を持つ学習器のことで、二クラス分類問題の場合は精度が50%を超える程度の簡単なモデルを指します。典型的な例としては、深さ1の決定木(decision stump)があります。このような単純なモデルでも、適切に組み合わせることで強力な予測器を作ることができるのがブースティングの魅力です。
AdaBoost(Adaptive Boosting)
AdaBoost(Adaptive Boosting)は、ブースティング手法の中でも最も有名で理論的に洗練されたアルゴリズムの一つです。その名前が示すように、このアルゴリズムは学習過程で適応的(Adaptive)に改善を行います。
AdaBoostの動作原理は非常に直感的です。まず、全ての訓練データに等しい重み$w_i = \frac{1}{n}$を設定してスタートします。次に、この重み付きデータを用いて弱学習器$h_t$を学習します。学習が完了したら、このモデルがどのデータポイントを誤分類したかを確認し、誤分類されたデータの重みを増加させ、正しく分類されたデータの重みを減少させます。これにより、次の弱学習器は前のモデルが苦手とするデータにより注意を払うようになります。
さらに、各弱学習器の重要度$\alpha_t$を、その学習器の誤差率に基づいて計算します。誤差率が低い(つまり性能が良い)学習器ほど、最終的な予測において大きな影響力を持つことになります。このプロセスを$T$回繰り返した後、全ての弱学習器の重み付き投票により最終予測を決定します:
Gradient Boosting
勾配ブースティングは、損失関数の負の勾配方向に新しいモデルを学習する手法です。
手順:
- 初期予測$F_0(x) = \arg\min_{\gamma} \sum_{i=1}^{n} L(y_i, \gamma)$
- $m = 1$ to $M$まで繰り返し:
- 疑似残差を計算:$r_{im} = -\frac{\partial L(y_i, F_{m-1}(x_i))}{\partial F_{m-1}(x_i)}$
- $r_{im}$を目的変数として弱学習器$h_m$を学習
- 最適なステップサイズ$\gamma_m$を計算
- モデルを更新:$F_m(x) = F_{m-1}(x) + \gamma_m h_m(x)$
XGBoostの改良点:
- 正則化項の追加
- 二次の勾配情報(Hessian)の利用
- 欠損値の自動処理
- 並列化による高速化
スタッキング
基本的な仕組み
スタッキング(Stacked Generalization)は、複数の異種モデル(ベースモデル)の予測結果を入力として、メタモデル(ブレンダー)が最終予測を行う手法です。
2段階の学習:
- Level 0:複数のベースモデルを訓練
- Level 1:ベースモデルの予測を特徴量としてメタモデルを訓練
クロス検証による汎化: 訓練データを$K$個に分割し、各フォールドでベースモデルを学習して他のフォールドの予測を生成。これにより、メタモデル用の「未見データの予測」を作成します。
手順の詳細
- ベースモデル準備:線形回帰、SVM、Random Forest、Neural Network等
- K-fold CV実行:各フォールドで:
- ベースモデルを学習
- バリデーション部分の予測を記録
- メタ特徴量作成:全データの予測値がメタモデルの入力
- メタモデル学習:通常は単純なモデル(線形回帰、ロジスティック回帰)
- 最終予測:テストデータでベースモデル→メタモデルの順で予測
スタッキングの利点と注意点
利点:
- 異なる手法の強みを組み合わせ可能
- 理論的に個々のモデルを上回る性能
- 柔軟性が高い
注意点:
- 計算コストが高い
- 過学習のリスク(特にメタモデル)
- 解釈性の低下
コラム:アンサンブル手法の選択指針
データサイズと手法の関係
大規模データ(n > 100,000):
- バギング:並列化により効率的
- Random Forest:特徴量が多い場合に特に有効
中規模データ(1,000 < n < 100,000):
- ブースティング:精度重視の場合
- スタッキング:多様性重視の場合
小規模データ(n < 1,000):
- 単純なバギング:過学習防止
- Leave-One-Out CV + 軽量なアンサンブル
性能 vs 解釈性のトレードオフ
| 手法 | 性能 | 解釈性 | 計算コスト |
|---|---|---|---|
| Random Forest | 高 | 中(特徴量重要度) | 中 |
| XGBoost | 最高 | 中(SHAP値) | 高 |
| スタッキング | 高 | 低 | 最高 |
| 単一モデル | 中 | 高 | 低 |
コラム:ハイパーパラメータチューニング戦略
Grid Search vs Random Search vs Bayesian Optimization
Grid Search:
- パラメータ空間を格子状に探索
- 計算コストが指数的に増加
- 少数パラメータに適している
Random Search:
- ランダムにパラメータを選択
- 重要でないパラメータがある場合により効率的
- 並列化しやすい
Bayesian Optimization:
- ガウス過程等でパラメータ性能の関数を近似
- 取得関数(acquisition function)で次の探索点を決定
- 評価コストが高い場合に有効
アンサンブルでのチューニング戦略
- 個別最適化:各ベースモデルを独立にチューニング
- 全体最適化:アンサンブル全体の性能を目的関数として最適化
- 段階的最適化:ベースモデル→結合重み→メタモデルの順で最適化
実装例:
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# ベースモデルの準備
rf = RandomForestClassifier()
lr = LogisticRegression()
svc = SVC(probability=True)
# アンサンブルモデル
ensemble = VotingClassifier(
estimators=[('rf', rf), ('lr', lr), ('svc', svc)],
voting='soft'
)
# パラメータ設定
param_grid = {
'rf__n_estimators': [100, 200],
'rf__max_depth': [10, 20, None],
'lr__C': [0.1, 1.0, 10.0],
'svc__C': [0.1, 1.0, 10.0],
'svc__gamma': ['scale', 'auto']
}
# グリッドサーチ実行
grid_search = GridSearchCV(ensemble, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
実装例と比較
基本的なアンサンブル手法の比較
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import (
RandomForestClassifier,
AdaBoostClassifier,
GradientBoostingClassifier,
VotingClassifier
)
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# データ生成
X, y = make_classification(n_samples=1000, n_features=20,
n_redundant=0, n_informative=15,
random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 各手法の比較
methods = {
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'AdaBoost': AdaBoostClassifier(n_estimators=100, random_state=42),
'Gradient Boosting': GradientBoostingClassifier(n_estimators=100, random_state=42),
'Voting (Hard)': VotingClassifier([
('rf', RandomForestClassifier(n_estimators=50, random_state=42)),
('lr', LogisticRegression(random_state=42)),
('svc', SVC(kernel='rbf', random_state=42))
], voting='hard'),
'Voting (Soft)': VotingClassifier([
('rf', RandomForestClassifier(n_estimators=50, random_state=42)),
('lr', LogisticRegression(random_state=42)),
('svc', SVC(kernel='rbf', probability=True, random_state=42))
], voting='soft')
}
# 性能比較
results = {}
for name, model in methods.items():
# クロス検証
cv_scores = cross_val_score(model, X_train, y_train, cv=5)
# テストセット評価
model.fit(X_train, y_train)
test_score = accuracy_score(y_test, model.predict(X_test))
results[name] = {
'CV Mean': cv_scores.mean(),
'CV Std': cv_scores.std(),
'Test Score': test_score
}
# 結果表示
for name, scores in results.items():
print(f"{name}:")
print(f" CV: {scores['CV Mean']:.3f} ± {scores['CV Std']:.3f}")
print(f" Test: {scores['Test Score']:.3f}")
まとめ
アンサンブル学習は機械学習の性能向上において極めて重要な手法群です。重要なポイント:
- 多様性と精度のバランス:個々のモデルが異なる誤りを犯すことで全体性能が向上
- 手法の特徴理解:バギング(分散削減)、ブースティング(バイアス削減)、スタッキング(柔軟性)
- 計算コストとの兼ね合い:性能向上と計算時間・リソースのトレードオフ
- 適切な評価方法:クロス検証、OOB推定、ホールドアウト法の使い分け
これらの概念を理解することで、問題に応じた最適なアンサンブル戦略を選択し、高性能なモデルを構築できるようになります。
次章では、高次元データの次元削減と特徴量選択について学習します。