自然言語処理
この章で学ぶこと
- テキスト前処理から特徴量化までの流れを、数理的背景付きで説明できる
- BoW/TF-IDF と埋め込み表現(Word2Vec, BERT系)の違いを理解する
- Attention/Transformer の計算原理を、式と実装の対応で説明できる
- タスク要件(精度・速度・解釈性)に応じて手法選択できる
前提知識チェック
- 線形代数:内積、行列積、固有値分解の基本
- 確率統計:条件付き確率、対数尤度
- 深層学習:活性化関数、逆伝播、正則化
学習目標
自然言語処理(Natural Language Processing, NLP)は、人間が使用する言語をコンピュータに理解・処理させる技術分野です。本章では、テキストデータの前処理から最新のTransformerアーキテクチャまで、自然言語処理の包括的な技術を学習します。
1. 自然言語処理の基礎概念
1.1 NLPの課題と特徴
自然言語処理は他のデータ処理タスクと比較して特有の課題を持ちます。自然言語は本質的に曖昧性を含み、同じ意味を異なる表現で表したり、同じ表現が文脈によって異なる意味を持ったりします。また、言語は文化的・社会的背景に深く依存し、時代とともに変化する動的な性質を持ちます。
テキストデータは非構造化データであり、数値データと異なり直接的な数学的操作が困難です。そのため、テキストを数値表現に変換するベクトル化の過程が必要不可欠となります。さらに、自然言語は階層的な構造を持ち、文字、単語、句、文、段落といった複数のレベルで意味が構成されます。
1.2 NLPタスクの分類
自然言語処理のタスクは、言語理解(Natural Language Understanding)と言語生成(Natural Language Generation)に大別されます。理解タスクには、テキスト分類、感情分析、固有表現抽出、質問応答などが含まれます。一方、生成タスクには、機械翻訳、文要約、対話システム、創作支援などがあります。
また、処理レベルによる分類では、形態素解析や品詞タグ付けといった語彙レベル、構文解析による文レベル、談話解析による文書レベルの処理に分けられます。近年では、これらの複数レベルを統合的に処理するエンドツーエンドの手法が主流となっています。
2. テキスト前処理技術
[図2] 前処理パイプライン(トークナイズ〜正規化)
2.1 基本的な前処理
テキストデータの品質は自然言語処理の成果に直接影響するため、適切な前処理が極めて重要です。基本的な前処理として、まず文字の正規化があります。これには、全角・半角の統一、大文字・小文字の統一、不要な空白の除去、特殊文字の処理などが含まれます。
ノイズ除去では、HTMLタグの削除、URLや電子メールアドレスの処理、絵文字や記号の扱いを決定します。また、ストップワードの除去も重要な前処理の一つです。ストップワードは「the」「is」「の」「です」のような、文法的な役割は持つものの内容語としての意味が薄い語を指します。ただし、タスクによってはこれらの語が重要な情報を持つ場合があるため、除去の是非は慎重に判断する必要があります。
2.2 トークン化と形態素解析
トークン化(Tokenization)は、連続したテキストを意味のある単位(トークン)に分割する処理です。英語のような言語では空白で単語が区切られているため比較的単純ですが、日本語や中国語のような言語では単語境界が明示されないため、より高度な処理が必要です。
日本語の形態素解析では、MeCab、Janome、SudachiPyなどのツールが広く使用されます。これらのツールは、辞書ベースのアプローチや統計的手法を用いて、文を形態素(最小の意味単位)に分割し、各形態素の品詞や活用形などの情報を付与します。近年では、深層学習ベースの形態素解析器も開発され、辞書に登録されていない新語や専門用語に対してもより柔軟な処理が可能になっています。
2.3 正規化と語幹処理
語の正規化は、表記の揺れや活用形を統一する処理です。英語では、ステミング(語幹抽出)とレマタイゼーション(語彙化)という手法があります。ステミングは「running」「runs」「ran」を「run」に変換する処理で、ルールベースの簡易的な手法です。レマタイゼーションはより高度で、品詞情報を考慮して「better」を「good」に変換するなど、語の原形を正確に復元します。
日本語では、動詞の活用形統一、形容詞の語尾処理、送り仮名の統一などが重要です。また、同義語や類義語の統一、表記揺れの解決(「コンピュータ」と「コンピューター」など)も実用的なシステムでは必要不可欠です。
3. 特徴量抽出手法
関連教材(青の統計学)
3.1 Bag of Words(BoW)モデル
Bag of Wordsは最も基本的なテキストベクトル化手法で、文書を単語の集合として扱い、各単語の出現回数や出現の有無を特徴量とします。この手法は実装が簡単で解釈しやすく、多くのタスクで有効性が確認されています。
BoWモデルでは、語彙全体(vocabulary)から辞書を構築し、各文書を語彙サイズの次元を持つベクトルで表現します。例えば、語彙が10,000語の場合、各文書は10,000次元のベクトルとなります。このベクトルは通常スパースベクトル(大部分の要素がゼロ)となるため、効率的な実装が重要です。
BoWの主な限界は、単語の順序情報が失われることと、文脈による意味の違いを捉えられないことです。また、語彙サイズが大きくなると次元の呪いの問題が生じやすくなります。
3.2 TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)は、BoWの改良版として広く使用される手法です。単純な出現回数ではなく、文書内での重要度を考慮した重み付けを行います。
TF(Term Frequency)は文書内での単語の出現頻度で、一般的にはlog(1 + tf)のような対数変換が適用されます。IDF(Inverse Document Frequency)は、単語の希少性を表す指標で、log(N/df)として計算されます。ここで、Nは全文書数、dfはその単語を含む文書数です。
代表的な定義は次のとおりです。
TF-IDFの値は、文書内で頻繁に出現し(高TF)、かつ他の文書ではあまり出現しない(高IDF)単語ほど大きくなります。これにより、その文書を特徴づける重要な単語により大きな重みが付与されます。TF-IDFは情報検索やテキスト分類で優れた性能を示し、現在でも多くのシステムで基準手法として使用されています。
3.3 N-gramモデル
N-gramモデルは、連続するN個の単語の組み合わせを特徴量として使用する手法です。Unigramは単一の単語、Bigramは2個の連続する単語、Trigramは3個の連続する単語を特徴とします。
N-gramの利点は、単語の順序情報を部分的に保持できることです。例えば、「not good」と「good not」は異なるBigramとして扱われ、否定の意味を捉えやすくなります。しかし、Nが大きくなると特徴量の次元が爆発的に増加し、データの疎性問題が深刻化します。
実用的には、UnigramとBigramの組み合わせ、または文字レベルのN-gramが多く使用されます。文字レベルのN-gramは、単語境界の曖昧な言語や、略語・誤字に対してロバストであるという利点があります。
| 手法 | 強み | 弱み | 向いている場面 |
|---|---|---|---|
| BoW | 実装が簡単、解釈しやすい | 語順・文脈を失う | ベースライン、説明重視 |
| TF-IDF | 重要語を強調できる | 文脈は扱えない | 検索、軽量分類 |
| N-gram | 局所的な語順を保持 | 次元が増えやすい | 否定表現、定型文検知 |
| 文脈埋め込み(BERT系) | 文脈依存で高精度 | 計算コストが高い | 精度重視タスク |
4. 単語ベクトル表現
関連教材(青の統計学)
[図3] 単語ベクトル空間と類似度
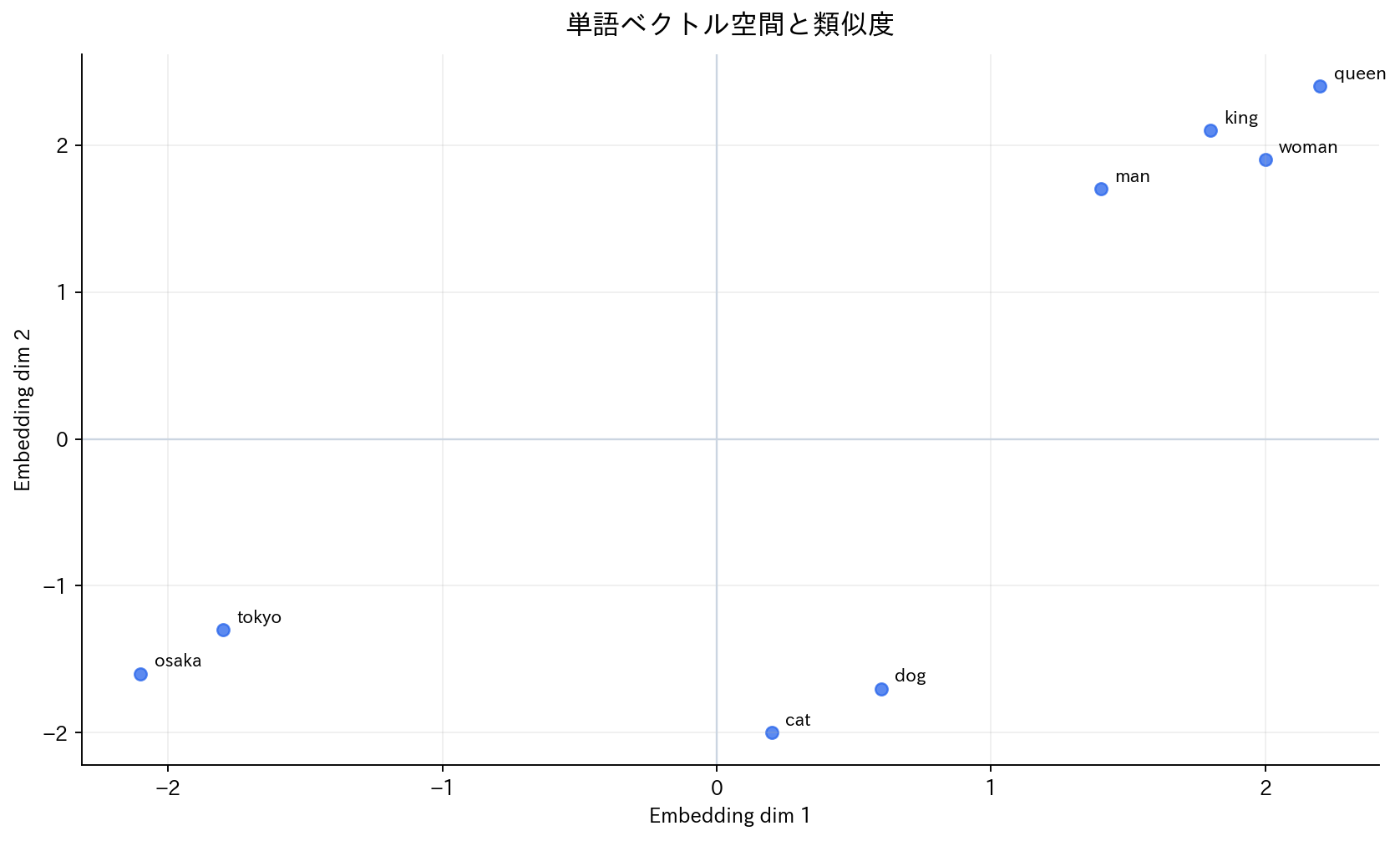
4.1 Word2Vec
Word2Vecは、ニューラルネットワークを用いて単語を密ベクトル(dense vector)で表現する手法です。従来のスパースベクトル表現と異なり、意味的に類似した単語が近いベクトル空間に配置されるという特性を持ちます。
Word2Vecには、Skip-gramモデルとCBOW(Continuous Bag of Words)モデルの2つの主要なアーキテクチャがあります。Skip-gramは中心単語から周囲の文脈単語を予測する方向性を持ち、低頻度語に対して有効です。CBOWは周囲の文脈から中心単語を予測し、高頻度語に対して有効で、計算効率も優れています。
Word2Vecの革新的な点は、「king - man + woman = queen」のような意味的な演算が可能になったことです。これにより、単語間の意味的関係を数値計算として扱えるようになりました。また、単語の類似度計算、クラスタリング、可視化なども容易になり、自然言語処理の研究と応用を大きく前進させました。
4.2 GloVe
GloVe(Global Vectors for Word Representation)は、Word2Vecの局所的な文脈情報に加えて、グローバルな統計情報を活用する手法です。コーパス全体の単語共起統計を事前に計算し、その情報を用いて単語ベクトルを学習します。
GloVeの学習目標は、2つの単語ベクトルの内積が、それらの単語の対数共起確率に比例するようにベクトルを調整することです。この手法により、Word2Vecよりも効率的にベクトルを学習でき、特にアナロジータスクで優れた性能を示します。
GloVeのもう一つの利点は、学習の安定性です。Word2Vecのような確率的な手法と比較して、決定論的な最適化を行うため、再現性が高く、ハイパーパラメータの調整が容易です。
4.3 FastText
FastTextは、Facebookが開発した単語ベクトル学習手法で、Word2Vecの拡張として位置づけられます。最大の特徴は、単語を文字n-gramの集合として扱うことで、未知語(out-of-vocabulary, OOV)問題に対処できることです。
例えば、「learning」という単語を、「<le」「lea」「ear」...「ng>」のような文字n-gramに分解し、これらのベクトルの合計として単語ベクトルを構成します。この手法により、学習時に見なかった単語でも、構成文字n-gramから推定したベクトル表現を得ることができます。
FastTextは、特に語尾変化の豊富な言語(ドイツ語、ロシア語など)や、語彙の多様性が高い領域(医学、法律など)で威力を発揮します。また、タイポや略語に対してもある程度のロバスト性を持ちます。
5. Transformerアーキテクチャ
5.1 Attentionメカニズム
[図4] Attention重みの計算
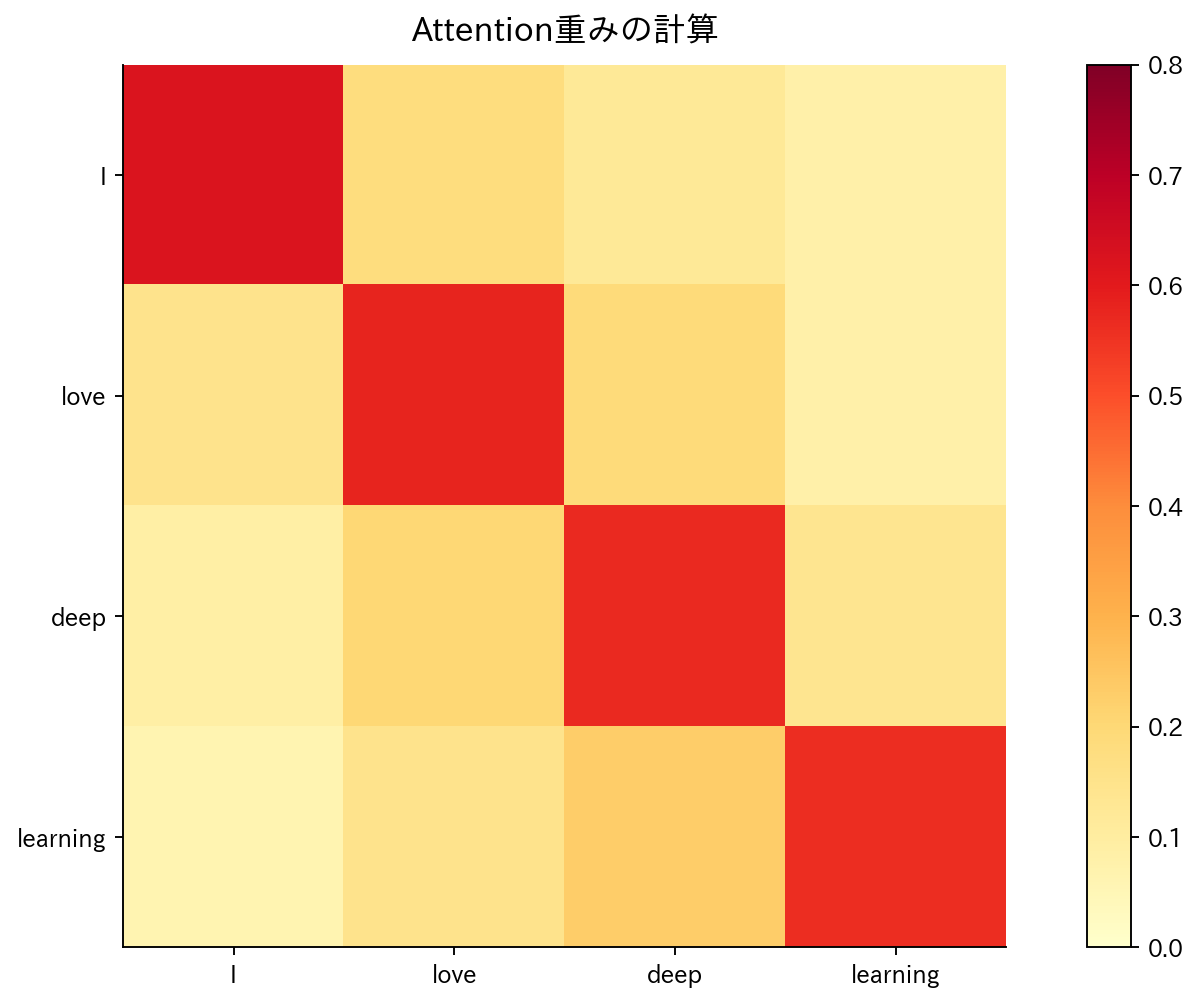
Attentionメカニズムは、Transformerアーキテクチャの核心となる技術で、入力系列の各位置に対して重要度を動的に計算し、重要な部分により多くの注意を払う仕組みです。従来のRNNベースの手法では、長い系列の処理で情報が薄れる問題(vanishing gradient problem)がありましたが、Attentionはこの問題を解決しました。
Self-Attentionでは、同一系列内の各位置が他の全ての位置との関係を直接的に計算します。具体的には、各位置のベクトルから Query、Key、Valueの3つの表現を生成し、QueryとKeyの内積によってAttentionスコアを計算します。このスコアを正規化した重みでValueを重み付き平均することで、文脈を考慮した新しい表現を得ます。
数式では、次の形で表されます。
Multi-Head Attention は
で定義され、異なる依存関係を並列に捉えることができます。
Multi-Head Attentionは、異なる重み行列を用いて複数のAttention計算を並列実行し、それらの結果を結合する手法です。これにより、異なる種類の関係性(統語的関係、意味的関係など)を同時に捉えることができます。
5.2 Transformerアーキテクチャ
[図5] Transformer Encoderブロック
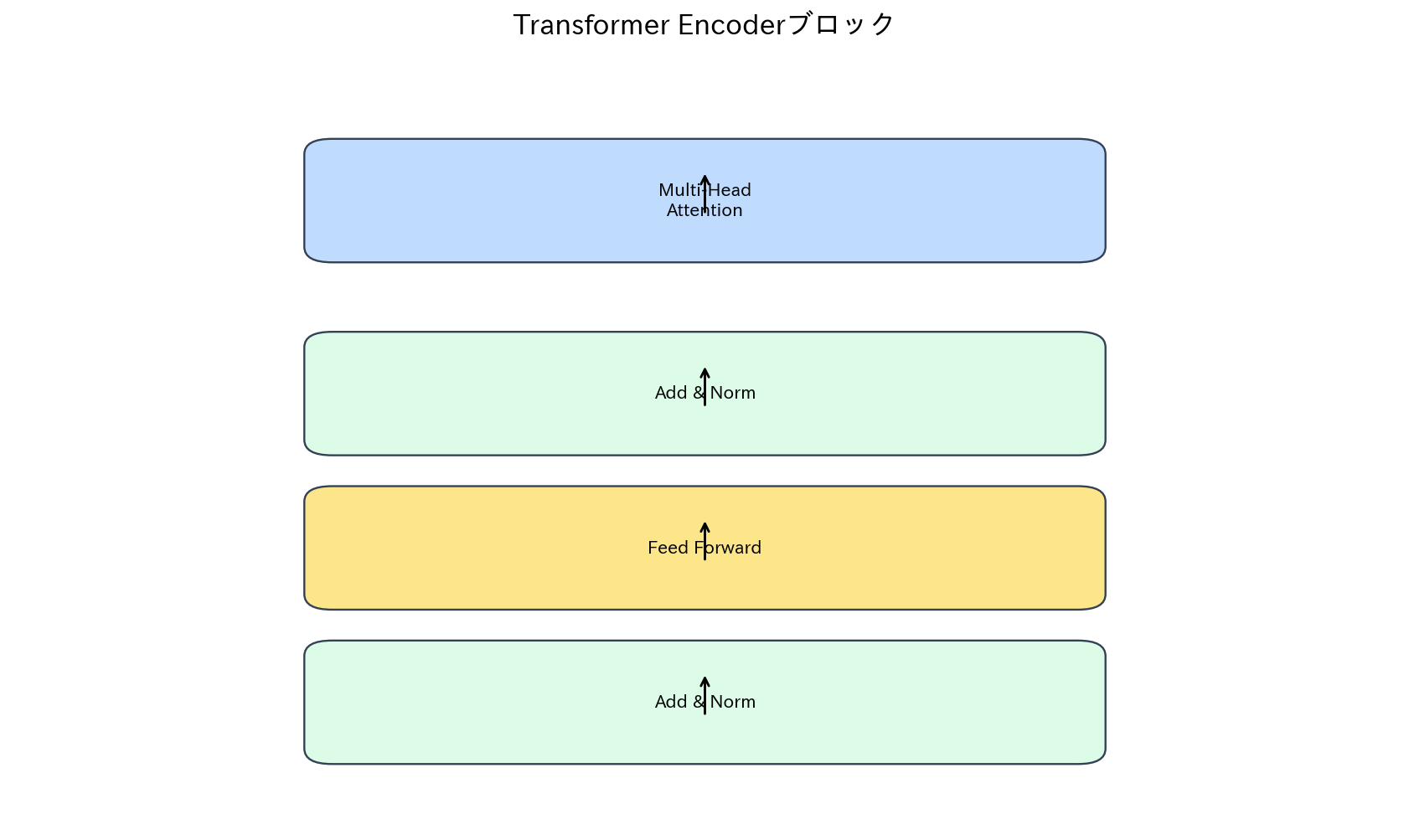
Transformerは、「Attention Is All You Need」論文で提案された、完全にAttentionメカニズムに基づくアーキテクチャです。従来のRNNやCNNを使用せず、Self-AttentionとPosition-wise Feed-Forward Networkのみで構成されています。
エンコーダー・デコーダー構造を採用し、エンコーダーは入力系列を高次元表現に変換し、デコーダーは出力系列を生成します。各層では、Multi-Head Attention、Layer Normalization、Residual Connection、Feed-Forward Networkが組み合わされています。
Positional Encodingは、Transformerが位置情報を扱うための重要な仕組みです。Self-Attentionだけでは単語の順序情報が失われるため、各位置に固有のエンコーディングを追加することで位置情報を保持します。正弦波と余弦波の組み合わせによるエンコーディングが一般的に使用されます。
5.3 事前学習済みモデル
BERTは、Bidirectional Encoder Representations from Transformersの略で、双方向のTransformerエンコーダーを用いた事前学習済みモデルです。従来の言語モデルが左から右への一方向的な予測を行うのに対し、BERTは左右両方向の文脈を同時に考慮します。
事前学習では、Masked Language Model(MLM)とNext Sentence Prediction(NSP)の2つのタスクが使用されます。MLMは、文中の一部の単語をマスクし、文脈から予測させるタスクです。NSPは、2つの文が連続するかを判定するタスクで、文間の関係を学習させます。
BERTの後継として、RoBERTa、ALBERT、DeBERTaなど、様々な改良モデルが提案されています。これらは事前学習の方法、モデル構造、効率性などの面で改善を加えています。生成タスクに特化したGPT系列のモデルとともに、現在の自然言語処理の主流となっています。
モデル選定の意思決定フレーム
NLPは「何を最適化するか」を先に決めると、手法選択の迷いが大きく減ります。特に実務では、精度だけでなく推論レイテンシ・説明可能性・運用コストを同時に見る必要があります。
| 要件 | 有力候補 | 採用時の注意点 |
|---|---|---|
| 高速推論、低コスト | TF-IDF + 線形モデル | 前処理差分に弱い。辞書更新と再学習の運用設計が必要 |
| そこそこの精度と頑健性 | FastText / 事前学習済み埋め込み + 軽量分類器 | OOVには強いが、長文文脈の表現力には限界 |
| 高精度、複雑文脈の理解 | BERT系ファインチューニング | GPU資源、推論遅延、モデル更新コストを許容する必要 |
| 検索・推薦のベクトル統合 | 埋め込みモデル + ベクトル検索 | オフライン評価だけでなくオンライン指標で監視する |
ベースライン固定の最小実装
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score
from sklearn.pipeline import Pipeline
baseline = Pipeline([
("tfidf", TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9)),
("clf", LogisticRegression(max_iter=500, class_weight="balanced")),
])
baseline.fit(train_texts, y_train)
print("valid_f1:", f1_score(y_valid, baseline.predict(valid_texts), average="macro"))
ベースラインの目的は「最高精度」ではなく、前処理・評価・データ分割の土台を先に安定化することです。ここが不安定なまま高性能モデルへ進むと、改善量を正しく判断できません。
BERT系へ進む条件
次のいずれかを満たす場合に、Transformer系へ段階的に移行するのが安全です。
- ベースラインのエラーが文脈依存(否定、照応、多義語)に集中している
- 運用上許容できる推論遅延と計算資源が確保できる
- 追加精度が事業KPI(CVR、離脱率、問い合わせ削減など)に寄与する見込みがある
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-v3")
model = AutoModelForSequenceClassification.from_pretrained("your_finetuned_model")
model.eval()
inputs = tokenizer(
["この講座は分かりやすい", "解説が抽象的で難しい"],
return_tensors="pt",
padding=True,
truncation=True,
)
with torch.no_grad():
probs = model(**inputs).logits.softmax(dim=1)
print(probs)
まとめ
自然言語処理では、前処理・特徴量設計・モデル選択を一体で設計することが重要です。
特に「軽量ベースラインで評価系を固める → 文脈依存エラーを確認 → 必要ならTransformerへ拡張」という順序を守ると、精度向上と運用安定性を両立しやすくなります。
次のステップ
次章では、画像データを対象にしたコンピュータビジョンを扱います。
タスクごとに出力形式と評価指標がどう変わるかを、NLPとの違いを意識しながら学習していきます。