訓練・検証・テストデータの分割
機械学習モデルの真の目的は、未知のデータに対して良い予測をすることです。そのため、モデルの性能を正しく評価し、ハイパーパラメータを調整するには、データの適切な分割が不可欠です。本章では、データ分割の理論と実践について詳しく学習します。
なぜデータを分割するのか
根本的な問題
訓練に使ったデータでモデルを評価すると、過度に楽観的な結果になってしまいます。
極端な例:
訓練データ: {(x₁, y₁), (x₂, y₂), ..., (x₁₀₀, y₁₀₀)}
モデル: 訓練データを完全に暗記
評価: 訓練データで精度100%! → でも新しいデータでは...?
これは学生が過去問をただ暗記しただけで実際の試験で失敗するのと似ています。
データ分割の目的
- 公平な評価:モデルが見たことのないデータで性能を測定
- 過学習の検出:訓練データにだけ適合していないかチェック
- ハイパーパラメータ調整:適切なモデル設定の選択
3つのデータセットの役割
[図1] データ分割の概要
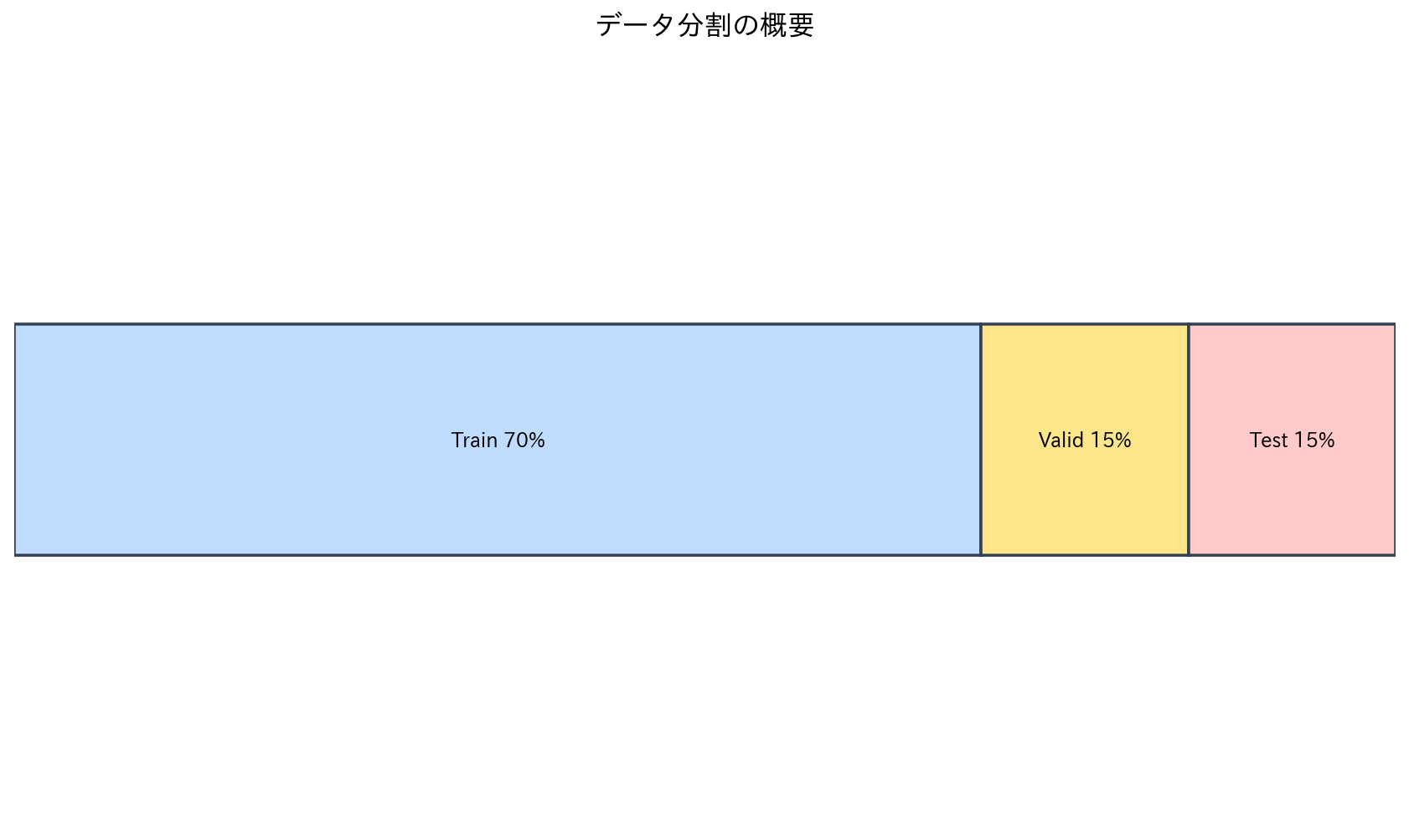
1. 訓練データ(Training Set)
- 目的:モデルのパラメータを学習
- 比率:通常60-80%
- 使用タイミング:モデルの学習時
2. 検証データ(Validation Set)
- 目的:ハイパーパラメータの調整、モデル選択
- 比率:通常10-20%
- 使用タイミング:学習中の性能監視、早期停止の判断
3. テストデータ(Test Set)
- 目的:最終的なモデル性能の評価
- 比率:通常10-20%
- 重要なルール:最後に1回だけ使用
ホールドアウト法
基本的な分割方法
最もシンプルなデータ分割方法です。
手順:
- データ全体をランダムにシャッフル
- 指定した比率で分割
- それぞれを訓練・検証・テストに割り当て
Python実装例:
from sklearn.model_selection import train_test_split
# まず訓練+検証とテストに分割(8:2)
X_temp, X_test, y_temp, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 次に訓練と検証に分割(6:2の比率になるように)
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp, test_size=0.25, random_state=42 # 0.25 * 0.8 = 0.2
)
print(f"訓練データ: {len(X_train)}個")
print(f"検証データ: {len(X_val)}個")
print(f"テストデータ: {len(X_test)}個")
ホールドアウト法の長所と短所
長所:
- 実装が簡単
- 計算コストが低い
- 大規模データセットに適している
短所:
- データが少ない場合、分割によって情報が減る
- 分割方法によって結果が変わることがある
- データの偏りを引き継ぐ可能性
交差検証(Cross-Validation)
関連教材(青の統計学)
[図4] 交差検証
k-fold交差検証
[図2] k-fold交差検証
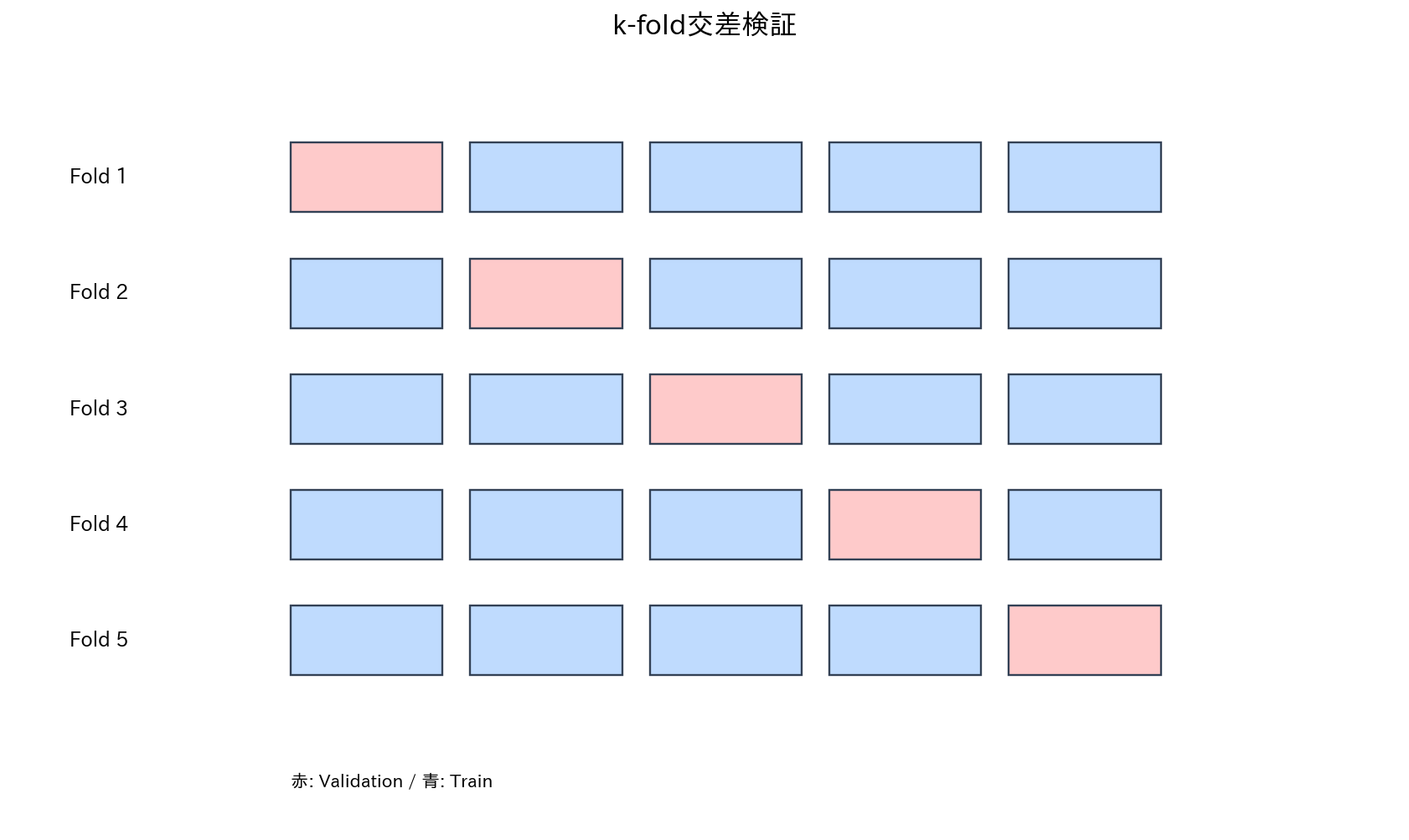
データを $k$ 個の部分集合(fold)に分割し、各foldを順番にテストデータとして使用する方法です。
5-fold交差検証の例:
Fold 1: [Test] [Train] [Train] [Train] [Train]
Fold 2: [Train] [Test] [Train] [Train] [Train]
Fold 3: [Train] [Train] [Test] [Train] [Train]
Fold 4: [Train] [Train] [Train] [Test] [Train]
Fold 5: [Train] [Train] [Train] [Train] [Test]
手順:
- データを5個のfoldに分割
- 各イテレーションで1つのfoldをテスト、残り4つを訓練に使用
- 5回の評価結果の平均を最終評価とする
Python実装例:
from sklearn.model_selection import cross_val_score, KFold
from sklearn.linear_model import LogisticRegression
# モデル準備
model = LogisticRegression()
# 5-fold交差検証
cv = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=cv, scoring='accuracy')
print(f"各foldの精度: {scores}")
print(f"平均精度: {scores.mean():.3f} ± {scores.std():.3f}")
交差検証の利点
- データの有効活用:すべてのデータが訓練・テスト両方に使用される
- 安定した評価:複数回の評価の平均で偶然性を減らす
- 分散の評価:モデルの性能のばらつきも分かる
層化抽出(Stratified Sampling)
クラス不均衡への対処
分類問題で、クラスの比率を保ったまま分割する手法です。
問題例:
全データ: クラスA 95%, クラスB 5%
ランダム分割: 訓練にクラスBがほとんど含まれない可能性
層化抽出の解決策:
from sklearn.model_selection import StratifiedKFold, stratify
# 層化ホールドアウト
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# 層化k-fold交差検証
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
for train_idx, test_idx in skf.split(X, y):
X_train_fold, X_test_fold = X[train_idx], X[test_idx]
y_train_fold, y_test_fold = y[train_idx], y[test_idx]
# 各foldでクラス比率が保たれる
print(f"訓練比率: {y_train_fold.mean():.3f}")
print(f"テスト比率: {y_test_fold.mean():.3f}")
コラム:データ漏洩の防止
データ漏洩とは
定義: テストデータの情報が直接的または間接的に訓練プロセスに混入すること
結果: 過度に楽観的な性能評価、本番環境での性能劣化
よくあるデータ漏洩のパターン
1. 前処理での漏洩
# 悪い例:分割前に正規化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 全データで統計量を計算
X_train, X_test = train_test_split(X_scaled, ...) # その後分割
# 良い例:分割後に正規化
X_train, X_test = train_test_split(X, ...)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 訓練データのみで学習
X_test_scaled = scaler.transform(X_test) # テストデータは変換のみ
2. 特徴量選択での漏洩
# 悪い例:全データで特徴量選択
selected_features = select_features(X, y) # 全データ使用
X_selected = X[:, selected_features]
X_train, X_test = train_test_split(X_selected, ...)
# 良い例:訓練データのみで特徴量選択
X_train, X_test, y_train, y_test = train_test_split(X, y, ...)
selected_features = select_features(X_train, y_train)
X_train_selected = X_train[:, selected_features]
X_test_selected = X_test[:, selected_features]
パイプラインによる解決
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectKBest
from sklearn.linear_model import LogisticRegression
# パイプラインで前処理とモデルを一体化
pipeline = Pipeline([
('scaler', StandardScaler()), # 1. 正規化
('feature_selection', SelectKBest()), # 2. 特徴量選択
('classifier', LogisticRegression()) # 3. 分類器
])
# 交差検証(前処理も含めて正しく実行)
scores = cross_val_score(pipeline, X, y, cv=5)
print(f"平均精度: {scores.mean():.3f}")
コラム:時系列データの特殊事情
関連教材(青の統計学)
時系列データでは、時間的順序を保つ必要があります。
時系列分割(Time Series Split)
通常のCV: 未来のデータで過去を予測してしまう 時系列CV: 常に過去のデータで未来を予測
from sklearn.model_selection import TimeSeriesSplit
# 時系列交差検証
tscv = TimeSeriesSplit(n_splits=5)
for train_idx, test_idx in tscv.split(X):
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
print(f"訓練期間: {train_idx[0]} - {train_idx[-1]}")
print(f"テスト期間: {test_idx[0]} - {test_idx[-1]}")
時系列分割の可視化:
Fold 1: [Train] [Test] [ ] [ ] [ ]
Fold 2: [Train] [Train] [Test] [ ] [ ]
Fold 3: [Train] [Train] [Train] [Test] [ ]
Fold 4: [Train] [Train] [Train] [Train] [Test]
なぜ時間順序が重要なのか
株価予測の例:
- 悪い例:2020年のデータで2019年を予測(未来の情報を使用)
- 良い例:2019年までのデータで2020年を予測(現実的)
実践的なガイドライン
データ量による分割戦略
データが多い場合(n > 10,000):
- ホールドアウト法で十分
- 訓練70%、検証15%、テスト15%
データが中程度(1,000 < n < 10,000):
- 5-fold or 10-fold交差検証
- 層化抽出を検討
データが少ない場合(n < 1,000):
- Leave-One-Out CV(LOOCVまたは)複数回のk-fold CV
- データ拡張を検討
実装のベストプラクティス
import numpy as np
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
def robust_evaluation(X, y, model_class=LogisticRegression, cv_folds=5):
"""
ロバストなモデル評価関数
"""
# 層化k-fold交差検証
skf = StratifiedKFold(n_splits=cv_folds, shuffle=True, random_state=42)
scores = []
for train_idx, val_idx in skf.split(X, y):
X_train, X_val = X[train_idx], X[val_idx]
y_train, y_val = y[train_idx], y[val_idx]
# 前処理(訓練データでのみ学習)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# モデル学習・評価
model = model_class()
model.fit(X_train_scaled, y_train)
score = model.score(X_val_scaled, y_val)
scores.append(score)
return np.array(scores)
# 使用例
scores = robust_evaluation(X, y)
print(f"平均精度: {scores.mean():.3f} ± {scores.std():.3f}")
まとめ
データの適切な分割は、機械学習モデルの信頼性を確保する上で極めて重要です。重要なポイント:
- 分割の目的:公平な評価と過学習の防止
- 3つのデータセット:訓練・検証・テストそれぞれに明確な役割
- 手法の選択:ホールドアウト法 vs 交差検証
- 特殊ケース:層化抽出(不均衡データ)、時系列分割
- データ漏洩の防止:前処理はデータ分割後に実施
これらの基本を理解することで、信頼性の高いモデル評価が可能になります。
次章では、過学習と汎化について詳しく学習します。