コンピュータビジョン
この章で学ぶこと
- 画像の数学的表現(テンソル・畳み込み)を式で説明できる
- CNN/検出/セグメンテーションの違いと評価指標を理解する
- IoU・mAP・PQ などの指標を、目的に応じて使い分けられる
- 推論速度と精度のトレードオフを踏まえて手法選択できる
前提知識チェック
- 線形代数:行列積、畳み込みの離散表現
- 微分:勾配降下法、逆伝播の基本
- 深層学習:CNN・正則化・転移学習
学習目標
コンピュータビジョン(Computer Vision)は、画像や動画から有用な情報を自動的に抽出・理解する技術分野です。本章では、基本的な画像処理技術から最新の深層学習を用いた手法まで、視覚情報処理技術を包括的に学習します。
1. コンピュータビジョンの基礎
1.1 画像の数学的表現
[図2] 画像テンソル表現(H×W×C)
デジタル画像は、二次元配列として数学的に表現されます。グレースケール画像は各画素(ピクセル)の輝度値を0-255の整数で表現し、カラー画像はRGB(赤・緑・青)の3つのチャンネルを持つ三次元配列となります。画像の座標系は通常、左上を原点(0,0)とし、右方向をx軸正方向、下方向をy軸正方向として定義されます。
画像テンソルは
と書けます。正規化は一般に
で行い、学習の安定化に寄与します。
画像の解像度は、水平方向と垂直方向のピクセル数で表され、画質と処理負荷のトレードオフを決定します。高解像度画像ほど詳細な情報を含みますが、計算コストが大幅に増加します。また、画像の色空間(Color Space)は、色の表現方法を定義し、RGB以外にもHSV(色相・彩度・明度)、LAB、YUVなどが用途に応じて使い分けられます。
画像データの前処理では、正規化(0-1範囲への変換)、平均減算、標準偏差正規化などが一般的に行われます。これらの処理により、異なる照明条件や撮影環境による影響を軽減し、機械学習アルゴリズムの性能を向上させることができます。
1.2 基本的な画像処理
フィルタリングは、画像の各画素とその近傍画素に対して、重み行列(カーネル)を適用する処理です。線形フィルタには、平滑化フィルタ(ノイズ除去)、エッジ検出フィルタ(Sobel、Canny)、シャープニングフィルタなどがあります。非線形フィルタとしては、メディアンフィルタ(インパルスノイズ除去)やモルフォロジー処理(膨張・収縮)が重要です。
幾何学的変換には、平行移動、回転、スケーリング、せん断などがあります。これらの変換は、同次座標系を用いることで行列演算として統一的に表現できます。アフィン変換は平行線を保持し、射影変換はより一般的な透視変換を含みます。画像の補間方法としては、最近傍補間、双線形補間、双三次補間などが使用されます。
ヒストグラム処理は、画像の輝度分布を分析・調整する手法です。ヒストグラム均等化により、コントラストの低い画像を改善できます。また、適応的ヒストグラム均等化(CLAHE)は、局所領域ごとに処理を行うことで、より自然な結果を得ることができます。
1.3 特徴抽出の古典的手法
エッジ検出は、画像中の輝度変化が大きい部分を抽出する処理で、物体の境界や形状の把握に重要です。Cannyエッジ検出器は、ガウシアンフィルタによるノイズ除去、勾配計算、非最大値抑制、ヒステリシス閾値処理の段階を経て、細くて連続性の高いエッジを検出します。
コーナー検出は、エッジの交点や曲率の高い点を検出する手法で、Harris corner detector、FAST、SIFTなどが代表的です。これらの特徴点は、画像のスケールや回転に対してロバストな特性を持ち、画像マッチングやトラッキングに利用されます。
テクスチャ解析では、画像の表面パターンを定量化します。Gray-Level Co-occurrence Matrix(GLCM)は、空間的な画素値の関係性から統計的特徴を抽出します。Local Binary Pattern(LBP)は、各画素を中心とした局所パターンを効率的に符号化し、照明変化に対してロバストなテクスチャ記述子として広く使用されます。
2. 畳み込みニューラルネットワーク
関連教材(青の統計学)
2.1 CNNの基本構造
[図3] 畳み込みとプーリングの流れ
畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)は、画像の局所的な空間構造を効率的に学習できる深層学習アーキテクチャです。畳み込み層では、重み共有により位置不変性を実現し、局所受容野の概念により空間的階層性を学習します。
畳み込み演算は、入力画像とフィルタ(カーネル)の要素ごとの積和として定義されます。複数のフィルタを用いることで、エッジ、コーナー、テクスチャなど様々な特徴を同時に検出できます。畳み込みの出力サイズは、入力サイズ、フィルタサイズ、ストライド(移動幅)、パディング(画像端の処理)によって決定されます。
出力サイズ(高さ方向)は
で与えられます。幅方向も同様です。
プーリング層は、空間的なダウンサンプリングを行い、計算量の削減と位置のずれに対するロバスト性を向上させます。最大プーリングは局所領域の最大値を選択し、平均プーリングは平均値を計算します。近年では、学習可能なパラメータを持つストライド付き畳み込みがプーリングの代替として使用されることも増えています。
2.2 代表的なCNNアーキテクチャ
LeNetは、1998年に提案された最初期の実用的CNNで、手書き文字認識に成功しました。そのシンプルな構造は、畳み込み層、プーリング層、全結合層の基本的な組み合わせを示し、後のCNN発展の礎となりました。
AlexNetは、2012年のImageNet競技で圧倒的な性能差を示し、深層学習ブームの火付け役となりました。ReLU活性化関数、Dropout、GPUを活用した並列処理、データ拡張などの技術を導入し、従来手法を大幅に上回る精度を達成しました。
VGGNetは、小さな3×3フィルタを重ねることで深いネットワークを構築し、受容野を拡大する手法を提案しました。この設計思想は、計算効率と表現能力のバランスが良く、現在でも多くのアーキテクチャの基礎となっています。
ResNetは、残差接続(skip connection)を導入することで、非常に深いネットワークの学習を可能にしました。勾配消失問題を解決し、152層という深層ネットワークでも効果的な学習を実現し、画像認識の精度を大幅に向上させました。
2.3 最新のCNN技術
Attention機構をCNNに組み込んだSENet(Squeeze-and-Excitation Networks)は、チャンネル間の重要度を学習し、有用な特徴チャンネルを強調します。この手法により、追加パラメータを最小限に抑えながら性能向上を実現できます。
EfficientNetは、ネットワークの深さ、幅、解像度を効率的にスケーリングする手法を提案し、精度と計算効率のバランスを最適化しました。複合スケーリング法により、限られた計算リソースで最大の性能を引き出すことができます。
Vision Transformer(ViT)は、Transformerアーキテクチャを画像認識に適用した手法で、画像をパッチに分割し、系列データとして処理します。十分な量の事前学習データがあれば、従来のCNNを上回る性能を示すことが確認されています。
3. 物体検出
関連教材(青の統計学)
3.1 物体検出の概要
[図4] 物体検出(IoUとNMS)
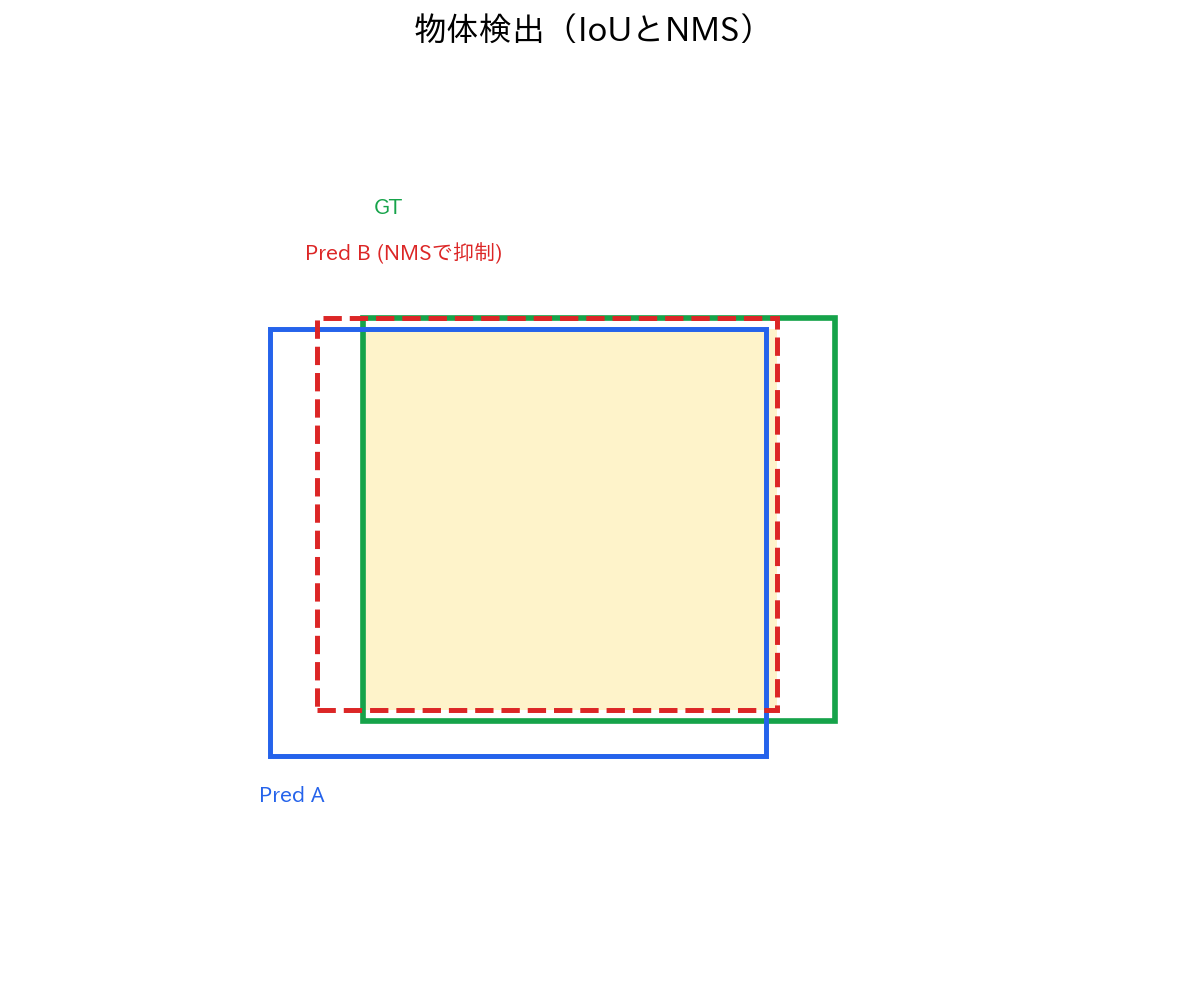
物体検出は、画像中に存在する物体の位置(バウンディングボックス)とカテゴリを同時に予測するタスクです。画像分類が画像全体を一つのカテゴリに分類するのに対し、物体検出では複数の物体を個別に認識し、その位置を正確に特定する必要があります。
評価指標としては、IoU(Intersection over Union)が基本となります。IoUは、予測ボックスと正解ボックスの重複領域と結合領域の比率で、0から1の値を取ります。通常、IoU > 0.5を正解とし、Precision、Recall、AP(Average Precision)、mAP(mean Average Precision)などの指標で性能を評価します。
また、クラス数を $C$ とすると
で定義され、検出精度の総合指標として使われます。
物体検出の課題には、スケールの多様性(同じ物体でも遠近により大きさが変化)、遮蔽(物体の一部が隠れる)、複雑な背景、物体の変形などがあります。これらの課題に対処するため、多様なデータ拡張、マルチスケール学習、困難な負例の重点学習などの手法が開発されています。
3.2 Two-Stage検出器
R-CNNは、物体検出を領域提案と分類の2段階に分けるアプローチを確立しました。Selective Searchによる候補領域生成、CNNによる特徴抽出、SVMによる分類、回帰による位置調整の段階を経て物体検出を行います。しかし、計算コストが高く、実時間処理は困難でした。
Fast R-CNNは、画像全体に対して一度だけCNN特徴抽出を行い、RoI(Region of Interest)プーリングにより各候補領域の特徴を効率的に取得する手法を提案しました。また、分類と位置回帰を統合したマルチタスク学習により、精度と効率を両立させました。
Faster R-CNNは、Region Proposal Network(RPN)を導入し、候補領域生成もニューラルネットワークで学習可能にしました。RPNは、各位置でアンカーボックス(事前定義された様々なサイズ・縦横比のボックス)を基準に、物体の有無と位置調整を予測します。この統合により、エンドツーエンドの学習が可能になりました。
3.3 One-Stage検出器
YOLOは、物体検出を単一回帰問題として定式化し、画像を格子に分割して各セルで物体の有無、クラス、位置を直接予測します。リアルタイム処理を重視した設計で、速度面で大きな優位性を持ちますが、小さな物体の検出精度に課題がありました。
SSDは、異なる解像度の特徴マップで予測を行うことで、多様なスケールの物体を効率的に検出します。浅い層では大きな物体を、深い層では小さな物体を検出し、YOLOの小物体検出の課題を改善しました。また、アンカーボックスの概念を導入し、検出精度を向上させました。
FocalLossを導入したRetinaNetは、正負の不均衡問題(背景クラスが圧倒的多数)を解決し、One-Stage検出器でもTwo-Stage検出器に匹敵する精度を実現しました。FocalLossは、易しい例の寄与を減らし、困難な例に注意を集中させることで、効果的な学習を促進します。
4. セグメンテーション
4.1 セマンティックセグメンテーション
[図5] セグメンテーション手法の比較
セマンティックセグメンテーションは、画像の各ピクセルにクラスラベルを割り当てるタスクで、物体の正確な形状を把握できます。物体検出がボックス単位の粗い位置情報しか提供しないのに対し、セグメンテーションはピクセル単位の詳細な境界を特定します。
Fully Convolutional Network(FCN)は、従来のCNNの全結合層を畳み込み層に置き換え、任意サイズの入力に対してピクセル単位の予測を可能にしました。アップサンプリングにより元の解像度に復元し、skip connectionにより異なる解像度の特徴を統合します。
U-Netは、医用画像セグメンテーションで大きな成功を収めたアーキテクチャで、エンコーダー・デコーダー構造と詳細なskip connectionが特徴です。少ないデータでも高精度なセグメンテーションを実現し、医学・生物学分野で広く採用されています。
DeepLabシリーズは、atrous convolution(dilated convolution)によりフィールドを拡大し、Conditional Random Field(CRF)により境界を精細化します。また、Atrous Spatial Pyramid Pooling(ASPP)により、複数スケールの文脈情報を効率的に統合します。
4.2 インスタンスセグメンテーション
インスタンスセグメンテーションは、同じクラスに属する個別の物体を区別してセグメンテーションを行うタスクです。例えば、複数の人が写っている画像で、各人を別々のマスクで表現する必要があります。
Mask R-CNNは、Faster R-CNNにマスク予測ブランチを追加したアーキテクチャで、物体検出とセグメンテーションを統合しています。RoIAlign(RoIプーリングの改良版)により、ピクセル精度のアライメントを実現し、高品質なマスクを生成します。
PANet(Path Aggregation Network)は、特徴伝播の改善によりMask R-CNNの性能を向上させました。FPN(Feature Pyramid Network)にボトムアップパスを追加し、低レベル特徴の利用効率を高めています。
最近のSOLO(Segmenting Objects by Locations)やSOLOv2は、インスタンスセグメンテーションを位置ベースの分類問題として定式化し、シンプルで効率的なアプローチを提案しています。
4.3 パノプティックセグメンテーション
パノプティックセグメンテーションは、セマンティックセグメンテーション(背景クラス)とインスタンスセグメンテーション(前景オブジェクト)を統合したタスクです。画像内のすべてのピクセルに対して、クラスとインスタンスIDの両方を予測します。
Panoptic FPNは、Mask R-CNNベースのインスタンスセグメンテーションとセマンティックセグメンテーションを並列実行し、後処理で統合します。Panoptic Quality(PQ)という新しい評価指標により、両方のタスクを統一的に評価できます。
EfficientPSは、EfficientNetバックボーンとBiFPN(Bidirectional Feature Pyramid Network)を用いて、効率的なパノプティックセグメンテーションを実現しています。精度と計算効率のバランスが優れています。
| タスク | 出力 | 代表指標 | 代表手法 |
|---|---|---|---|
| 画像分類 | 画像1枚に1ラベル | Accuracy, F1 | ResNet, ViT |
| 物体検出 | バウンディングボックス + ラベル | mAP, IoU | Faster R-CNN, YOLO |
| セマンティックセグメンテーション | 各ピクセルのクラス | mIoU | U-Net, DeepLab |
| インスタンスセグメンテーション | 物体ごとのマスク | AP(mask) | Mask R-CNN |
| パノプティックセグメンテーション | クラス + インスタンスID | PQ | Panoptic FPN |
タスク別の評価設計
コンピュータビジョンでは、同じモデルでも「何を正解とみなすか」で評価結果が大きく変わります。モデル改善に入る前に、まず評価指標を固定することが重要です。
| タスク | 最低限見る指標 | よくある誤り |
|---|---|---|
| 画像分類 | Accuracy, Macro-F1 | クラス不均衡なのにAccuracyだけで判断する |
| 物体検出 | mAP, Recall, IoU閾値別AP | mAPだけ良くて小物体のRecallが低い状態を見逃す |
| セグメンテーション | mIoU, Dice | 境界品質を見ずに平均値のみで採択する |
| パノプティック | PQ, SQ, RQ | インスタンス分離失敗を集計できていない |
[図6] 物体検出パイプライン(前処理→推論→NMS)
検出モデルで最初に固める2つの処理
def iou(box_a, box_b):
xa1, ya1, xa2, ya2 = box_a
xb1, yb1, xb2, yb2 = box_b
inter_w = max(0, min(xa2, xb2) - max(xa1, xb1))
inter_h = max(0, min(ya2, yb2) - max(ya1, yb1))
inter = inter_w * inter_h
area_a = (xa2 - xa1) * (ya2 - ya1)
area_b = (xb2 - xb1) * (yb2 - yb1)
return inter / max(area_a + area_b - inter, 1e-12)
def nms(boxes, scores, iou_th=0.5):
order = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)
keep = []
while order:
i = order.pop(0)
keep.append(i)
order = [j for j in order if iou(boxes[i], boxes[j]) < iou_th]
return keep
IoUとNMSは検出品質の土台です。ここが揺れると、アーキテクチャ比較自体が不公平になります。
[図7] 物体検出の評価(Precision-RecallとmAP)
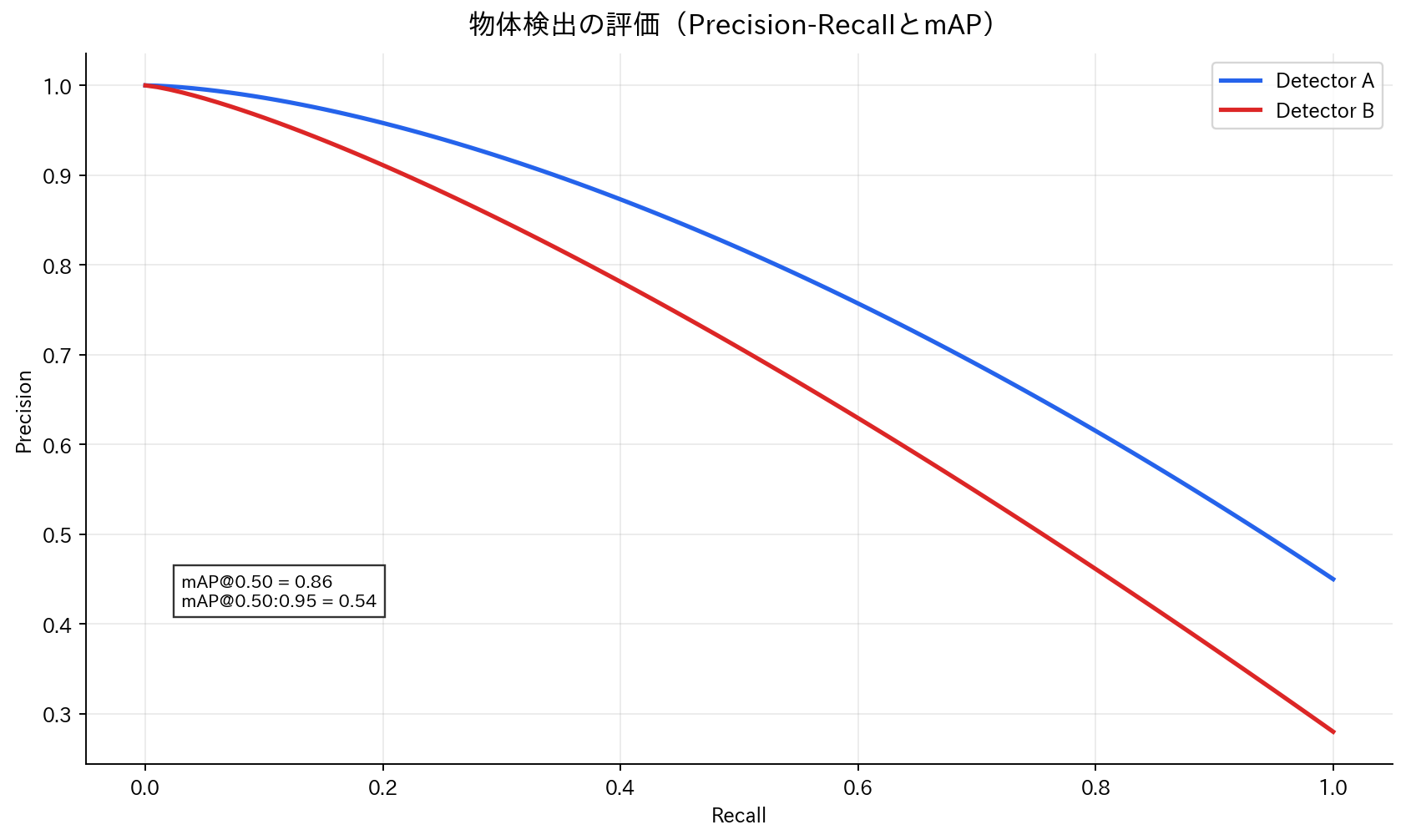
精度と速度のトレードオフを可視化する
# 実運用で使う簡易KPI集計例
metrics = {
"fps": measured_fps,
"map50_95": map50_95,
"small_object_recall": recall_small,
"false_alarm_rate": fp / max(fp + tn, 1),
}
print(metrics)
本番では fps と mAP だけでなく、誤検知率や小物体Recallまで同時監視すると、現場での体感品質に近い評価になります。
まとめ
コンピュータビジョンでは、モデルの種類より先に「タスク定義と評価設計」を揃えることが成功の鍵です。
分類・検出・セグメンテーションは出力形式と失敗モードが異なるため、共通の精度指標だけで横比較しないことが重要です。
次のステップ
機械学習基礎の締めとして、次はモデルを継続的に改善・監視する運用視点(MLOps)へ進みます。
ここまで学んだ指標設計を、監視設計と再学習フローに接続していきます。