過学習と汎化
機械学習の究極の目標は、未知のデータに対して良い予測をすること、つまり汎化性能(Generalization Performance)を高めることです。しかし、訓練データに過度に適合してしまう過学習(Overfitting)は、この目標を阻む最大の障害です。本章では、過学習の理論的理解と実践的な対処法について学習します。
過学習とは何か
基本的な概念
[図2] 過学習例
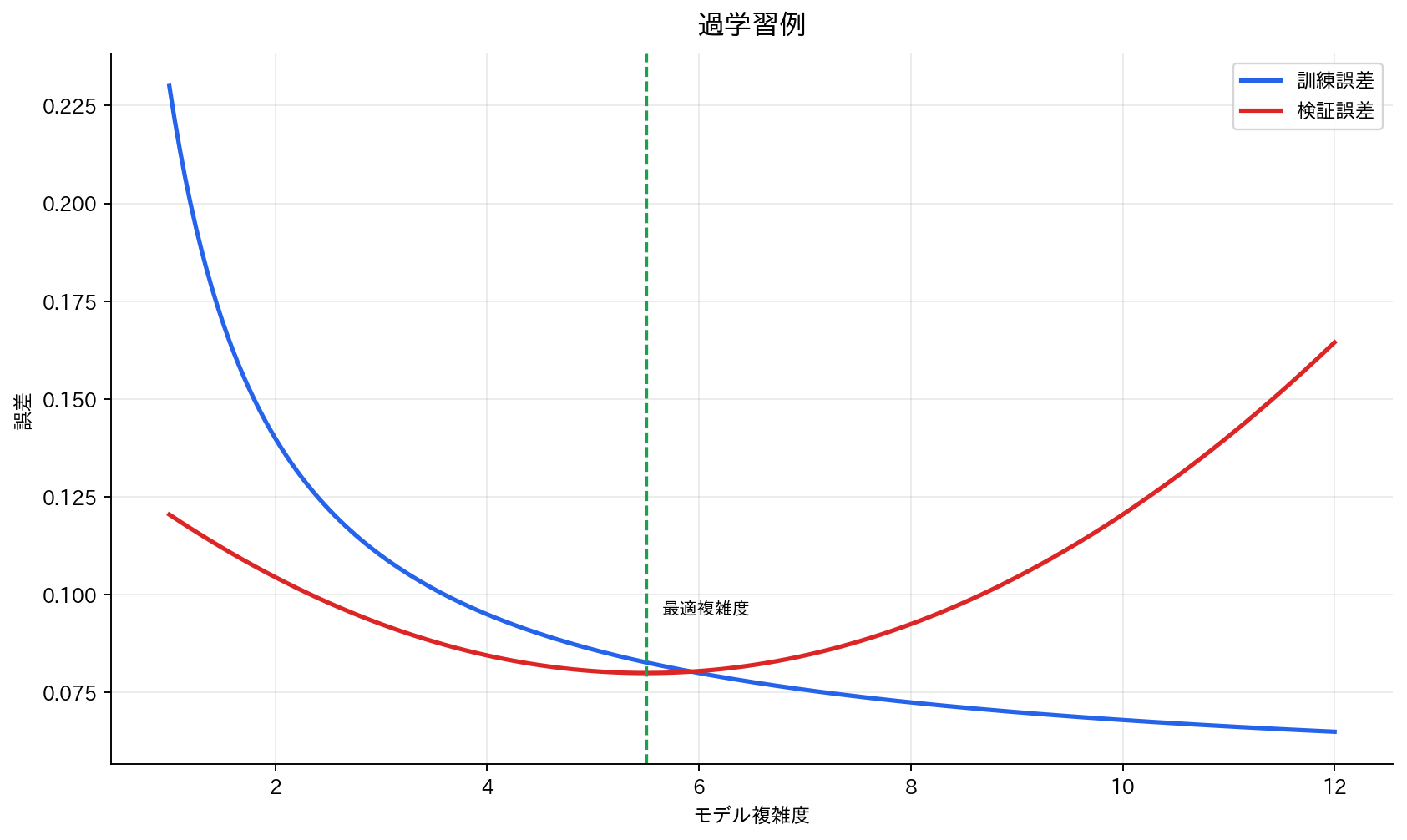
過学習とは、モデルが訓練データに過度に適合し、新しいデータに対する予測性能が低下する現象です。
例:試験対策のアナロジー
- 良い学習:原理を理解し、応用問題も解ける
- 過学習:過去問を暗記しただけ、初見問題は解けない
視覚的理解:多項式回帰の例
理想的なフィット: y = 2x + 1 + ノイズ(シンプルな直線)
過学習したモデル: 訓練データの全点を通る高次多項式(複雑な曲線)
過学習の数学的表現
期待リスク(汎化誤差):
経験リスク(訓練誤差):
過学習の状況:
過学習の原因
1. モデルが複雑すぎる
- パラメータ数がデータ数より多い
- 高次の多項式を使用
- 深すぎるニューラルネットワーク
2. 訓練データが少ない
- データからパターンを学習するには不十分
- ノイズの影響を受けやすい
- 偶然的なパターンを真のパターンと誤認
3. 訓練の継続しすぎ
- イテレーション数が多すぎる
- 早期停止を行わない
- 検証データでの監視を怠る
4. ノイズの学習
- 真のパターンだけでなくノイズまで記憶
- 訓練データ特有の偶然的なパターンを学習
バイアス-分散トレードオフ
関連教材(青の統計学)
基本的な分解
予測誤差は3つの要素に分解できます:
バイアス(Bias):
- モデルの予測と真の値の系統的なずれ
- 単純なモデル → 高バイアス
分散(Variance):
- 異なる訓練データでの予測のばらつき
- 複雑なモデル → 高分散
ノイズ:
- 削減不可能な誤差
- データ収集の限界など
直感的な理解:ダーツの例
高バイアス・低分散:
- 的の中心からずれているが、毎回同じ場所に当たる
- 単純なモデル(例:線形回帰で非線形データを予測)
低バイアス・高分散:
- 平均は的の中心だが、毎回大きくばらつく
- 複雑なモデル(例:高次多項式)
理想(低バイアス・低分散):
- 的の中心に集中して当たる
- 適切な複雑さのモデル
モデル複雑度とエラーの関係
モデル複雑度 → 単純 適切 複雑
バイアス → 高 ↘ 中 ↘ 低
分散 → 低 ↗ 中 ↗ 高
総誤差 → 高 ↘ 最小 ↗ 高
過学習の対策
関連教材(青の統計学)
1. データを増やす
最も効果的な方法
- より多くのデータでパターンを正確に学習
- ノイズの影響を相対的に減少
データ拡張の例:
# 画像データの場合
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=20, # 回転
width_shift_range=0.1, # 水平移動
height_shift_range=0.1, # 垂直移動
horizontal_flip=True # 水平反転
)
2. モデルを単純化
パラメータ数を減らす
- 少ない特徴量を使用
- 浅いネットワーク
- 低次の多項式
3. 正則化(Regularization)
[図4] 正則化効果
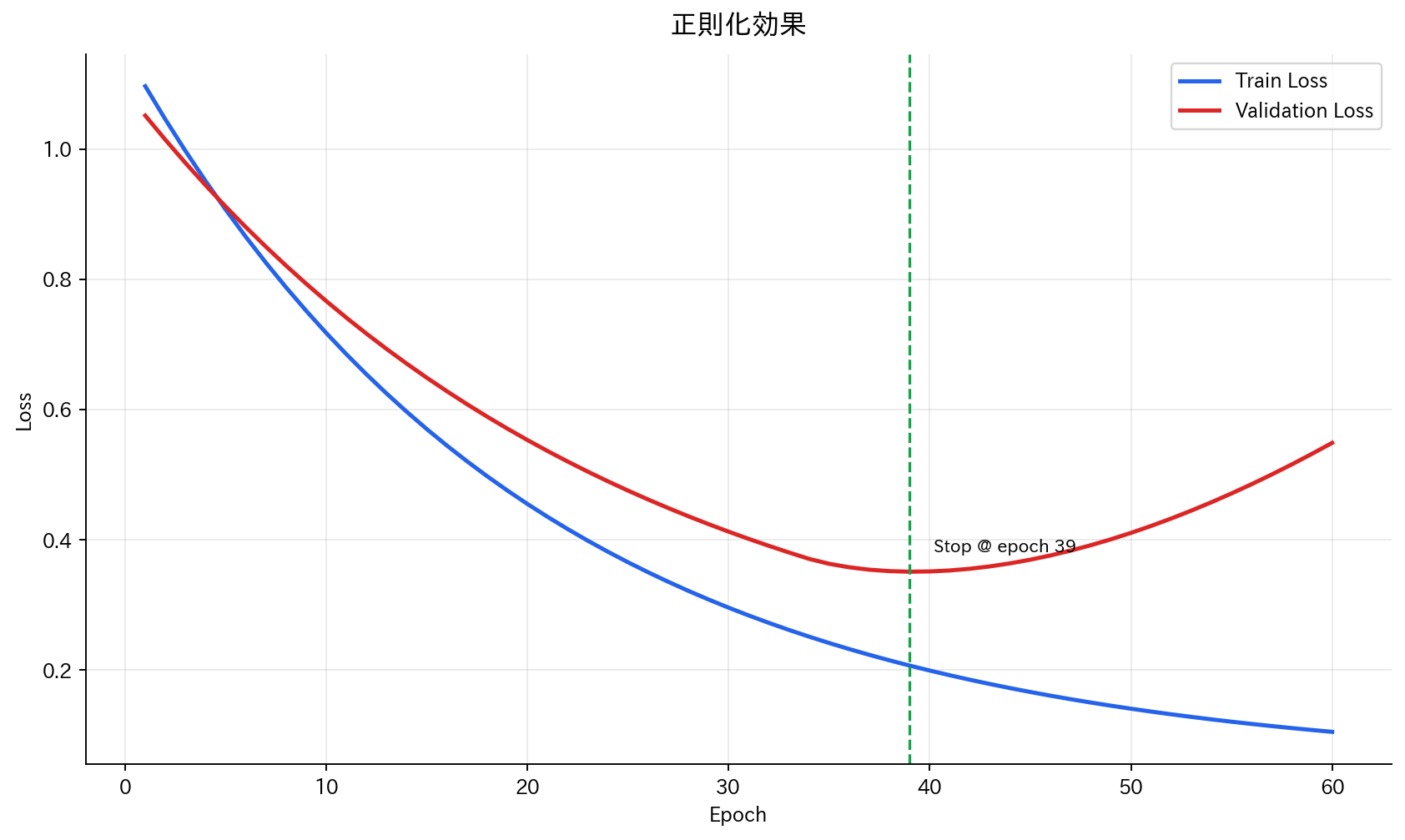
正則化の目的は、訓練データに対して過度に複雑な当てはめをしないよう制御することです。
損失を下げるだけならパラメータを大きくしてでも当てにいけますが、それはしばしばノイズまで学習してしまいます。
そこで「大きすぎるパラメータには罰則を与える」項を目的関数に足し、汎化しやすい解へ誘導します。
L2正則化(Ridge):
L2は全パラメータをなだらかに小さくする働きがあり、特定の特徴量に重みが集中しすぎるのを防ぎます。
分かりやすく言うと「モデル全体にブレーキをかける」イメージです。
L1正則化(Lasso):
L1は一部の重みを厳密に0へ押しやすく、特徴量選択の効果を持ちます。
つまり「重要でない入力を自動的に落とす」性質があり、解釈性向上にも有効です。
L1とL2の使い分け(実務の目安):
- 特徴量が多く、不要特徴を絞りたい:L1寄り
- 予測の安定性を優先したい:L2寄り
- 両方ほしい:Elastic Net(L1+L2)
効果:
- パラメータの大きさを制限
- よりスムーズなモデルを学習
4. 早期停止(Early Stopping)
概念: 検証誤差が増加し始めたら訓練を停止
# 早期停止の実装例
best_val_loss = float('inf')
patience = 5
patience_counter = 0
for epoch in range(max_epochs):
# 訓練とバリデーション
train_model()
val_loss = validate_model()
if val_loss < best_val_loss:
best_val_loss = val_loss
save_model() # 最良のモデルを保存
patience_counter = 0
else:
patience_counter += 1
if patience_counter >= patience:
print(f"早期停止: エポック {epoch}")
break
load_best_model() # 最良のモデルを復元
学習曲線による診断
学習曲線の見方
縦軸: 誤差(損失) 横軸: 訓練イテレーション数(エポック) 2つの線: 訓練誤差、検証誤差
パターンによる診断
1. 理想的なケース:
訓練誤差 ↘ ↘ ↘ → 低い値で安定
検証誤差 ↘ ↘ ↘ → 低い値で安定(訓練誤差と近い)
2. 過学習のケース:
訓練誤差 ↘ ↘ ↘ → 非常に低い値
検証誤差 ↘ ↗ ↗ → 途中から上昇(訓練誤差と大きな差)
3. 未学習のケース:
訓練誤差 → 高い値で停滞
検証誤差 → 高い値で停滞(両方とも改善しない)
コラム:実践的な過学習対策
ドロップアウト(Dropout)
ニューラルネットワークで使用される正則化手法:
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5), # 50%のユニットをランダムに無効化
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.3), # 30%のユニットをランダムに無効化
tf.keras.layers.Dense(10, activation='softmax')
])
効果:
- 特定のニューロンへの依存を防ぐ
- アンサンブル効果による汎化性能向上
アンサンブル学習
複数のモデルを組み合わせて予測:
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# 異なるアルゴリズムを組み合わせ
clf1 = LogisticRegression()
clf2 = RandomForestClassifier()
clf3 = SVC(probability=True)
# 投票による分類
voting_clf = VotingClassifier(
estimators=[('lr', clf1), ('rf', clf2), ('svc', clf3)],
voting='soft' # 確率の平均
)
voting_clf.fit(X_train, y_train)
predictions = voting_clf.predict(X_test)
利点:
- 個々のモデルの過学習を相殺
- 安定した予測性能
コラム:ハイパーパラメータチューニング
過学習を防ぐには適切なハイパーパラメータの設定が重要です。
グリッドサーチ
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# パラメータの候補を定義
param_grid = {
'n_estimators': [50, 100, 200], # 木の数
'max_depth': [3, 5, 7, None], # 最大深度
'min_samples_split': [2, 5, 10], # 分割に必要な最小サンプル数
'min_samples_leaf': [1, 2, 4] # 葉に必要な最小サンプル数
}
# グリッドサーチで最適化
rf = RandomForestClassifier(random_state=42)
grid_search = GridSearchCV(
rf, param_grid, cv=5, scoring='accuracy', n_jobs=-1
)
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
best_model = grid_search.best_estimator_
print(f"最適パラメータ: {best_params}")
print(f"最高スコア: {grid_search.best_score_:.3f}")
ランダムサーチ
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint, uniform
# パラメータの分布を定義
param_dist = {
'n_estimators': randint(50, 200),
'max_depth': [3, 5, 7, 10, None],
'min_samples_split': randint(2, 11),
'min_samples_leaf': randint(1, 5),
'max_features': uniform(0.1, 0.9)
}
# ランダムサーチ(グリッドサーチより効率的)
random_search = RandomizedSearchCV(
rf, param_dist, n_iter=100, cv=5,
scoring='accuracy', n_jobs=-1, random_state=42
)
random_search.fit(X_train, y_train)
実践的なワークフロー
過学習対策の優先順位
データを増やす(最も効果的)
- より多くのデータを収集
- データ拡張技術の活用
適切なモデル複雑度の選択
- 単純なモデルから開始
- 段階的に複雑化
正則化の適用
- L1/L2正則化
- ドロップアウト
早期停止の実装
- 検証誤差の監視
- 適切なタイミングでの停止
アンサンブル手法
- 複数モデルの組み合わせ
- 予測の安定化
総合的な実装例
import numpy as np
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
def prevent_overfitting_workflow(X, y, problem_type='classification'):
"""
過学習を防ぐ総合的なワークフロー
"""
# 1. データ分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# 2. 前処理
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 3. モデル選択(複雑度を制御)
if problem_type == 'regression':
models = {
'Ridge(alpha=0.1)': Ridge(alpha=0.1),
'Ridge(alpha=1.0)': Ridge(alpha=1.0),
'Ridge(alpha=10.0)': Ridge(alpha=10.0)
}
else:
models = {
'RF(max_depth=3)': RandomForestClassifier(max_depth=3, random_state=42),
'RF(max_depth=5)': RandomForestClassifier(max_depth=5, random_state=42),
'RF(max_depth=None)': RandomForestClassifier(max_depth=None, random_state=42)
}
# 4. 交差検証で評価
results = {}
for name, model in models.items():
scores = cross_val_score(model, X_train_scaled, y_train, cv=5)
results[name] = {
'mean': scores.mean(),
'std': scores.std()
}
print(f"{name}: {scores.mean():.3f} ± {scores.std():.3f}")
# 5. 最良モデルを選択してテスト
best_model_name = max(results, key=lambda x: results[x]['mean'])
best_model = models[best_model_name]
best_model.fit(X_train_scaled, y_train)
test_score = best_model.score(X_test_scaled, y_test)
print(f"\n最良モデル: {best_model_name}")
print(f"テストスコア: {test_score:.3f}")
return best_model, scaler
# 使用例(分類問題の場合)
# best_model, scaler = prevent_overfitting_workflow(X, y, 'classification')
まとめ
過学習は機械学習における最も重要な課題の一つです。重要なポイント:
- 概念の理解:訓練データへの過度な適合と汎化性能の低下
- バイアス-分散トレードオフ:モデル複雑度とエラーの関係
- 対策の階層:データ増加 → モデル単純化 → 正則化 → 早期停止
- 診断方法:学習曲線による過学習・未学習の検出
- 実践手法:ドロップアウト、アンサンブル、ハイパーパラメータチューニング
これらの知識を活用することで、実用的で汎化性能の高いモデルを構築できるようになります。
これでStage 1の基礎概念の学習は完了です。次のStageでは、具体的な機械学習アルゴリズムについて詳しく学習していきます。