推薦システム
現代のデジタル社会において、推薦システムは情報の過負荷を解決する重要な技術です。Eコマース、動画配信、音楽ストリーミング、ソーシャルメディアなど、様々なサービスでユーザーの満足度向上とビジネス成果の最大化に貢献しています。本章では、推薦システムの基本的なアプローチから最新の手法まで体系的に学習します。
推薦システムの基本概念
問題設定
[図1] 問題設定:ユーザー×アイテム行列
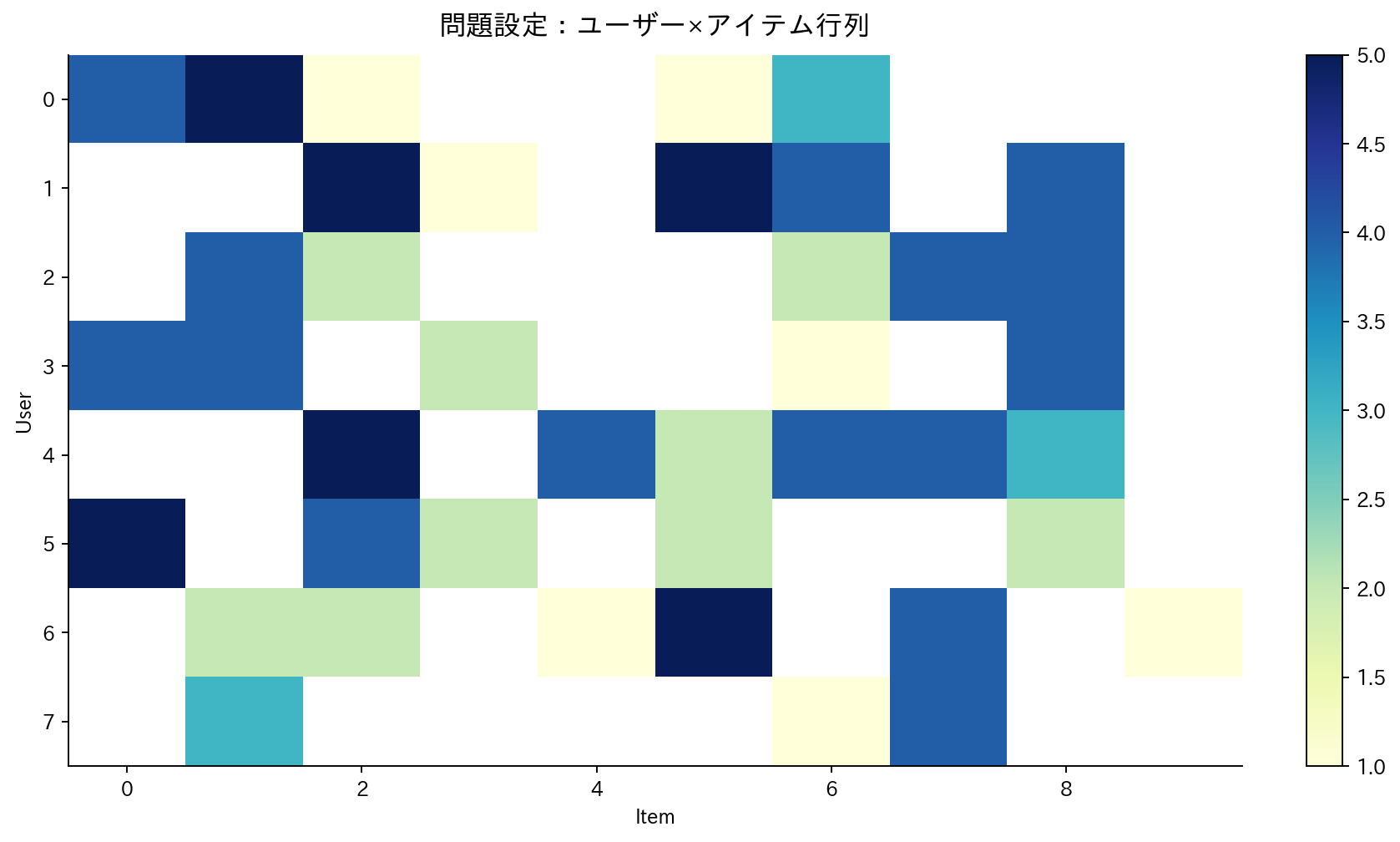
推薦システムの核心的な問題は、膨大な選択肢の中からユーザーが興味を持ちそうなアイテムを効率的に発見・提示することです。この問題を数学的に定式化すると、ユーザー集合$U = \{u_1, u_2, \ldots, u_m\}$とアイテム集合$I = \{i_1, i_2, \ldots, i_n\}$が与えられた状況で、ユーザーとアイテムの相互作用を表す評価行列$R \in \mathbb{R}^{m \times n}$を扱うことになります。
この評価行列の特徴は、多くの要素が欠損値(未評価)であることです。なぜなら、一般的にユーザーは全アイテムのごく一部しか評価しないためです。推薦システムの主要な目標は、これらの未評価の$(u, i)$ペアに対して、ユーザー$u$がアイテム$i$に与えるであろう評価値$\hat{r}_{ui}$を予測することです。
推薦システムの分類
推薦システムは、その情報源とアプローチによって大きく3つのカテゴリーに分類することができます。
協調フィルタリング(Collaborative Filtering, CF)は、最も古典的で現在でも広く使用されている手法です。この手法の基本的な考え方は、「似たような嗜好を持つユーザーは、将来も似たようなアイテムを好むだろう」という仮定に基づいています。ユーザー間やアイテム間の類似性を計算し、それを基に推薦を行います。
内容ベース推薦(Content-Based Filtering)は、アイテム自体の特徴量とユーザーの過去の行動履歴から構築したユーザープロファイルをマッチングする手法です。この手法は新規アイテムに対しても有効であり、推薦理由の説明が比較的容易というメリットがあります。
ハイブリッド手法は、上記の複数のアプローチを組み合わせることで、個々の手法の弱点を補完し、より精度の高い推薦を実現する手法です。実際の商用システムでは、このハイブリッド手法が多く採用されています。
評価指標
予測精度指標:
- RMSE:$\sqrt{\frac{1}{|T|} \sum_{(u,i) \in T} (r_{ui} - \hat{r}_{ui})^2}$
- MAE:$\frac{1}{|T|} \sum_{(u,i) \in T} |r_{ui} - \hat{r}_{ui}|$
ランキング指標:
- Precision@K:上位K件の的中率
- Recall@K:推薦されるべきアイテムの発見率
- NDCG@K:順序を考慮した評価指標
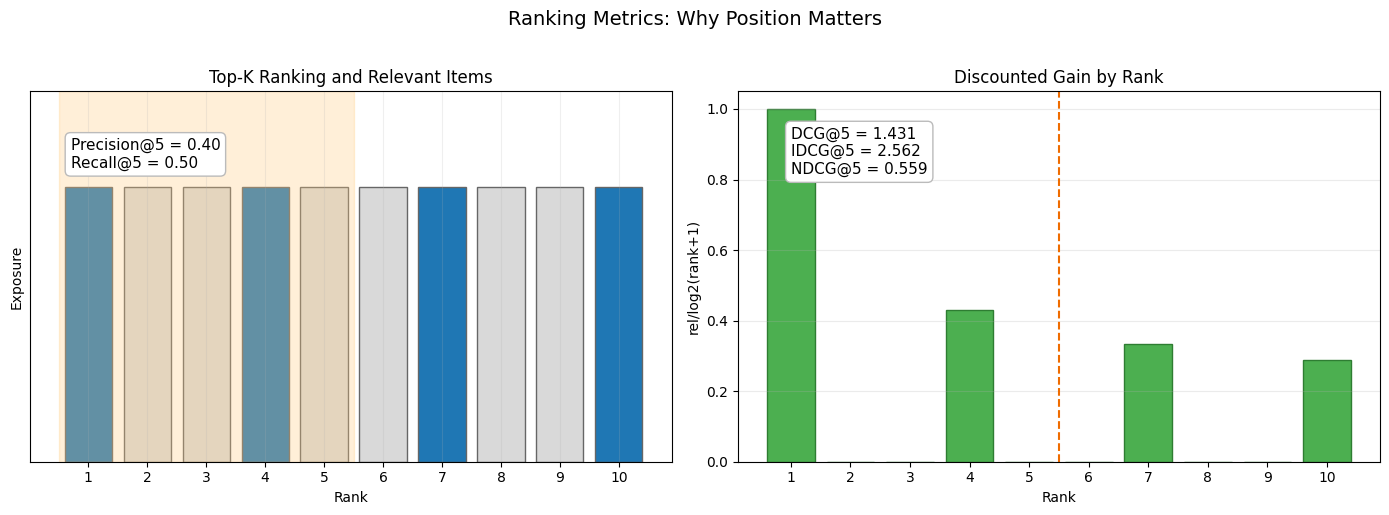
ランキング評価では、単に「正解を含んだか」だけでなく「どの順位で提示できたか」が重要です。特にUIで最初に見える数件の品質が体験を左右するため、Top-Kの定義と指標の意味をセットで理解する必要があります。
ここで $\mathrm{rel}_u(j)$ は、ユーザー $u$ に対して順位 $j$ のアイテムが関連しているか(または関連度)を表します。
DCG/NDCGでは上位順位に大きい重みがかかるため、「正解数が同じでも並び順が良い推薦」を高く評価できます。
[図6] ランキング指標(Precision/Recall/NDCG)の直感
協調フィルタリング
関連教材(青の統計学)
近傍ベース手法
[図2] 協調フィルタリングの計算フロー
ユーザーベースCF
基本アイデア: 類似したユーザーの評価を重み付き平均で予測
類似度計算(ピアソン相関係数):
ここで $I_{uv}$ は両ユーザーが評価したアイテム集合です。
予測式:
ここで $N_u(i)$ はアイテム $i$ を評価した類似ユーザー集合です。
この式で $\bar{r}_u, \bar{r}_v$ を引いている理由は、ユーザーごとの採点スケール差(甘め/厳しめ)を補正するためです。
平均との差分で比較すると「絶対評価」ではなく「相対的な好みの方向」が反映され、近傍選択の安定性が上がります。
また、共通評価数が少ないユーザー同士は類似度が偶然高くなりやすいため、実務では以下のような縮小(shrinkage)をかけることがあります。
$\beta$ は信頼度を調整するハイパーパラメータで、共通評価件数が少ない組み合わせの過信を防ぎます。
アイテムベースCF
アイテム間類似度:
予測式:
アイテムベースCFは「似ているアイテム集合から補間する」考え方なので、ユーザー数が多いサービスでも事前計算しやすい利点があります。
とくにアイテム集合が比較的安定しているドメイン(動画配信・EC商品カテゴリなど)では、ユーザーベースより運用しやすいことが多いです。
ユーザーベース vs アイテムベース
| 観点 | ユーザーベース | アイテムベース |
|---|---|---|
| 計算安定性 | 低(ユーザー嗜好変化) | 高(アイテム特性安定) |
| スパーシティ耐性 | 低 | 高 |
| 説明可能性 | 「似たユーザーが好む」 | 「似たアイテム」 |
| 適用場面 | ユーザー数 < アイテム数 | ユーザー数 > アイテム数 |
モデルベース手法
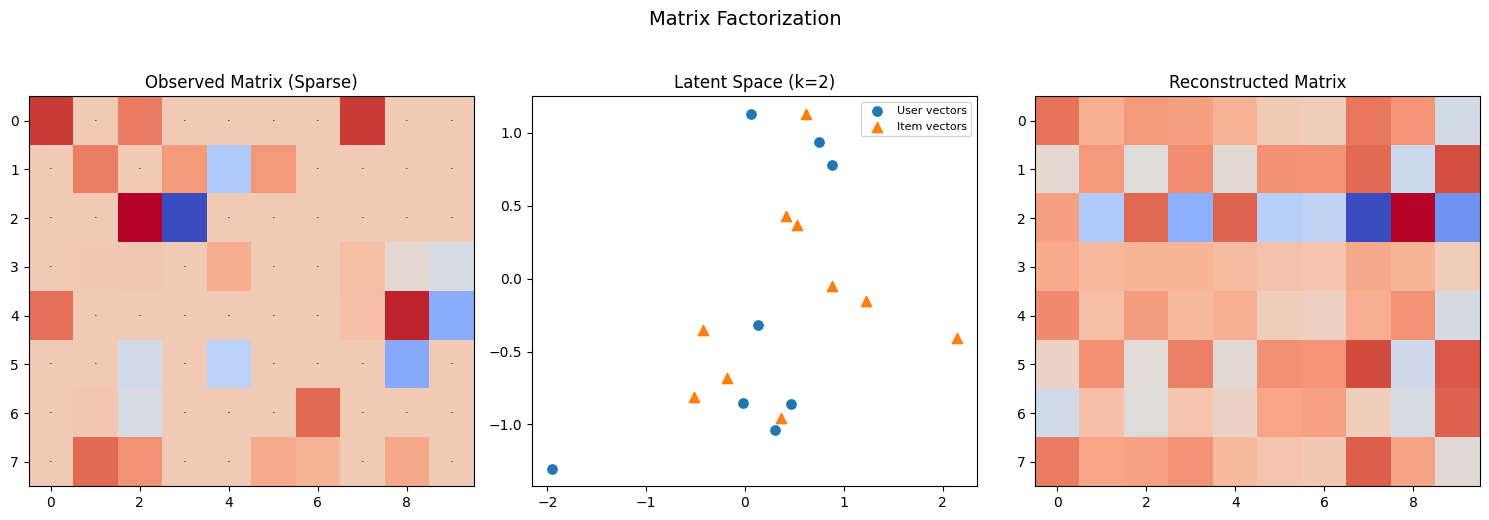
[図3] 行列分解による潜在因子モデル

行列分解(Matrix Factorization)
基本的なSVD: 評価行列 $R$ を低ランク行列に分解:
非負値行列分解(NMF):
特異値分解(SVD)での予測:
ここで:
- $\mu$:全体平均
- $b_u, b_i$:ユーザー・アイテムバイアス
- $\mathbf{p}_u, \mathbf{q}_i$:潜在因子ベクトル
最適化問題:
この最適化の第1項は観測データへの当てはまり誤差、第2項は正則化(過学習抑制)です。
正則化を入れないと、観測済み評価を過度に記憶して未知データへの予測が不安定になります。
誤差 $e_{ui}=r_{ui}-\hat{r}_{ui}$ とおくと、1サンプルに対する主要な勾配は次の形です。
したがってSGDでは、誤差で近づける更新 と 正則化で縮める更新 が同時に働きます。この2つのバランスが潜在因子の解釈性と汎化性能を決めます。
[図7] 行列分解:疎な観測から潜在空間を学習する流れ
内容ベース推薦
[図4] 内容ベース推薦の類似度計算
基本的なアプローチ
手順:
- アイテムプロファイル作成:アイテムの特徴量ベクトル化
- ユーザープロファイル構築:過去の評価から嗜好プロファイル学習
- マッチング:プロファイル間の類似度で推薦
アイテム特徴量の抽出
構造化データ:
- カテゴリカル特徴量(ジャンル、ブランド等)
- 数値特徴量(価格、サイズ等)
- ワンホットエンコーディングやembedding
テキストデータ:
TF-IDF:単語の重要度を定量化
\[ \text{TF-IDF}(t, d) = \text{TF}(t, d) \times \log\frac{N}{\text{DF}(t)} \]Word2Vec/Doc2Vec:単語・文書の分散表現
BERT等の事前学習モデル:文脈を考慮した表現
特徴量空間でのマッチングでは、コサイン類似度を使うことが多いです。
内積だけでなくベクトル長で正規化するため、文書長の違いに引きずられにくい比較ができます。
TF-IDFとコサイン類似度の組み合わせは、推薦理由を説明しやすい点でも実務価値が高いです。
ユーザープロファイル学習
加重平均法:
この式は「高評価したアイテムほどユーザープロファイルへ強く寄与させる」設計です。
一方で、評価値がノイジーな場合は外れ値の影響を受けやすいため、クリップやロバスト平均を使うこともあります。
機械学習による学習:
- ロジスティック回帰:$P(r_{ui} = 1) = \sigma(\mathbf{w}^T \mathbf{i}_i)$
- SVM、Random Forest等の分類器
内容ベース推薦の課題
限定的な発見性:
- 既存の嗜好に類似したアイテムのみ推薦
- セレンディピティ(意外な発見)の欠如
特徴量エンジニアリングの困難:
- ドメイン知識が必要
- 十分な特徴量の確保が困難
過度適合:
- 特定の特徴量に過度に依存
- 新しい嗜好の発見が困難
コラム:コールドスタート問題
関連教材(青の統計学)
[図5] コールドスタート対策の整理
推薦システムの実運用で直面する重要な課題がコールドスタート問題です。
問題の種類
新規ユーザー問題:
- 評価履歴がないユーザーへの推薦
- 人口統計学的情報の活用
- デフォルト推薦(人気アイテム等)
新規アイテム問題:
- 評価のないアイテムの推薦
- 内容ベース手法の活用
- 類似アイテムからの推論
新規システム問題:
- システム起動時のデータ不足
- 能動学習による効率的なデータ収集
対処戦略
ハイブリッド手法:
def hybrid_recommendation(user_id, cf_score, content_score, user_activity):
# ユーザー活動度に応じた重み調整
cf_weight = min(user_activity / 10.0, 1.0)
content_weight = 1.0 - cf_weight
return cf_weight * cf_score + content_weight * content_score
多段階推薦:
- 第1段階:人口統計学的セグメンテーション
- 第2段階:初期評価に基づく調整
- 第3段階:十分なデータ蓄積後にCFへ移行
コラム:深層学習ベースの推薦
AutoEncoder
Collaborative Denoising AutoEncoder (CDAE):
# ユーザーの評価ベクトルを入力とし、欠損値を補完
input_layer = Input(shape=(n_items,))
encoded = Dense(hidden_dim, activation='tanh')(input_layer)
decoded = Dense(n_items, activation='linear')(encoded)
model = Model(input_layer, decoded)
model.compile(optimizer='adam', loss='mse')
利点:
- 非線形な潜在構造の発見
- 次元削減と推薦の同時最適化
Neural Collaborative Filtering (NCF)
Multi-Layer Perceptron (MLP):
user_input = Input(shape=(), name='user_id')
item_input = Input(shape=(), name='item_id')
user_embedding = Embedding(n_users, embedding_dim)(user_input)
item_embedding = Embedding(n_items, embedding_dim)(item_input)
concat = Concatenate()([user_embedding, item_embedding])
mlp = Dense(hidden_dim, activation='relu')(concat)
output = Dense(1, activation='sigmoid')(mlp)
model = Model([user_input, item_input], output)
General Matrix Factorization (GMF) + MLP: 線形項(行列分解)と非線形項(MLP)を組み合わせ
Attention機構
アテンション重み:
応用:
- ユーザーの注意を引くアイテム特徴の特定
- 時系列データでの重要な時点の発見
実装例
基本的な協調フィルタリング
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# サンプルデータ生成
np.random.seed(42)
n_users, n_items = 100, 50
# スパースな評価行列を生成
ratings = np.zeros((n_users, n_items))
for user in range(n_users):
n_ratings = np.random.randint(5, 15) # ユーザーあたり5-15個の評価
items = np.random.choice(n_items, n_ratings, replace=False)
ratings[user, items] = np.random.randint(1, 6, n_ratings)
# ユーザーベース協調フィルタリング
class UserBasedCF:
def __init__(self, ratings_matrix):
self.ratings = ratings_matrix
self.user_similarity = None
def fit(self):
# ユーザー間の類似度計算(コサイン類似度)
# 0を除いてから類似度計算
ratings_normalized = self.ratings.copy()
ratings_normalized[ratings_normalized == 0] = np.nan
# 各ユーザーの平均評価を引く
user_means = np.nanmean(ratings_normalized, axis=1, keepdims=True)
ratings_centered = ratings_normalized - user_means
ratings_centered = np.nan_to_num(ratings_centered)
self.user_similarity = cosine_similarity(ratings_centered)
self.user_means = user_means.flatten()
def predict(self, user_id, item_id, k=10):
if self.ratings[user_id, item_id] != 0:
return self.ratings[user_id, item_id]
# アイテムを評価した類似ユーザーを見つける
item_rated_users = np.where(self.ratings[:, item_id] != 0)[0]
if len(item_rated_users) == 0:
return self.user_means[user_id]
# 類似度の高いk人を選択
similarities = self.user_similarity[user_id, item_rated_users]
top_k_indices = np.argsort(similarities)[-k:]
top_k_users = item_rated_users[top_k_indices]
top_k_similarities = similarities[top_k_indices]
# 重み付き平均で予測
if np.sum(np.abs(top_k_similarities)) == 0:
return self.user_means[user_id]
numerator = np.sum(top_k_similarities *
(self.ratings[top_k_users, item_id] -
self.user_means[top_k_users]))
denominator = np.sum(np.abs(top_k_similarities))
return self.user_means[user_id] + numerator / denominator
# 評価実行
cf_model = UserBasedCF(ratings)
cf_model.fit()
# テスト用にいくつかの評価を隠す
test_indices = []
test_actual = []
test_predicted = []
for user in range(n_users):
rated_items = np.where(ratings[user] != 0)[0]
if len(rated_items) >= 3: # 十分な評価があるユーザーのみ
test_item = np.random.choice(rated_items)
test_indices.append((user, test_item))
test_actual.append(ratings[user, test_item])
# 一時的に評価を隠す
original_rating = ratings[user, test_item]
ratings[user, test_item] = 0
# 予測
pred = cf_model.predict(user, test_item)
test_predicted.append(pred)
# 評価を戻す
ratings[user, test_item] = original_rating
# RMSE計算
rmse = np.sqrt(mean_squared_error(test_actual, test_predicted))
print(f"User-based CF RMSE: {rmse:.3f}")
行列分解の実装
class MatrixFactorization:
def __init__(self, ratings, n_factors=50, learning_rate=0.01,
regularization=0.01, n_epochs=100):
self.ratings = ratings
self.n_users, self.n_items = ratings.shape
self.n_factors = n_factors
self.learning_rate = learning_rate
self.regularization = regularization
self.n_epochs = n_epochs
# パラメータ初期化
self.user_factors = np.random.normal(0, 0.1,
(self.n_users, n_factors))
self.item_factors = np.random.normal(0, 0.1,
(self.n_items, n_factors))
self.user_bias = np.zeros(self.n_users)
self.item_bias = np.zeros(self.n_items)
self.global_bias = np.mean(ratings[ratings != 0])
def fit(self):
# 非零要素のインデックス
user_ids, item_ids = np.where(self.ratings != 0)
for epoch in range(self.n_epochs):
for idx in range(len(user_ids)):
u, i = user_ids[idx], item_ids[idx]
r_ui = self.ratings[u, i]
# 予測値計算
pred = (self.global_bias + self.user_bias[u] +
self.item_bias[i] +
np.dot(self.user_factors[u], self.item_factors[i]))
# 誤差計算
error = r_ui - pred
# 勾配更新
user_factors_old = self.user_factors[u].copy()
self.user_factors[u] += (self.learning_rate *
(error * self.item_factors[i] -
self.regularization * self.user_factors[u]))
self.item_factors[i] += (self.learning_rate *
(error * user_factors_old -
self.regularization * self.item_factors[i]))
self.user_bias[u] += (self.learning_rate *
(error - self.regularization * self.user_bias[u]))
self.item_bias[i] += (self.learning_rate *
(error - self.regularization * self.item_bias[i]))
def predict(self, user_id, item_id):
return (self.global_bias + self.user_bias[user_id] +
self.item_bias[item_id] +
np.dot(self.user_factors[user_id], self.item_factors[item_id]))
# 行列分解モデルの評価
mf_model = MatrixFactorization(ratings, n_factors=10, n_epochs=50)
mf_model.fit()
# 同じテストセットで評価
mf_predicted = []
for user, item in test_indices:
pred = mf_model.predict(user, item)
mf_predicted.append(pred)
mf_rmse = np.sqrt(mean_squared_error(test_actual, mf_predicted))
print(f"Matrix Factorization RMSE: {mf_rmse:.3f}")
# 推薦生成例
def get_recommendations(model, user_id, ratings, n_recommendations=5):
unrated_items = np.where(ratings[user_id] == 0)[0]
predictions = []
for item in unrated_items:
pred = model.predict(user_id, item)
predictions.append((item, pred))
# 予測値で降順ソート
predictions.sort(key=lambda x: x[1], reverse=True)
return predictions[:n_recommendations]
# ユーザー0への推薦
recommendations = get_recommendations(mf_model, 0, ratings)
print(f"\nUser 0への推薦:")
for item_id, score in recommendations:
print(f"Item {item_id}: {score:.3f}")
内容ベース推薦の実装
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# アイテムの内容情報(サンプル)
item_features = {
0: "action adventure movie superhero",
1: "romantic comedy love story",
2: "horror thriller scary",
3: "science fiction space future",
4: "documentary educational nature",
# ... 他のアイテム
}
class ContentBasedRecommender:
def __init__(self, item_features, ratings):
self.item_features = item_features
self.ratings = ratings
self.tfidf = TfidfVectorizer()
self.item_profiles = None
self.user_profiles = {}
def fit(self):
# アイテム特徴量のTF-IDF表現
feature_texts = [self.item_features.get(i, "")
for i in range(self.ratings.shape[1])]
self.item_profiles = self.tfidf.fit_transform(feature_texts)
# ユーザープロファイル構築
for user_id in range(self.ratings.shape[0]):
self._build_user_profile(user_id)
def _build_user_profile(self, user_id):
user_ratings = self.ratings[user_id]
rated_items = np.where(user_ratings != 0)[0]
if len(rated_items) == 0:
self.user_profiles[user_id] = np.zeros(self.item_profiles.shape[1])
return
# 評価値で重み付けした平均プロファイル
weighted_profiles = []
weights = []
for item in rated_items:
rating = user_ratings[item]
if rating >= 3: # 好意的な評価のみ使用
weighted_profiles.append(
self.item_profiles[item].toarray().flatten() * rating)
weights.append(rating)
if len(weighted_profiles) == 0:
self.user_profiles[user_id] = np.zeros(self.item_profiles.shape[1])
else:
self.user_profiles[user_id] = (
np.sum(weighted_profiles, axis=0) / np.sum(weights))
def predict(self, user_id, item_id):
if user_id not in self.user_profiles:
return 0.0
user_profile = self.user_profiles[user_id].reshape(1, -1)
item_profile = self.item_profiles[item_id].toarray()
similarity = cosine_similarity(user_profile, item_profile)[0, 0]
return similarity * 5 # 5段階評価にスケール
# 内容ベース推薦の実行
if len(item_features) >= 5:
cb_model = ContentBasedRecommender(item_features, ratings)
cb_model.fit()
print(f"\n内容ベース推薦の例:")
cb_recommendations = get_recommendations(cb_model, 0, ratings)
for item_id, score in cb_recommendations:
print(f"Item {item_id}: {score:.3f}")
まとめ
推薦システムは現代の情報社会において不可欠な技術として発展を続けています。重要なポイント:
- 手法の特徴理解:協調フィルタリング(集合知活用)、内容ベース(特徴量マッチング)、ハイブリッド(組み合わせ)
- コールドスタート問題:新規ユーザー・アイテムへの対処戦略
- 評価の複合性:精度・多様性・新規性・説明可能性のバランス
- スケーラビリティ:大規模データに対する計算効率の考慮
- 深層学習の活用:非線形関係の発見と表現学習
これらの概念を理解することで、ユーザーのニーズとビジネス目標に応じた効果的な推薦システムを設計・構築できるようになります。
次章では、時系列データの解析と予測手法について学習します。