損失関数と最適化
機械学習の核心は、モデルの予測と実際の値との「ずれ」を最小化することです。この「ずれ」を定量化するのが損失関数(Loss Function)であり、それを最小化する手法が最適化(Optimization)です。本章では、これらの基本概念と手法について学習します。
損失関数とは何か
関連教材(青の統計学)
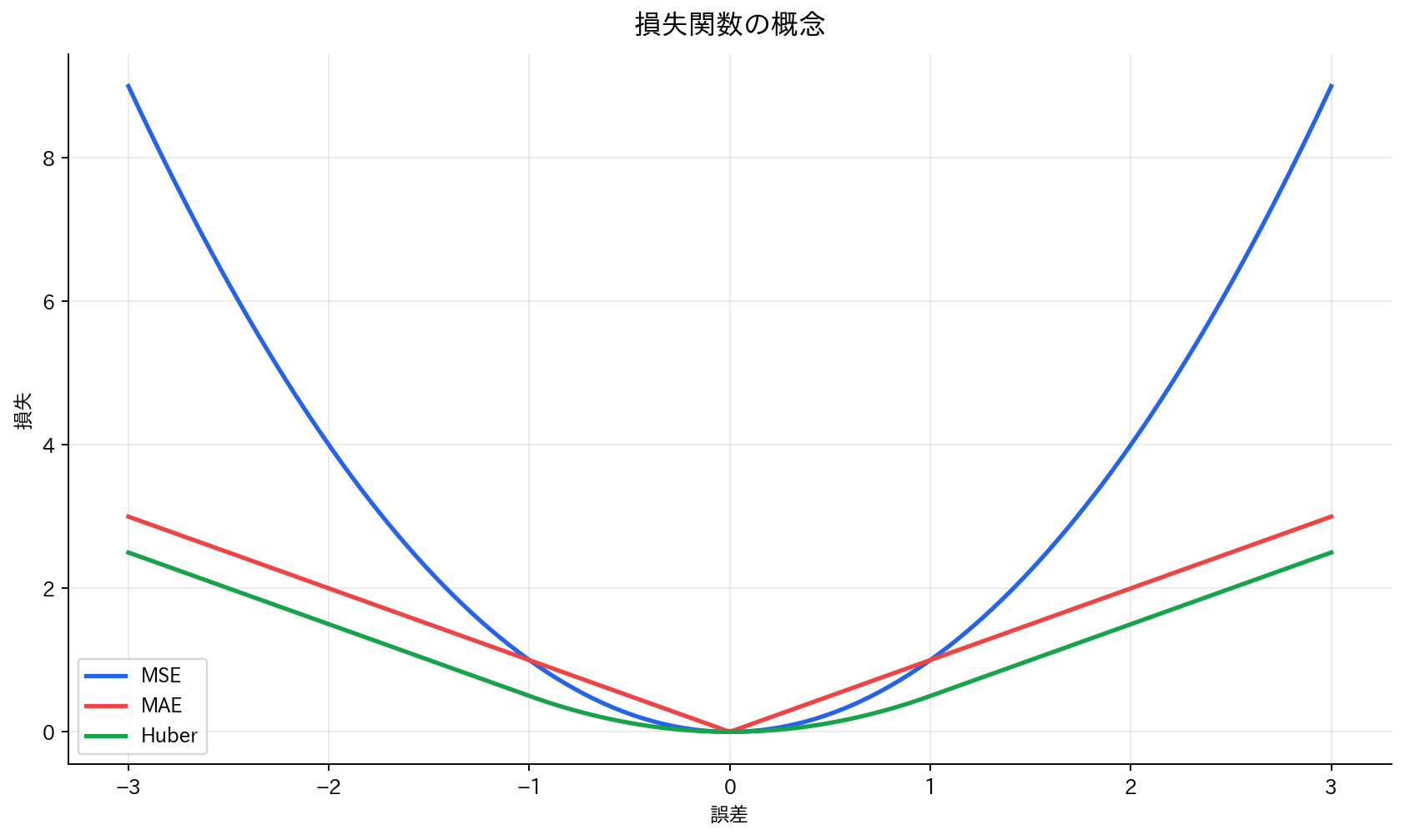
[図1] 損失関数の概念
基本的な考え方
損失関数は、モデルの予測がどれだけ「悪い」かを数値で表す関数です。
数式表現:
全体の損失(平均損失):
ここで:
- $y_i$:実際の値
- $\hat{y}_i$:モデルの予測値
- $n$:データの数
なぜ損失関数が必要なのか
機械学習の目的は「良い」モデルを作ることですが、「良い」の定義は問題によって異なります。損失関数は、この「良さ」を数値化し、コンピュータが最適化できる形にします。
回帰の損失関数
[図4] 損失関数
平均二乗誤差(MSE)
最も一般的な回帰の損失関数です。
定義:
特徴:
- 大きな誤差に重いペナルティ(2乗のため)
- 微分可能で最適化しやすい
- 外れ値の影響を受けやすい
例:住宅価格予測
- 実際:3000万円、予測:2800万円 → 誤差:200万円 → MSE寄与:40,000
- 実際:3000万円、予測:3200万円 → 誤差:200万円 → MSE寄与:40,000
平均絶対誤差(MAE)
絶対値を使った損失関数です。
定義:
特徴:
- 外れ値の影響を受けにくい(線形のため)
- 解釈しやすい(誤差の平均)
- 微分が難しい場合がある
MSEとMAEの比較:
- MSE:大きな誤差により敏感
- MAE:すべての誤差を同等に扱う
分類の損失関数
交差エントロピー損失
分類問題で最も一般的な損失関数です。
2クラス分類の場合:
ここで:
- $y_i \in \{0, 1\}$:真のラベル
- $\hat{y}_i \in [0, 1]$:クラス1の予測確率
多クラス分類の場合:
特徴:
- 確率的な予測に適している
- 確信のない予測(0.5付近)により大きなペナルティ
- 微分可能で最適化しやすい
交差エントロピーの直感的理解
スパムメール判定の例:
- 実際:スパム(1)、予測確率:0.9 → 損失:小(良い予測)
- 実際:スパム(1)、予測確率:0.1 → 損失:大(悪い予測)
- 実際:正常(0)、予測確率:0.9 → 損失:大(悪い予測)
最適化の基本概念
関連教材(青の統計学)
勾配降下法の原理
[図2] 勾配降下法の可視化
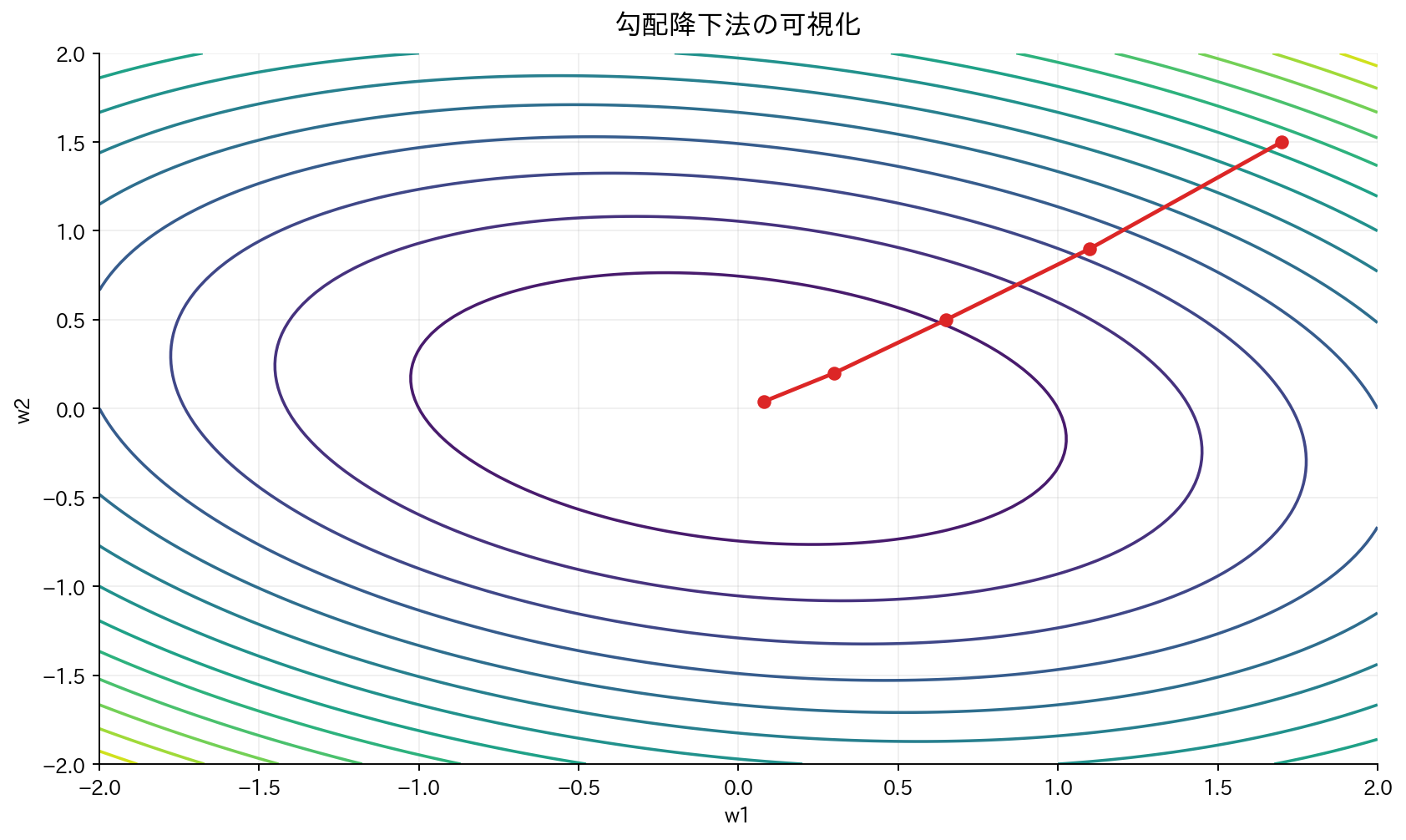
目的: 損失関数を最小化するパラメータを見つける
基本的な更新式:
ここで:
- $\eta$:学習率(どれだけ大きく更新するか)
- $\nabla J$:損失関数の勾配(どの方向に更新するか)
山登りのアナロジー
勾配降下法は「山を下る」ことに例えられます:
- 現在地:現在のパラメータ値
- 傾き:勾配(どの方向が下り坂か)
- 歩幅:学習率(どれだけ大きく歩くか)
- 目標:谷底(損失関数の最小値)
学習率の重要性
[図5] 最適化過程
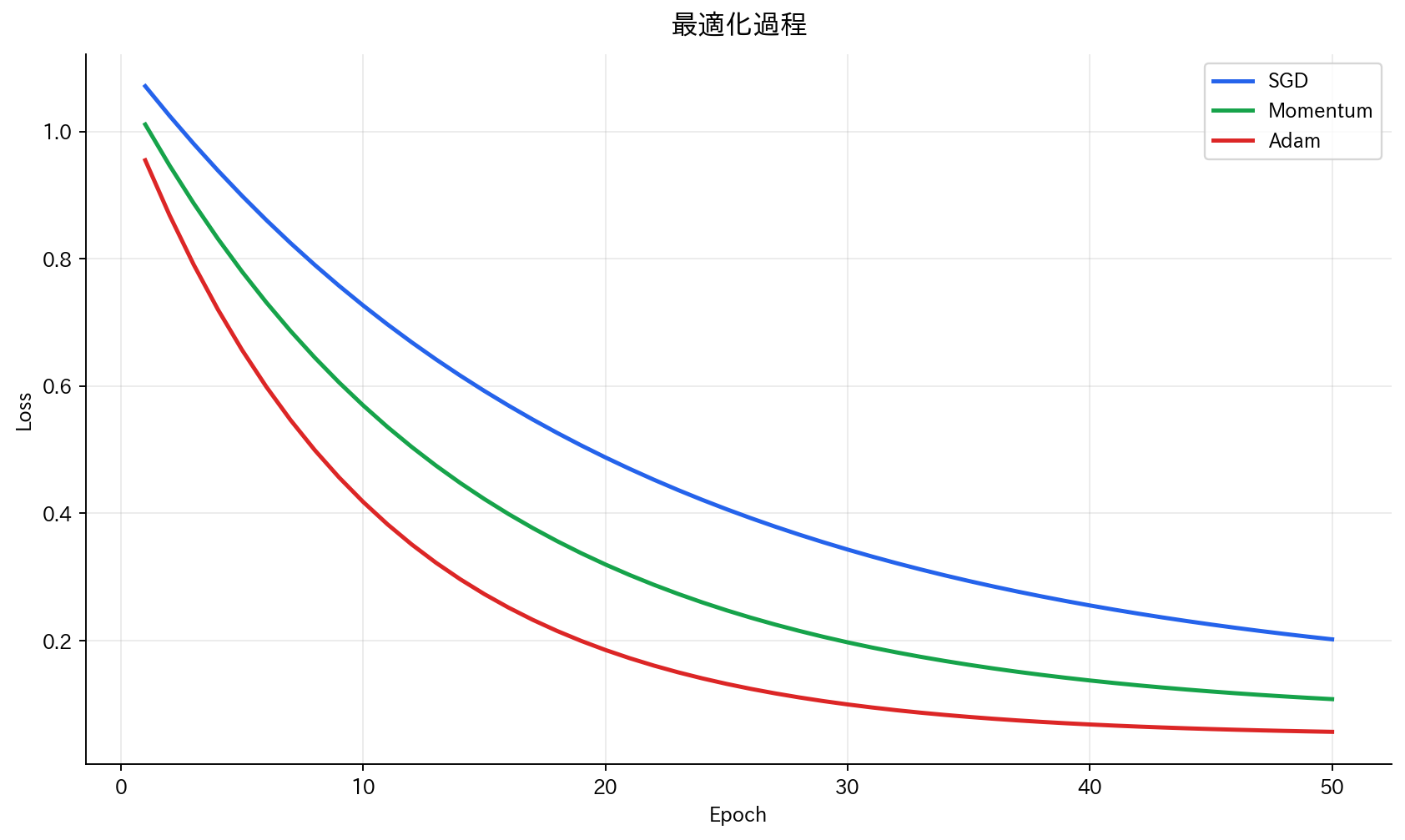
学習率による影響
学習率が大きすぎる場合:
- メリット:高速に学習が進む
- デメリット:最適解を飛び越えて発散する可能性
学習率が小さすぎる場合:
- メリット:安定した学習
- デメリット:学習が遅い、局所解に陥りやすい
適切な学習率:
- 安定して最適解に向かう
- 実用的な時間で収束
学習率の調整方法
固定学習率:
learning_rate = 0.01 # 一定値を使用
学習率減衰:
# エポックが進むにつれて学習率を減少
learning_rate = initial_lr / (1 + decay_rate * epoch)
適応的学習率:
- Adam、RMSprop等のアルゴリズム
- パラメータごとに学習率を自動調整
コラム:バッチサイズの違い
最適化では、データの使い方によって異なる手法があります。
3つの手法
バッチ勾配降下法:
- 全データを一度に使用
- 安定した学習、計算コスト高
確率的勾配降下法(SGD):
- 1つのデータずつ使用
- 高速、ノイズが多い
ミニバッチ勾配降下法:
- 小さなグループ(例:32個)ずつ使用
- バランスが良い、最も一般的
実際の使い分け
# ミニバッチサイズの例
batch_size = 32 # 32個のデータを一度に処理
for epoch in range(num_epochs):
for batch in data_loader(batch_size):
# バッチごとに勾配を計算・更新
loss = compute_loss(batch)
gradients = compute_gradients(loss)
update_parameters(gradients)
コラム:過学習と学習曲線
最適化の過程で重要なのが過学習の監視です。
学習曲線の見方
[図3] 学習曲線の例
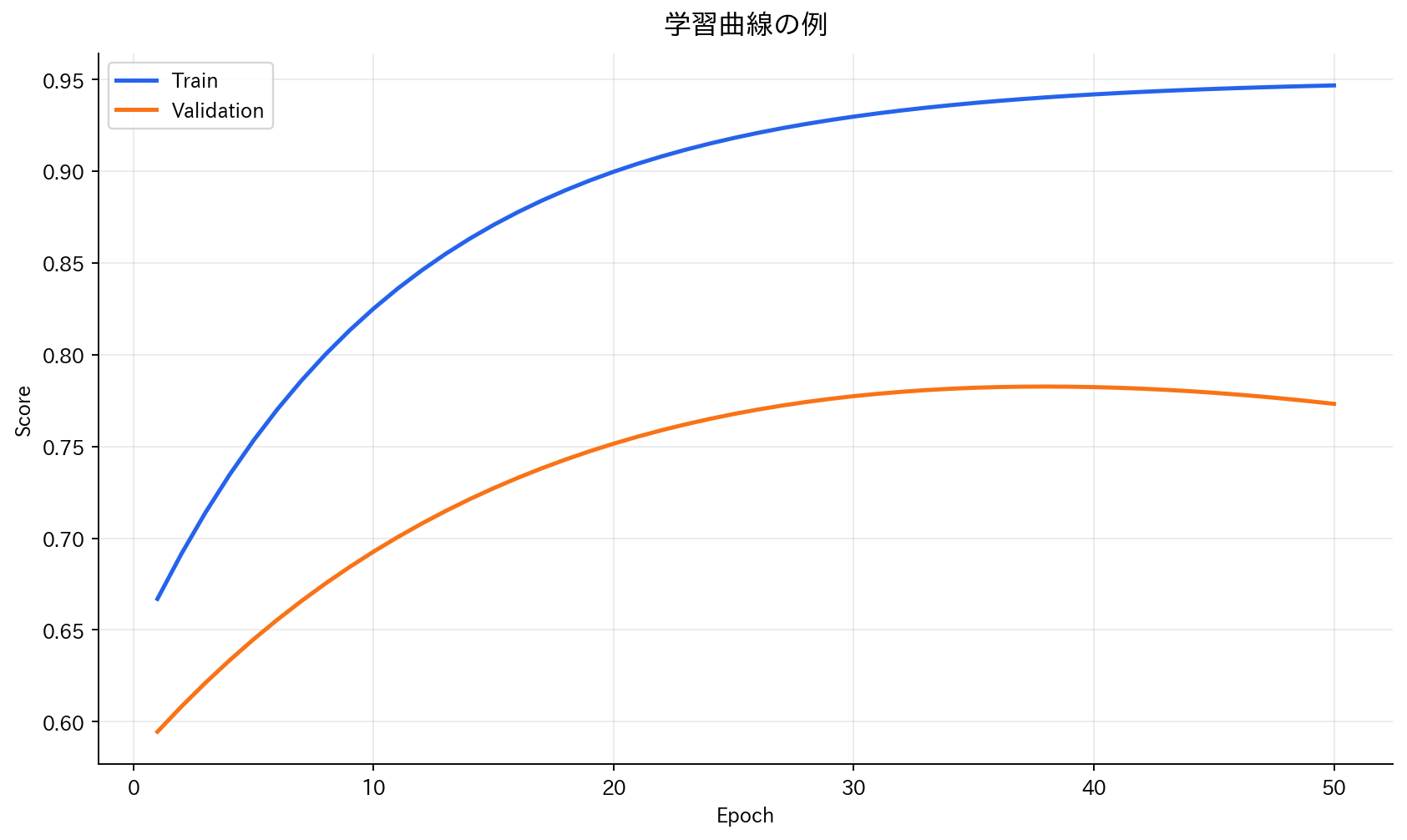
訓練損失:訓練データでの損失 検証損失:検証データでの損失
理想的なケース:
- 両方の損失が同じように減少
- 最終的に似たような値に収束
過学習のケース:
- 訓練損失は減少し続ける
- 検証損失は途中から増加に転じる
対処法
早期停止(Early Stopping):
best_val_loss = float('inf')
patience = 5 # 5回連続で改善しなかったら停止
for epoch in range(max_epochs):
train_model()
val_loss = validate_model()
if val_loss < best_val_loss:
best_val_loss = val_loss
patience_counter = 0
else:
patience_counter += 1
if patience_counter >= patience:
print(f"早期停止: エポック {epoch}")
break
実装例
基本的な勾配降下法
import numpy as np
import matplotlib.pyplot as plt
# 簡単な線形回帰での勾配降下法
def gradient_descent_example():
# データ生成(y = 2x + 1 + ノイズ)
np.random.seed(42)
X = np.random.randn(100, 1)
y = 2 * X.flatten() + 1 + 0.1 * np.random.randn(100)
# パラメータ初期化
w = 0.0 # 重み
b = 0.0 # バイアス
learning_rate = 0.01
epochs = 1000
losses = []
for epoch in range(epochs):
# 予測
y_pred = w * X.flatten() + b
# 損失計算(MSE)
loss = np.mean((y - y_pred) ** 2)
losses.append(loss)
# 勾配計算
dw = -2 * np.mean((y - y_pred) * X.flatten())
db = -2 * np.mean(y - y_pred)
# パラメータ更新
w -= learning_rate * dw
b -= learning_rate * db
if epoch % 100 == 0:
print(f"エポック {epoch}: 損失 = {loss:.4f}")
print(f"最終パラメータ: w = {w:.3f}, b = {b:.3f}")
print(f"真の値: w = 2.0, b = 1.0")
return losses
# 実行例
losses = gradient_descent_example()
scikit-learnでの実装
from sklearn.linear_model import SGDRegressor, SGDClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 回帰の例
def sgd_regression_example():
# データ準備
X = np.random.randn(1000, 3)
y = 2*X[:,0] + 3*X[:,1] - X[:,2] + np.random.randn(1000) * 0.1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 正規化(SGDには重要)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# SGD回帰
model = SGDRegressor(learning_rate='constant', eta0=0.01, max_iter=1000)
model.fit(X_train_scaled, y_train)
# 評価
train_score = model.score(X_train_scaled, y_train)
test_score = model.score(X_test_scaled, y_test)
print(f"訓練R²: {train_score:.3f}")
print(f"テストR²: {test_score:.3f}")
sgd_regression_example()
まとめ
損失関数と最適化は機械学習の核心的な概念です。重要なポイント:
- 損失関数の選択:問題に応じてMSE、MAE、交差エントロピーなどを使い分け
- 勾配降下法の理解:「山を下る」ように最適解を探索
- 学習率の重要性:大きすぎず小さすぎない適切な値設定
- 過学習の監視:訓練・検証損失の両方を確認
- 実装のポイント:正規化、バッチサイズ、早期停止などの技術
これらの概念を理解することで、機械学習モデルの学習過程を適切に制御できるようになります。
次章では、モデルの評価と汎化性能向上のための「訓練・検証・テストデータの分割」について学習します。