時系列解析と予測
時間軸に沿ったデータ「時系列データ」は、金融、気象、売上、センサーデータなど様々な分野で収集されます。時系列解析は、過去のパターンから未来を予測し、ビジネス戦略やリスク管理において重要な役割を果たします。本章では、時系列データの特徴から古典的手法、機械学習アプローチまで体系的に学習します。
時系列データの特徴
関連教材(青の統計学)
基本的な性質
時系列データは、時間$t$における観測値$y_t$の系列$\{y_1, y_2, \ldots, y_T\}$として定義されます。このデータには、通常の機械学習で扱う独立同分布データとは根本的に異なる特殊な性質があります。
最も重要な特徴は時間依存性です。時系列データでは、隣接する時点の観測値の間には強い相関関係が存在し、この時間的な相関構造が予測の鍵となります。この性質により、通常の機械学習で前提とされる「各データポイントが独立同分布に従う」という仮定が成立しません。
時系列データには、しばしば長期的な傾向であるトレンドと、一定期間で繰り返される周期的なパターンである季節性が含まれています。例えば、小売業の売上データでは年末に増加するという季節性があり、人口統計では長期的な増加トレンドが観察されます。さらに、これらの規則的なパターンに加えて、予測困難なランダム成分(ノイズ)も含まれています。
時系列の成分分解
[図1] 時系列分解(トレンド・季節性・残差)
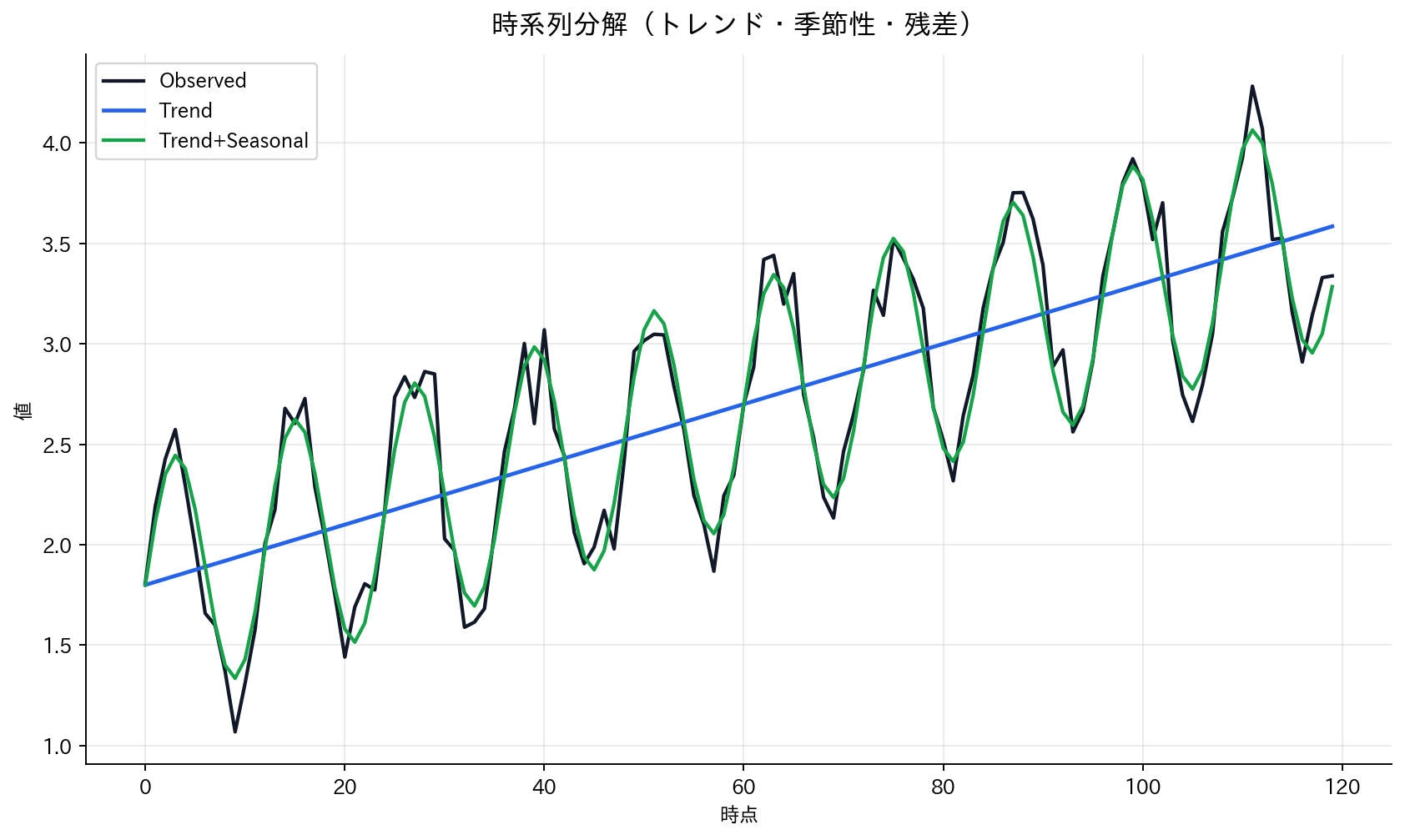
時系列データの理解と分析を容易にするため、観測値を複数の成分に分解することが一般的です。この分解方法には主に2つのモデルがあります。
加法モデルでは、各成分が独立に時系列に加算されると仮定します:
一方、乗法モデルでは、各成分が相互に影響し合って全体の変動を形成すると考えます:
ここで、$T_t$はトレンド成分(長期的な変動傾向)、$S_t$は季節成分(周期的な変動パターン)、$I_t$は不規則成分(予測不可能なランダムノイズ)を表しています。この成分分解により、時系列の構造をより深く理解し、適切なモデリング手法を選択することが可能になります。
定常性
[図2] 定常性の確認と差分化
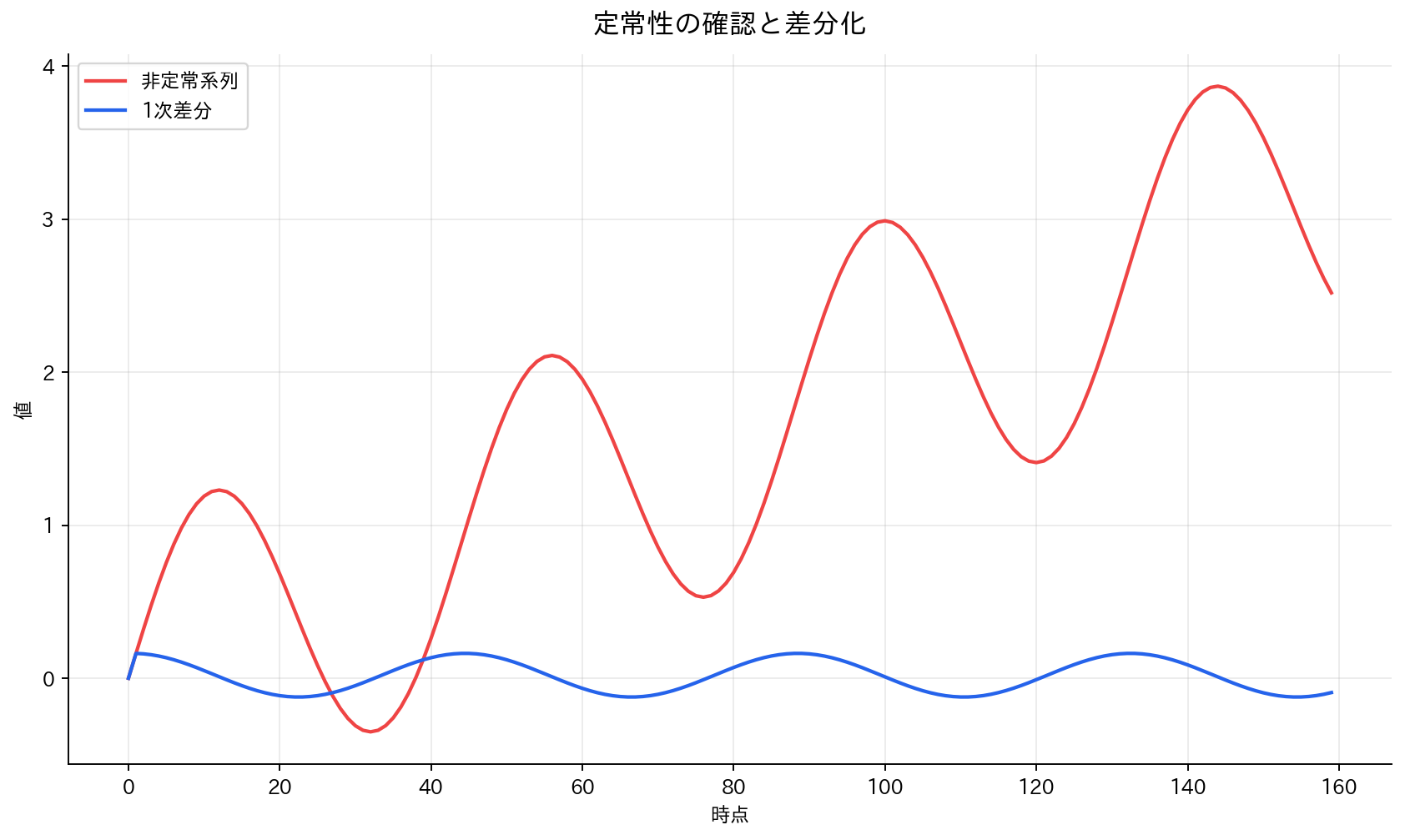
弱定常性(共分散定常性)の条件:
- 平均の一定性:$E[y_t] = \mu$(全ての$t$で一定)
- 分散の一定性:$\text{Var}(y_t) = \sigma^2$(全ての$t$で一定)
- 自己共分散の時間不変性:$\text{Cov}(y_t, y_{t-k}) = \gamma_k$(ラグ$k$のみに依存)
定常化の手法:
- 差分化:$\Delta y_t = y_t - y_{t-1}$
- 対数変換:$\log(y_t)$(分散安定化)
- 季節差分:$\Delta_s y_t = y_t - y_{t-s}$
古典的時系列モデル
自己回帰モデル(AR)
AR(p)モデル:
特性方程式:
定常性条件:全ての根が単位円の外側に存在
自己相関関数(ACF):
AR(p)では、ACFは指数的に減衰する傾向を示します。
移動平均モデル(MA)
MA(q)モデル:
可逆性条件:
偏自己相関関数(PACF): MA(q)では、ラグ$q$以降のPACFが0になります。
ARMA・ARIMAモデル
[図3] ARIMA(p,d,q)モデルの構造
ARMA(p,q)モデル:
ARIMA(p,d,q)モデル: $d$次差分により定常化したARMA(p,q)モデル
ARIMAを平易に言うと、「トレンドは差分で除去し、残った定常的なゆらぎを自己回帰(AR)とショックの残響(MA)で表す」モデルです。
つまり、時系列をいきなり複雑モデルで当てるのではなく、先に定常化してから構造を当てにいくのが古典時系列の基本戦略です。
季節ARIMAモデル SARIMA(p,d,q)(P,D,Q)s:
ここで:
- $(p,d,q)$:非季節成分のオーダー
- $(P,D,Q)$:季節成分のオーダー
- $s$:季節周期
- $B$:後退オペレーター
モデル選択
Box-Jenkins法:
- 識別:ACF・PACF図からモデルの候補を選択
- 推定:最尤法等でパラメータを推定
- 診断:残差の白色ノイズ性を検証
情報量基準:
- AIC:$\text{AIC} = 2k - 2\ln(L)$
- BIC:$\text{BIC} = k\ln(n) - 2\ln(L)$
ここで$k$はパラメータ数、$L$は尤度、$n$はサンプルサイズです。
状態空間モデル
カルマンフィルタ
状態空間モデルは、「観測される値」と「直接は見えない内部状態」を分けて考える枠組みです。
売上やセンサー値の背後には、需要水準・トレンド・季節強度のような潜在状態があるとみなし、それを逐次推定します。
言い換えると、状態空間モデルは次の2層構造です。
- システムの内部で何が起きるか:状態方程式
- 内部状態が観測値としてどう見えるか:観測方程式
状態方程式:
観測方程式:
ここで:
- $x_t$:状態ベクトル
- $u_t$:制御入力
- $w_t, v_t$:ガウシアンノイズ
$F_t$ は「前時点の状態がどう遷移するか」、$H_t$ は「状態がどのように観測へ写るか」を表す行列です。
数学的背景としては、線形代数(行列による状態遷移)と確率論(ノイズ付き動的システム)が合わさったモデルだと捉えると理解しやすくなります。
カルマンフィルタのアルゴリズム:
予測ステップ:
更新ステップ:
この更新式の要点は、予測誤差(イノベーション) をどれだけ信じるかをカルマンゲイン $K_t$ が決める点です。
観測ノイズ $R_t$ が大きいと観測をあまり信じず、状態予測側を重視します。逆に観測が高精度なら、観測に強く引き寄せて更新します。
実務では「予測モデル」と「観測モデル」の両方を設計する必要があり、どちらか片方だけ精密でも安定しません。
そのため状態空間モデルは、時系列の予測だけでなく、ノイズ除去・欠損補完・異常検知でも強力です。
指数平滑法との関係
単純指数平滑法:
これは特別なケースの状態空間モデルと等価です。
つまり指数平滑法は経験則ではなく、状態推定の理論で裏づけられた手法だと解釈できます。
Holt-Wintersモデル:
- レベル:$\ell_t = \alpha y_t + (1-\alpha)(\ell_{t-1} + b_{t-1})$
- トレンド:$b_t = \beta(\ell_t - \ell_{t-1}) + (1-\beta)b_{t-1}$
- 季節:$s_t = \gamma(y_t - \ell_t) + (1-\gamma)s_{t-m}$
機械学習アプローチ
特徴量エンジニアリング
ラグ特徴量:
時間ベース特徴量:
- 曜日、月、四半期
- 祝日フラグ
- 時間帯ダミー
統計的特徴量:
- 移動平均:$\text{MA}_k(t) = \frac{1}{k}\sum_{i=0}^{k-1} y_{t-i}$
- 移動標準偏差
- 指数移動平均:$\text{EMA}_t = \alpha y_t + (1-\alpha)\text{EMA}_{t-1}$
差分・変換特徴量:
- 前期比:$(y_t - y_{t-1})/y_{t-1}$
- 前年同期比:$(y_t - y_{t-12})/y_{t-12}$
- Box-Cox変換
リカレントニューラルネットワーク
[図5] LSTMによる系列予測の流れ
LSTM(Long Short-Term Memory):
# LSTMセルの基本構造
f_t = σ(W_f · [h_{t-1}, x_t] + b_f) # 忘却ゲート
i_t = σ(W_i · [h_{t-1}, x_t] + b_i) # 入力ゲート
C̃_t = tanh(W_C · [h_{t-1}, x_t] + b_C) # 新しい候補値
C_t = f_t * C_{t-1} + i_t * C̃_t # セル状態更新
o_t = σ(W_o · [h_{t-1}, x_t] + b_o) # 出力ゲート
h_t = o_t * tanh(C_t) # 隠れ状態
GRU(Gated Recurrent Unit): LSTMの簡略版で、計算効率が良い
Seq2Seqモデル: エンコーダー・デコーダー構造で多期間予測
Attention機構
Transformer(時系列版):
# Self-Attentionによる時系列モデル
Attention(Q, K, V) = softmax(QK^T / √d_k)V
# 位置エンコーディング
PE(pos, 2i) = sin(pos / 10000^{2i/d_model})
PE(pos, 2i+1) = cos(pos / 10000^{2i/d_model})
利点:
- 長期依存関係の捕捉
- 並列計算可能
- 解釈可能性の向上
コラム:予測精度の評価
時系列特有の評価手法
[図4] 時系列予測のローリング評価
時系列クロス検証:
# 時系列分割による評価
for train_end in range(min_train_size, len(data) - test_size):
train = data[:train_end]
test = data[train_end:train_end + test_size]
model.fit(train)
predictions = model.predict(test)
scores.append(evaluate(test, predictions))
評価指標:
- MAPE:$\frac{100}{n}\sum_{t=1}^{n}\left|\frac{y_t - \hat{y}_t}{y_t}\right|$
- sMAPE:$\frac{100}{n}\sum_{t=1}^{n}\frac{|y_t - \hat{y}_t|}{(|y_t| + |\hat{y}_t|)/2}$
- MASE:季節性を考慮した相対評価
予測区間:
ここで$\sigma_h$は$h$期先予測の標準誤差です。
実業務での注意点
データドリフト:
- 概念ドリフト:予測対象の性質変化
- 分布ドリフト:入力データの分布変化
定期的な再学習:
# オンライン学習の例
if (current_time - last_retrain) > retrain_interval:
# 最新データで再学習
recent_data = get_recent_data(window_size)
model.retrain(recent_data)
last_retrain = current_time
コラム:多変量時系列と因果推論
関連教材(青の統計学)
Vector AutoRegression(VAR)
VAR(p)モデル:
グランジャー因果性: 変数$x$が変数$y$をグランジャー因果する条件:
構造的因果モデル
差分の差分法(Difference-in-Differences):
合成統制法(Synthetic Control): 処理群に類似した統制群を複数の未処理単位の重み付き組み合わせで構成
実装例
ARIMAモデルの実装と評価
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.stats.diagnostic import acorr_ljungbox
from sklearn.metrics import mean_squared_error, mean_absolute_error
import warnings
warnings.filterwarnings('ignore')
# サンプルデータ生成(売上データのシミュレーション)
np.random.seed(42)
n_periods = 365
dates = pd.date_range('2020-01-01', periods=n_periods, freq='D')
# トレンド + 季節性 + ノイズ
trend = np.linspace(100, 150, n_periods)
seasonal = 10 * np.sin(2 * np.pi * np.arange(n_periods) / 365.25 * 2)
weekly = 5 * np.sin(2 * np.pi * np.arange(n_periods) / 7)
noise = np.random.normal(0, 5, n_periods)
y = trend + seasonal + weekly + noise
ts_data = pd.Series(y, index=dates)
# 時系列の可視化
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 元データ
axes[0, 0].plot(ts_data)
axes[0, 0].set_title('原時系列データ')
axes[0, 0].set_xlabel('時間')
axes[0, 0].set_ylabel('売上')
# 成分分解
decomposition = seasonal_decompose(ts_data, model='additive', period=7)
decomposition.plot()
plt.tight_layout()
plt.show()
# ACF・PACF分析
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
plot_acf(ts_data, lags=40, ax=ax1, title='自己相関関数')
plot_pacf(ts_data, lags=40, ax=ax2, title='偏自己相関関数')
plt.tight_layout()
plt.show()
# 差分による定常化
ts_diff = ts_data.diff().dropna()
# ARIMAモデルの自動選択
def select_arima_model(data, max_p=3, max_d=2, max_q=3):
best_aic = float('inf')
best_params = None
for p in range(max_p + 1):
for d in range(max_d + 1):
for q in range(max_q + 1):
try:
model = ARIMA(data, order=(p, d, q))
fitted_model = model.fit()
if fitted_model.aic < best_aic:
best_aic = fitted_model.aic
best_params = (p, d, q)
except:
continue
return best_params, best_aic
# 最適パラメータ選択
train_size = int(len(ts_data) * 0.8)
train_data = ts_data[:train_size]
test_data = ts_data[train_size:]
best_params, best_aic = select_arima_model(train_data)
print(f"最適ARIMA parameters: {best_params}, AIC: {best_aic:.2f}")
# モデル学習と予測
model = ARIMA(train_data, order=best_params)
fitted_model = model.fit()
# 予測
forecast_steps = len(test_data)
forecast = fitted_model.forecast(steps=forecast_steps)
forecast_ci = fitted_model.get_forecast(steps=forecast_steps).conf_int()
# 評価指標計算
rmse = np.sqrt(mean_squared_error(test_data, forecast))
mae = mean_absolute_error(test_data, forecast)
mape = np.mean(np.abs((test_data - forecast) / test_data)) * 100
print(f"\n予測精度:")
print(f"RMSE: {rmse:.2f}")
print(f"MAE: {mae:.2f}")
print(f"MAPE: {mape:.2f}%")
# 予測結果の可視化
plt.figure(figsize=(12, 6))
plt.plot(train_data.index, train_data, label='訓練データ', color='blue')
plt.plot(test_data.index, test_data, label='実測値', color='green')
plt.plot(test_data.index, forecast, label='予測値', color='red', linestyle='--')
plt.fill_between(test_data.index,
forecast_ci.iloc[:, 0],
forecast_ci.iloc[:, 1],
color='red', alpha=0.2, label='95% 予測区間')
plt.xlabel('時間')
plt.ylabel('売上')
plt.title('ARIMA予測結果')
plt.legend()
plt.grid(True)
plt.show()
# 残差診断
residuals = fitted_model.resid
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 残差プロット
axes[0, 0].plot(residuals)
axes[0, 0].set_title('残差プロット')
# Q-Qプロット
from scipy import stats
stats.probplot(residuals, dist="norm", plot=axes[0, 1])
axes[0, 1].set_title('Q-Qプロット')
# 残差ACF
plot_acf(residuals, lags=20, ax=axes[1, 0], title='残差ACF')
# 残差ヒストグラム
axes[1, 1].hist(residuals, bins=20, density=True, alpha=0.7)
axes[1, 1].set_title('残差ヒストグラム')
plt.tight_layout()
plt.show()
# Ljung-Box検定(残差の独立性検定)
lb_test = acorr_ljungbox(residuals, lags=10, return_df=True)
print(f"\nLjung-Box検定 p-value: {lb_test['lb_pvalue'].iloc[-1]:.4f}")
if lb_test['lb_pvalue'].iloc[-1] > 0.05:
print("残差は白色ノイズ(モデル適合良好)")
else:
print("残差に系列相関あり(モデル改良必要)")
LSTMによる時系列予測
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from sklearn.preprocessing import MinMaxScaler
# データ前処理
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(ts_data.values.reshape(-1, 1))
def create_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
X.append(data[i:(i + seq_length), 0])
y.append(data[i + seq_length, 0])
return np.array(X), np.array(y)
# シーケンス作成
seq_length = 30 # 30日間の履歴を使用
X, y = create_sequences(scaled_data, seq_length)
# 訓練・テスト分割
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# データの形状変更(LSTM用)
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
# LSTMモデル構築
model = Sequential([
LSTM(50, return_sequences=True, input_shape=(seq_length, 1)),
Dropout(0.2),
LSTM(50, return_sequences=False),
Dropout(0.2),
Dense(25),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
# モデル学習
history = model.fit(
X_train, y_train,
batch_size=32,
epochs=50,
validation_split=0.1,
verbose=0
)
# 予測
lstm_predictions = model.predict(X_test)
# スケール戻し
lstm_predictions = scaler.inverse_transform(lstm_predictions)
y_test_actual = scaler.inverse_transform(y_test.reshape(-1, 1))
# LSTM評価
lstm_rmse = np.sqrt(mean_squared_error(y_test_actual, lstm_predictions))
lstm_mae = mean_absolute_error(y_test_actual, lstm_predictions)
lstm_mape = np.mean(np.abs((y_test_actual - lstm_predictions) / y_test_actual)) * 100
print(f"\nLSTM予測精度:")
print(f"RMSE: {lstm_rmse:.2f}")
print(f"MAE: {lstm_mae:.2f}")
print(f"MAPE: {lstm_mape[0]:.2f}%")
# 予測結果の比較可視化
plt.figure(figsize=(12, 6))
# テストデータの日付を調整
test_start_idx = train_size + seq_length
test_dates = ts_data.index[test_start_idx:test_start_idx + len(y_test_actual)]
plt.plot(ts_data.index[:train_size], ts_data[:train_size],
label='訓練データ', color='blue')
plt.plot(test_dates, y_test_actual,
label='実測値', color='green')
plt.plot(test_dates, lstm_predictions,
label='LSTM予測', color='purple', linestyle='--')
plt.xlabel('時間')
plt.ylabel('売上')
plt.title('LSTM vs ARIMA 予測比較')
plt.legend()
plt.grid(True)
plt.show()
# 学習曲線
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('モデル学習曲線')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# モデル比較
plt.subplot(1, 2, 2)
methods = ['ARIMA', 'LSTM']
rmse_scores = [rmse, lstm_rmse]
mae_scores = [mae, lstm_mae]
x = np.arange(len(methods))
width = 0.35
plt.bar(x - width/2, rmse_scores, width, label='RMSE', alpha=0.8)
plt.bar(x + width/2, mae_scores, width, label='MAE', alpha=0.8)
plt.xlabel('手法')
plt.ylabel('誤差')
plt.title('予測精度比較')
plt.xticks(x, methods)
plt.legend()
plt.tight_layout()
plt.show()
print(f"\n手法比較:")
print(f"ARIMA - RMSE: {rmse:.2f}, MAE: {mae:.2f}")
print(f"LSTM - RMSE: {lstm_rmse:.2f}, MAE: {lstm_mae:.2f}")
まとめ
時系列解析は過去のデータから未来を予測する重要な分析技術です。重要なポイント:
- 時系列の特徴理解:定常性、トレンド、季節性、自己相関の概念
- 古典手法の基盤:ARIMA、状態空間モデルの理論的背景
- 機械学習の活用:特徴量エンジニアリング、深層学習手法の適用
- 適切な評価方法:時系列分割、予測区間、複数指標による評価
- 実用上の考慮:データドリフト、再学習、多変量・因果関係の分析
これらの概念を理解することで、ビジネスデータの時系列パターンを捉え、精度の高い予測モデルを構築できるようになります。
機械学習基礎カリキュラムのStage 2が完成しました。次のステージでは、より高度な手法や実応用について学習します。