特徴量選択と次元削減
高次元データは現代の機械学習において常に直面する課題です。多すぎる特徴量は計算コストの増大、過学習、解釈の困難さを招きます。本章では、特徴量選択(Feature Selection)と 次元削減(Dimensionality Reduction) の体系的な手法を学習し、効率的で解釈しやすいモデル構築を目指します。
次元の呪い
高次元データの問題
[図2] 次元の呪い
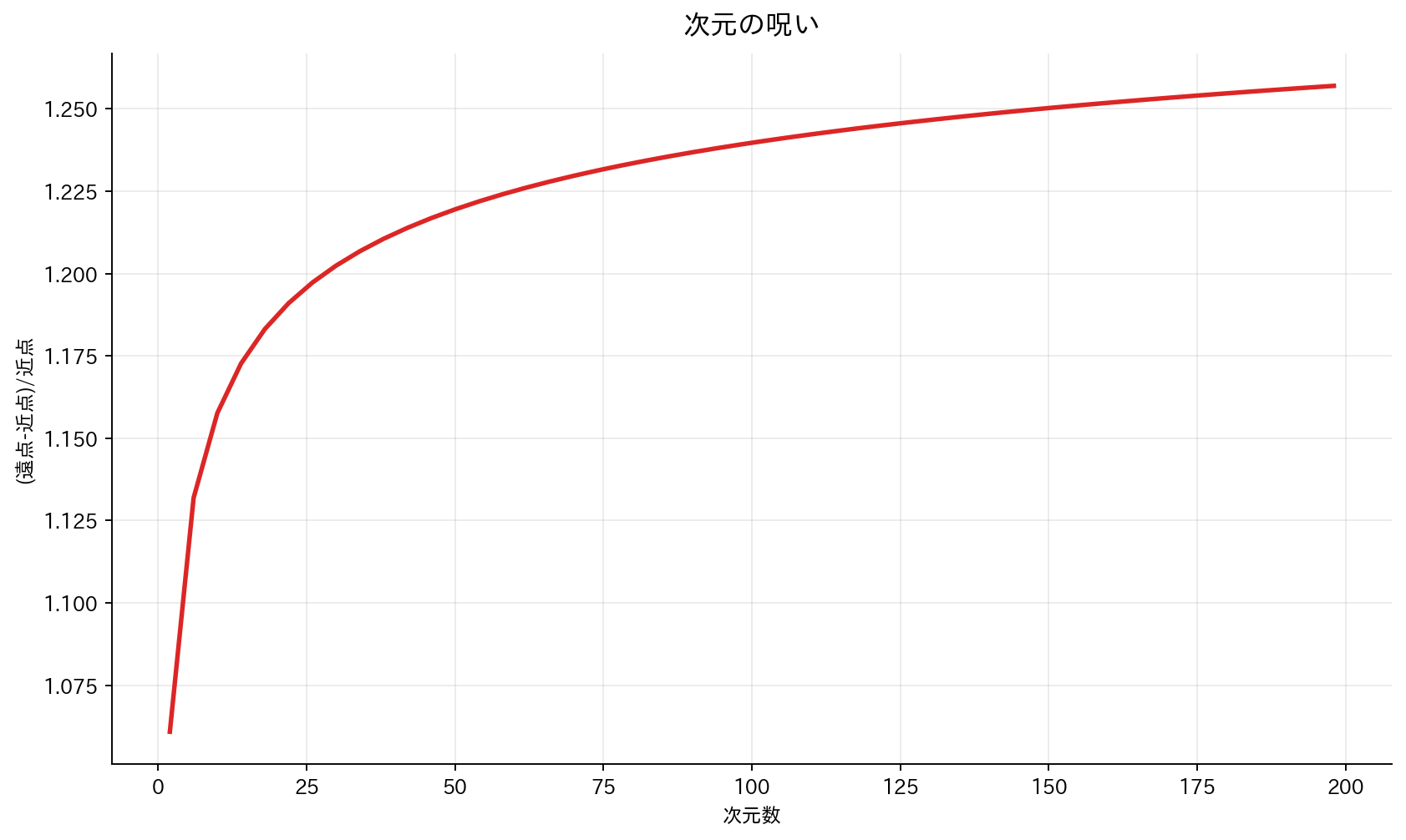
「次元の呪い(Curse of Dimensionality)」という概念は、機械学習における最も重要な課題の一つです。これは、特徴量の次元数が増加することで生じる複数の深刻な問題を総称した言葉です。
最も直感的に理解しやすい問題は、サンプル密度の希薄化です。高次元空間では、データポイント同士の距離が均一化してしまい、「近い」「遠い」という概念が意味を失ってしまいます。例えば、2次元平面では点と点の距離に明確な違いがありますが、数百次元の空間では、すべての点がほぼ同じ距離にあるように見えてしまうのです。
さらに、次元数の増加に伴い計算複雑度が指数的に増大します。これは、高次元空間を均一にサンプリングするのに必要なデータ点数が次元数に対して指数的に増加するためです。また、パラメータ数がサンプル数を超えやすくなるため、過学習が促進されるという統計的な問題も生じます。
この現象を数学的に表現すると、$d$次元単位立方体において、辺の長さが$r$の超立方体に含まれるデータの割合は次のようになります:
具体例として、$r = 0.9$(つまり各次元で90%の範囲)を考えても、$d = 10$次元では$P_{10}(0.9) = 0.35$となり、データの大部分が境界近傍に集中してしまうことが分かります。これは、高次元データの特異な性質を示す典型的な例です。
統計的な観点
次元の呪いは統計学の観点からも深刻な問題を引き起こします。最も重要な現象の一つが「有効サンプルサイズの減少」です。これは、特徴量の次元数$p$がサンプル数$n$に近づくにつれて、統計的推定の精度が急激に悪化するという現象です。
線形回帰を例に取ると、回帰係数の推定値$\hat{\beta}$の分散は次式で表されます:
ここで重要なのは、特徴量数$p$がサンプル数$n$に近づくにつれて、行列$(X^T X)$の条件数が悪化し、分散が急激に増大することです。さらに深刻なケースとして、$p > n$の場合には行列$(X^T X)$の逆行列が存在しなくなり、通常の最小二乗法では解を求めることができなくなります。これが、現代の機械学習で正則化手法が不可欠となっている理由の一つです。
特徴量選択の手法
関連教材(青の統計学)
[図4] 特徴量選択の手法
特徴量選択は、高次元データの問題に対処する最も直接的なアプローチの一つです。この手法では、元の特徴量集合から最も重要で有用な部分集合を選択することで次元を削減します。特徴量選択の大きな利点は、元の特徴量の意味を保持できるため、結果の解釈が容易であることです。
特徴量選択の手法は、その評価方法によって大きく3つのカテゴリーに分類されます:フィルタ法、ラッパー法、埋め込み法です。それぞれが異なるアプローチを取り、特定の状況で優れた性能を発揮します。
フィルタ法(Filter Methods)
[図5] フィルタ法(Filter Methods)
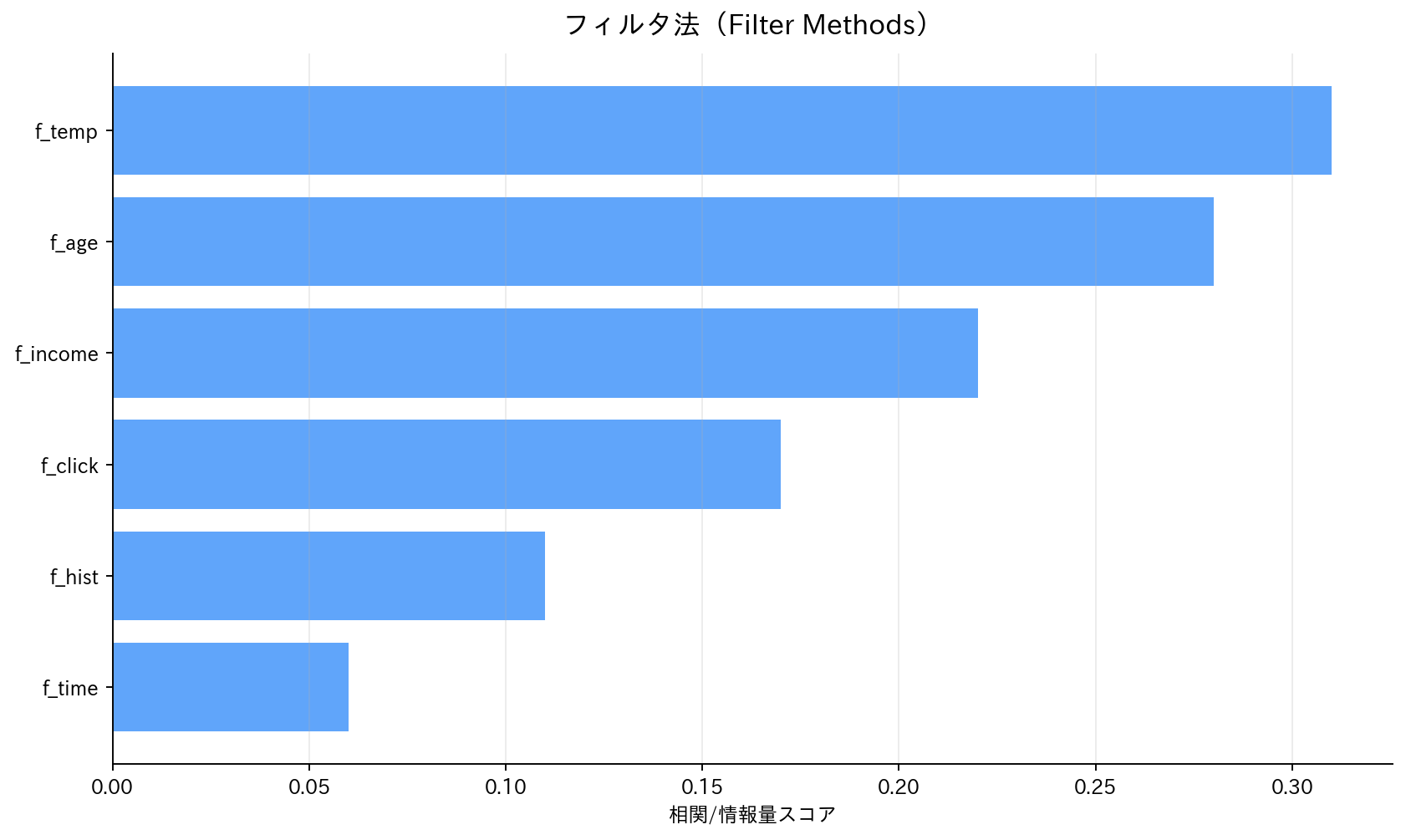
フィルタ法は、最も計算効率の良い特徴量選択手法です。この手法では、実際に機械学習モデルを訓練することなく、統計的尺度や情報理論的指標を用いて各特徴量の重要度を評価します。「フィルタ」という名前の通り、特徴量をふるいにかけて重要なものだけを残すという考え方に基づいています。
単変量検定:
- カイ二乗検定:カテゴリカル特徴量と目的変数の独立性検定
- F検定:連続特徴量と目的変数の分散比較
- 相互情報量:特徴量と目的変数の非線形関係を捉える
相関係数による選択:
- ピアソン相関:線形関係
- スピアマン相関:順序関係
- 目的変数との相関が高く、特徴量間の相関が低い変数を選択
ラッパー法(Wrapper Methods)
実際のモデルの性能を評価指標として特徴量を選択します。
前進選択法(Forward Selection):
- 空集合から開始
- 各ステップで最も性能を改善する特徴量を追加
- 性能向上が止まるまで繰り返し
後退選択法(Backward Elimination):
- 全特徴量から開始
- 各ステップで除去しても性能が最も劣化しない特徴量を削除
- 指定した数になるまで繰り返し
双方向選択法(Bidirectional): 前進と後退を組み合わせ、より柔軟な探索を実行
埋め込み法(Embedded Methods)
モデル学習と特徴量選択を同時に行う手法です。
L1正則化(Lasso):
L1ペナルティにより一部の係数が厳密に0になり、自動的な特徴量選択が実現されます。
決定木ベースの重要度:
- Gini重要度:各特徴量による不純度減少の総和
- 順列重要度:特徴量をシャッフルしたときの性能劣化
Elastic Net: L1とL2正則化の組み合わせ:
主成分分析(PCA)
関連教材(青の統計学)
前提知識のおさらい:射影と行列
PCAは「データを別の座標軸へ写し替える」手法なので、行列・内積・射影の理解が土台になります。式を見る前に、最小限の道具を整理しておきます。
- 内積:$\mathbf{a}^\top \mathbf{b}$ は「方向の一致度」を表す量
- 行列積:$XW$ は「データ $X$ を新しい軸 $W$ で表現し直す」操作
- 射影:ベクトル $\mathbf{x}$ を単位ベクトル $\mathbf{w}$ 方向へ落とすと $\mathbf{w}^\top \mathbf{x}$
特にPCAでは、各主成分方向 $\mathbf{w}_k$ に対して
という形で、元データを1次元の座標へ写します。これを複数方向で同時に行うと
となり、列ごとに「第1主成分・第2主成分…」のスコアが並びます。
つまりPCAは、複雑な変換ではなく「良い軸を選んで、そこへ射影する」操作の集まりです。
基本概念
主成分分析(Principal Component Analysis, PCA)は、次元削減の分野で最も基本的で広く使用されている手法です。PCAの基本的なアイデアは、高次元データに含まれる情報の大部分を、より少ない次元で表現できる方向(主成分)を見つけることにあります。
PCAの目的は、元の$p$次元データを$k < p$次元の空間に射影する際に、できるだけ多くの情報を保持することです。ここで「情報」とは、具体的にはデータの分散を指しています。つまり、データのばらつきを最大限保持できる射影方向を探すのがPCAの核心的なタスクです。
数学的には、データ行列$X \in \mathbb{R}^{n \times p}$に対して、適切な射影行列$W \in \mathbb{R}^{p \times k}$を求めることで、低次元表現$Z = XW$を得ます。この最適化問題は、分散最大化問題として以下のように定式化されます:
ここで$\Sigma$は元データの共分散行列であり、制約条件は射影ベクトルの長さを1に正規化することを意味しています。
固有値分解による解法
共分散行列の固有値分解:
- $U$:固有ベクトル行列(主成分方向)
- $\Lambda$:対角固有値行列(分散の大きさ)
主成分の性質:
- 直交性:異なる主成分は無相関
- 分散順序:第1主成分が最大分散、以下降順
- 全分散保存:$\sum_{i=1}^{p} \lambda_i = \text{tr}(\Sigma)$
寄与率と累積寄与率
第$i$主成分の寄与率:
累積寄与率:
一般的に累積寄与率80-90%となる次元数を選択します。
PCAの前処理
標準化の重要性: 異なるスケールの変数が混在する場合、分散の大きい変数が主成分を支配します。
標準化公式:
ここで$\bar{x}_j$は平均、$s_j$は標準偏差です。
コラム:非線形次元削減手法
t-SNE(t-Distributed Stochastic Neighbor Embedding)
t-SNEは高次元データの局所的な近傍関係を低次元で保持する手法です。
基本アイデア:
- 高次元空間での確率的近傍関係を定義
- 低次元空間で同様の近傍関係を再現
- KLダイバージェンスを最小化
高次元空間での類似度:
低次元空間での類似度:
利点と欠点:
- 利点:非線形構造の可視化に優れる
- 欠点:パラメータ調整が困難、計算コスト高、新データへの適用困難
UMAP(Uniform Manifold Approximation and Projection)
UMAPはt-SNEの改良版で、大域的構造も保持しつつ高速です。
トポロジカルデータ解析に基づく理論:
- リーマン幾何学とファジー単体複体を利用
- 大域的構造保持と計算効率を両立
コラム:実践的な次元削減戦略
手法選択の指針
線形 vs 非線形:
- データが線形部分空間に近い → PCA
- 複雑な非線形構造 → t-SNE, UMAP, オートエンコーダ
解釈性の必要性:
- 高い → 特徴量選択(特にフィルタ法)
- 中程度 → PCA(主成分の解釈可能)
- 不要 → 非線形手法
ハイブリッド手法
PCA + 特徴量選択:
- 粗い特徴量選択で明らかに不要な変数を除去
- PCAで次元削減
- 主成分に対してさらに選択を適用
段階的削減:
- フィルタ法で候補絞り込み(計算効率)
- ラッパー法で精密選択(精度重視)
- モデル内で埋め込み法による微調整
バリデーション戦略
情報漏洩の防止:
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
# 正しいパイプライン
pipeline = Pipeline([
('selection', SelectKBest(f_classif, k=50)),
('pca', PCA(n_components=10)),
('classifier', LogisticRegression())
])
# クロス検証(パイプライン全体で実行)
scores = cross_val_score(pipeline, X, y, cv=5)
実装例
包括的な次元削減比較
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, f_classif, RFE
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.manifold import TSNE
from sklearn.metrics import accuracy_score
# データ読み込み
digits = load_digits()
X, y = digits.data, digits.target
# 訓練・テスト分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# 標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 各手法の比較
methods = {
'Original': (X_train_scaled, X_test_scaled),
'PCA (95% var)': None,
'SelectKBest': None,
'RFE': None
}
# PCA実行
pca = PCA(0.95) # 95%分散保持
X_train_pca = pca.fit_transform(X_train_scaled)
X_test_pca = pca.transform(X_test_scaled)
methods['PCA (95% var)'] = (X_train_pca, X_test_pca)
print(f"PCA components: {pca.n_components_}")
# SelectKBest実行
selector = SelectKBest(f_classif, k=20)
X_train_selected = selector.fit_transform(X_train_scaled, y_train)
X_test_selected = selector.transform(X_test_scaled)
methods['SelectKBest'] = (X_train_selected, X_test_selected)
# RFE実行
estimator = LogisticRegression(random_state=42)
rfe = RFE(estimator, n_features_to_select=20)
X_train_rfe = rfe.fit_transform(X_train_scaled, y_train)
X_test_rfe = rfe.transform(X_test_scaled)
methods['RFE'] = (X_train_rfe, X_test_rfe)
# 各手法で分類性能を評価
results = {}
for method, (X_tr, X_te) in methods.items():
clf = LogisticRegression(random_state=42, max_iter=1000)
clf.fit(X_tr, y_train)
y_pred = clf.predict(X_te)
accuracy = accuracy_score(y_test, y_pred)
results[method] = {
'accuracy': accuracy,
'n_features': X_tr.shape[1]
}
# 結果表示
print("\n次元削減手法の比較:")
for method, result in results.items():
print(f"{method}: "
f"特徴量数 = {result['n_features']}, "
f"精度 = {result['accuracy']:.3f}")
# PCA寄与率の可視化
plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 1)
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('主成分数')
plt.ylabel('累積寄与率')
plt.title('PCA累積寄与率')
plt.grid(True)
# 特徴量重要度の比較
plt.subplot(1, 2, 2)
feature_importance = selector.scores_
plt.bar(range(len(feature_importance)), sorted(feature_importance, reverse=True)[:20])
plt.xlabel('特徴量ランク')
plt.ylabel('F値')
plt.title('SelectKBest特徴量重要度')
plt.tight_layout()
plt.show()
PCAによる可視化と解釈
# PCAによる2次元可視化
pca_2d = PCA(n_components=2)
X_pca_2d = pca_2d.fit_transform(X_train_scaled)
# 可視化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
scatter = plt.scatter(X_pca_2d[:, 0], X_pca_2d[:, 1], c=y_train, cmap='tab10')
plt.xlabel(f'第1主成分 (寄与率: {pca_2d.explained_variance_ratio_[0]:.1%})')
plt.ylabel(f'第2主成分 (寄与率: {pca_2d.explained_variance_ratio_[1]:.1%})')
plt.title('PCAによる2次元可視化')
plt.colorbar(scatter)
# 主成分ベクトルの可視化(最初の4x4ピクセルのみ)
plt.subplot(1, 2, 2)
component = pca_2d.components_[0].reshape(8, 8)
plt.imshow(component, cmap='RdBu')
plt.title('第1主成分の重み')
plt.colorbar()
plt.tight_layout()
plt.show()
print(f"第1主成分の寄与率: {pca_2d.explained_variance_ratio_[0]:.1%}")
print(f"第2主成分の寄与率: {pca_2d.explained_variance_ratio_[1]:.1%}")
print(f"累積寄与率: {pca_2d.explained_variance_ratio_.sum():.1%}")
まとめ
特徴量選択と次元削減は高次元データを扱う上で不可欠な手法です。重要なポイント:
- 次元の呪いの理解:高次元がもたらす計算・統計・幾何学的問題の把握
- 手法の特徴理解:特徴量選択(解釈性保持)vs 次元削減(情報集約)
- 適切な前処理:標準化、欠損値処理、外れ値除去の重要性
- 評価戦略:情報漏洩を防ぐパイプライン設計とクロス検証
- ハイブリッド手法:複数手法の組み合わせによる性能向上
これらの概念を理解することで、データの特性に応じた最適な次元削減戦略を選択し、効率的で解釈しやすいモデルを構築できるようになります。
次章では、教師なし学習の代表的手法であるクラスタリングについて学習します。