クラスタリング
クラスタリングは、ラベル情報なしでデータを類似したグループに分割する教師なし学習の中核的手法です。顧客セグメンテーション、遺伝子発現解析、画像分割など幅広い分野で活用されています。本章では、代表的なクラスタリング手法の理論的基盤から実践的応用まで体系的に学習します。
クラスタリングの基本概念
問題設定と目的
[図2] クラスタリングの基本概念
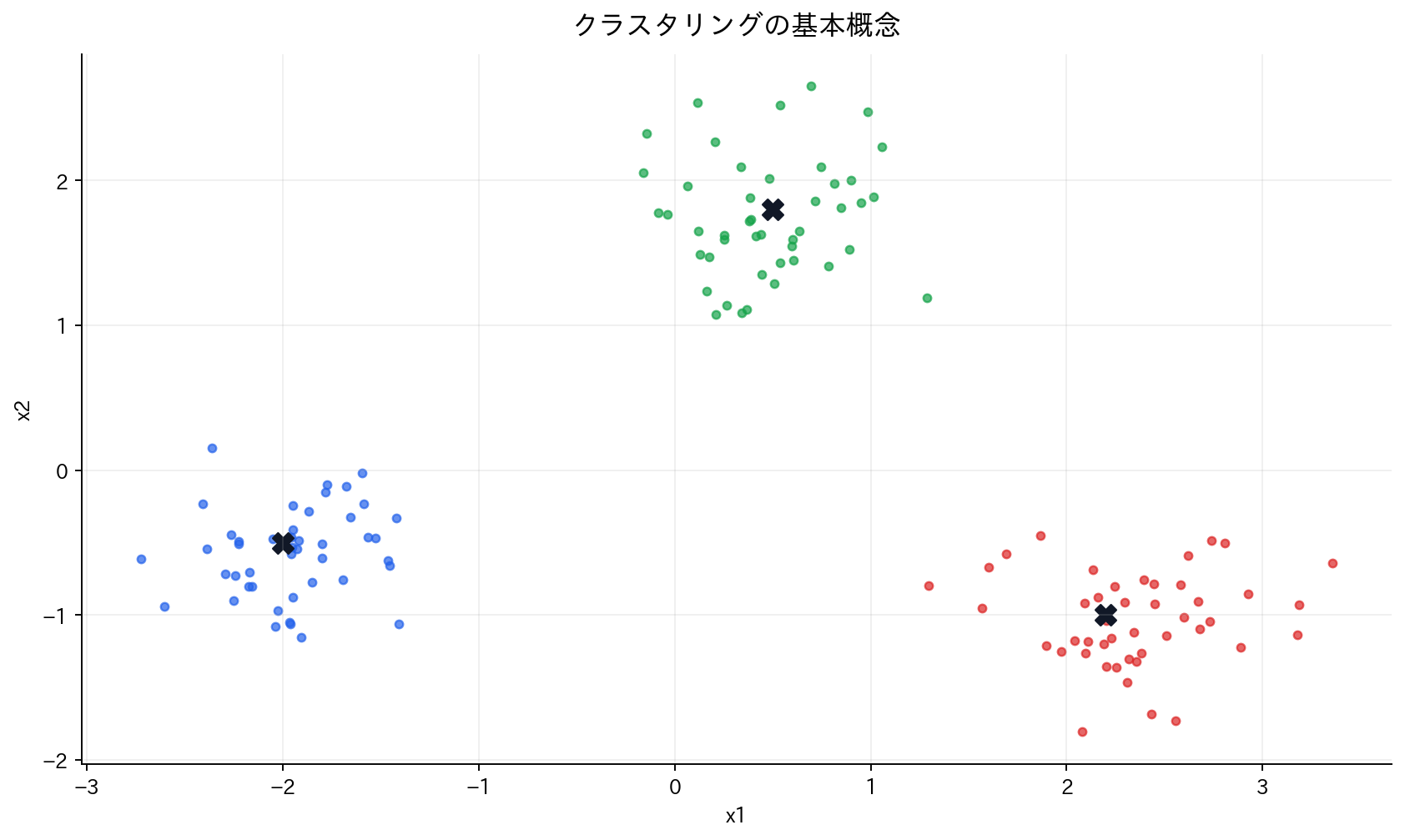
クラスタリングは、教師なし学習における最も基本的で重要な問題の一つです。この問題を数学的に定義すると、$n$個のデータポイント$\{x_1, x_2, \ldots, x_n\}$を$k$個のクラスタ$\{C_1, C_2, \ldots, C_k\}$に分割することになります。
クラスタリングの品質を判断する際には、3つの基本的な要求を満たす必要があります。第一に、クラスタ内同質性として、同一クラスタに属するデータポイント同士は可能な限り類似していることが求められます。第二に、クラスタ間異質性として、異なるクラスタに属するデータポイントは明確に区別できるほど相異していることが重要です。第三に、網羅性として、全てのデータポイントが必ずいずれかのクラスタに属する必要があります。
これらの要求を数学的に表現すると、排他性の条件$C_i \cap C_j = \emptyset$ (i ≠ j)と、網羅性の条件$\bigcup_{i=1}^{k} C_i = \{x_1, \ldots, x_n\}$として表すことができます。しかし、実際のクラスタリングでは、これらの理想的な条件と現実のデータの複雑さとの間で適切なバランスを見つけることが重要な課題となります。
類似度と距離の定義
[図3] 類似度と距離の定義
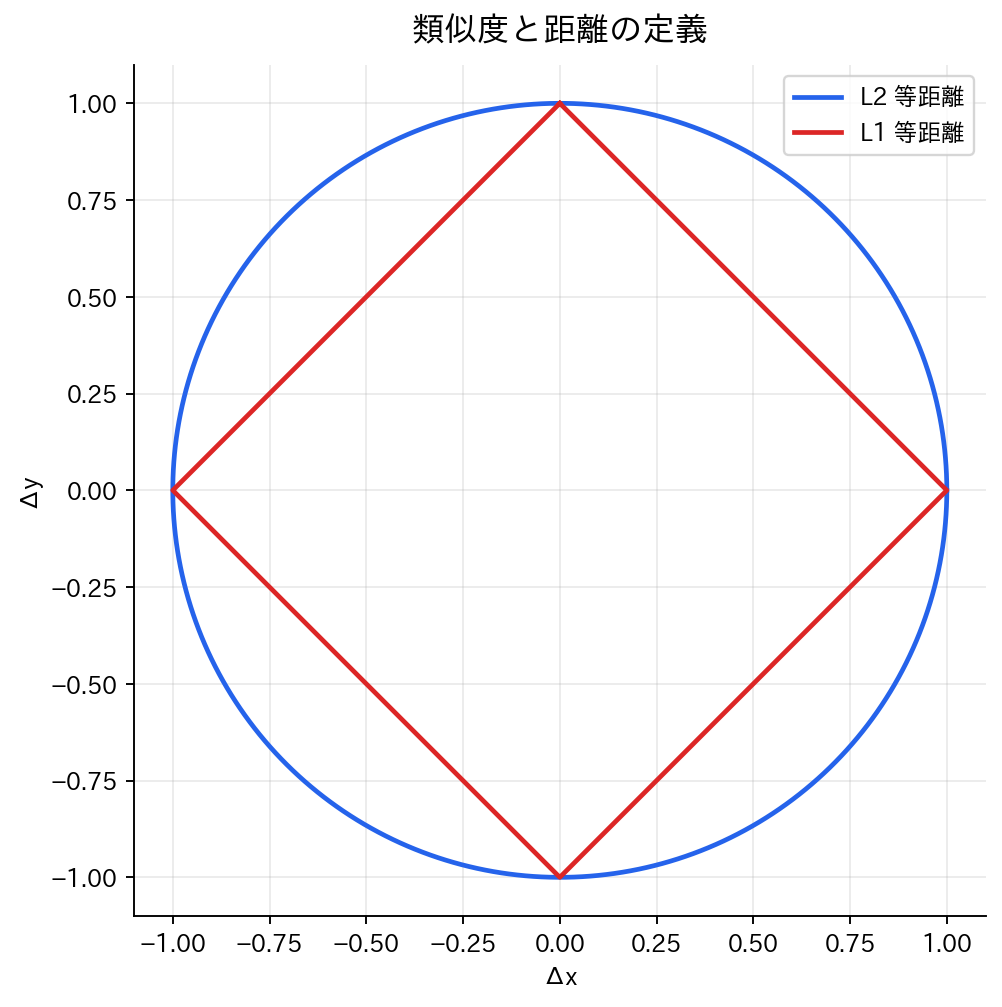
クラスタリングの成功は、データポイント間の類似度や距離をいかに適切に定義するかに大きく依存します。この選択は、データの性質やドメインの特性を深く理解した上で行う必要があります。
最も一般的なユークリッド距離は、各次元の差の二乗和の平方根として定義されます:
一方、マンハッタン距離は絶対値の和として定義され、外れ値の影響をユークリッド距離よりも受けにくい性質を持ちます:
テキストデータや高次元データでは、コサイン類似度がよく使用されます:
より高度な距離として、マハラノビス距離があります:
k-means法
関連教材(青の統計学)
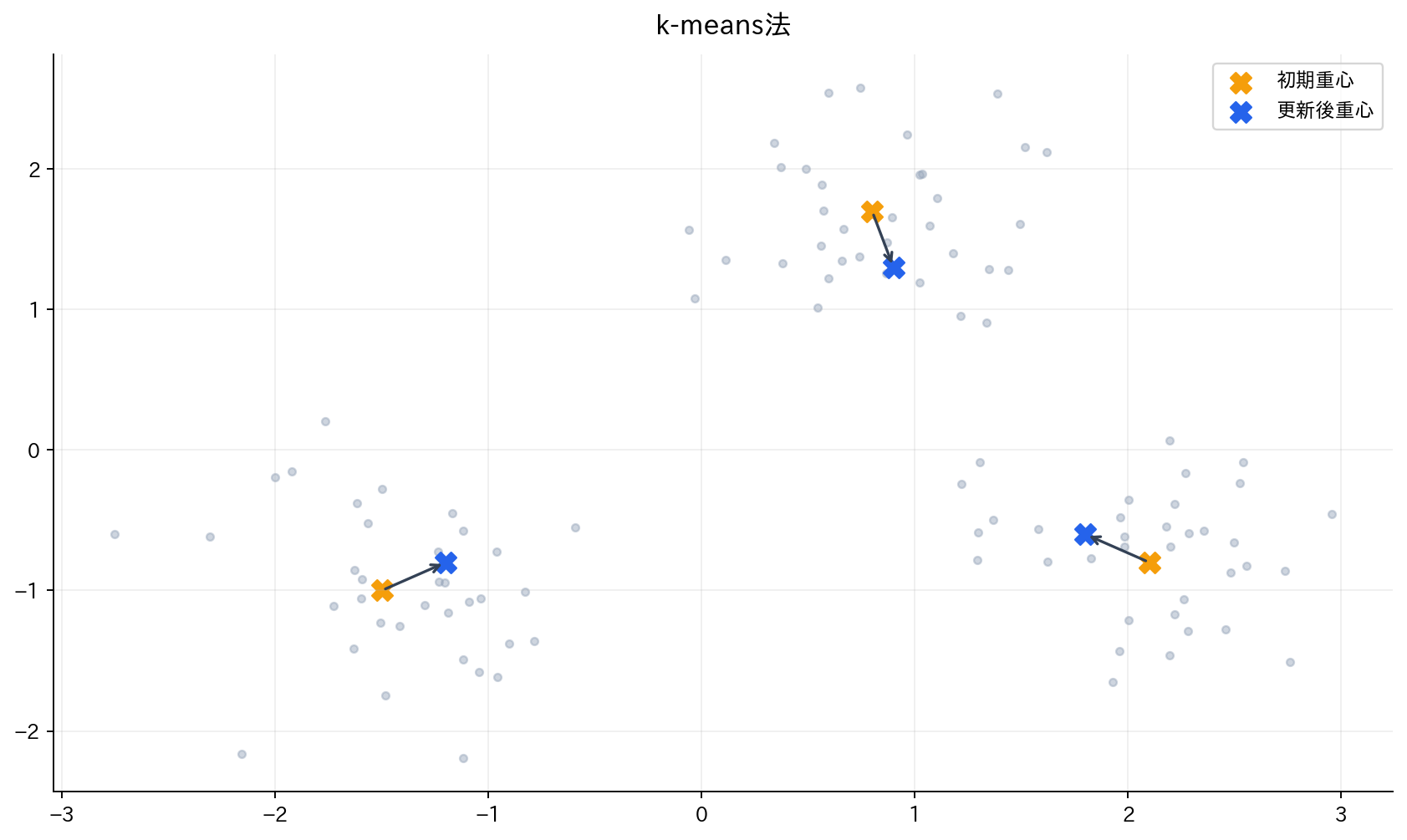
[図4] k-means法
基本アルゴリズム
[図5] 基本アルゴリズム
k-means法は、各クラスタの重心からの距離の二乗和を最小化するクラスタリング手法です。
目的関数:
ここで$\mu_i$はクラスタ$C_i$の重心です。
Lloyd's Algorithm(標準k-means):
- 初期化:$k$個のクラスタ重心をランダムに設定
- 割り当て:各データを最も近い重心のクラスタに割り当て
- 更新:各クラスタの重心を再計算
- 収束判定:重心が変化しなくなるまで手順2-3を繰り返し
重心の更新式:
k-meansの性質
収束性:
- 目的関数は単調減少
- 有限ステップで収束(実際は局所最適解)
計算複雑度:
- 1回の反復:$O(nkd)$($n$:データ数、$k$:クラスタ数、$d$:次元数)
- 総複雑度:$O(nkdt)$($t$:反復回数)
制約と仮定:
- クラスタ数$k$を事前に指定
- 球状クラスタを想定
- クラスタサイズが類似していることを想定
k-means++初期化
標準的なランダム初期化は局所最適解に陥りやすいため、より良い初期値選択手法が提案されています。
k-means++手順:
- 1つ目の重心をデータからランダムに選択
- 2つ目以降は、既存重心からの距離に比例した確率で選択
選択確率:
ここで$D(x)$は点$x$から最も近い既存重心までの距離です。
理論的保証: k-means++は最適解のコストの$O(\log k)$倍以内の解を期待値的に見つけることが証明されています。
階層クラスタリング
基本概念
階層クラスタリングは、データの階層的なクラスタ構造を発見する手法です。
2つのアプローチ:
- 凝集型(Agglomerative):各点から開始し、段階的に結合
- 分割型(Divisive):全データから開始し、段階的に分割
一般的には計算効率の良い凝集型が使用されます。
凝集型階層クラスタリング
アルゴリズム:
- 各データポイントを独立したクラスタとして初期化
- 最も近い2つのクラスタを結合
- クラスタ数が1になるまで手順2を繰り返し
結果: デンドログラム(樹形図)として階層構造を可視化
クラスタ間距離(結合基準)
単結合(Single Linkage):
- 細長いクラスタを作りやすい
- ノイズに敏感
完全結合(Complete Linkage):
- 球状クラスタを作りやすい
- 外れ値に敏感
平均結合(Average Linkage):
- バランスの取れた結果
- 計算コストが高い
Ward法: 結合によるクラスタ内分散の増加を最小化
- 等サイズクラスタを好む
- k-meansと類似した結果
デンドログラムの解釈
切断レベル決定:
- 肘方法:分散減少率の変曲点
- シルエット解析:クラスタ品質指標
- ドメイン知識:業務的な意味づけ
密度ベースクラスタリング(DBSCAN)
基本概念
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)は、データの密度に基づいてクラスタを形成し、ノイズを自動的に識別する手法です。
主要パラメータ:
- $\epsilon$:近傍半径
- $\text{minPts}$:コアポイント判定の最小ポイント数
ポイントの分類:
- コアポイント:$\epsilon$近傍に$\text{minPts}$以上のポイント
- 境界ポイント:コアポイントでないが、コアポイントの近傍にある
- ノイズポイント:上記以外のポイント
アルゴリズム:
- 未訪問のコアポイントを見つけて新しいクラスタを開始
- 密度接続可能なポイントを再帰的に追加
- 全ポイントが処理されるまで繰り返し
DBSCANの利点
任意形状のクラスタ: 球状でない複雑な形状のクラスタも発見可能
ノイズ検出: 外れ値を自動的に識別し、ノイズとしてラベル付け
クラスタ数の自動決定: 事前にクラスタ数を指定する必要なし
パラメータ選択
$\epsilon$の選択:
- k-distance plot(k-nearest neighbor距離のソート順プロット)
- 急激な変化点を$\epsilon$として選択
$\text{minPts}$の選択:
- 一般的に$\text{minPts} = 2 \times d$($d$は次元数)
- ドメインによる調整が必要
コラム:クラスタ数の決定方法
エルボー法(Elbow Method)
k-meansの目的関数値(WCSS:Within-Cluster Sum of Squares)をクラスタ数に対してプロットし、急激な減少が止まる点(肘)を最適クラスタ数とする方法。
WCSS計算:
シルエット分析
各データポイントのクラスタ適合度を定量化する指標。
シルエット係数:
ここで:
- $a(i)$:同一クラスタ内の他ポイントとの平均距離
- $b(i)$:最も近い他クラスタとの平均距離
値の解釈:
- $s(i) \approx 1$:良好なクラスタリング
- $s(i) \approx 0$:クラスタ境界上
- $s(i) \approx -1$:誤ったクラスタ割り当て
Gap統計量
データをランダム分布と比較してクラスタリングの有意性を評価。
最大のGap統計量を示すクラスタ数を選択。
コラム:高次元データでのクラスタリング
関連教材(青の統計学)
次元の呪いの影響
高次元空間では:
- 距離の意味が曖昧化
- 全データ間の距離が均一化
- 従来手法の性能劣化
対処法
次元削減 + クラスタリング:
- PCAで主要な分散方向を抽出
- 低次元空間でクラスタリング実行
部分空間クラスタリング:
- 各クラスタが異なる部分空間に存在することを仮定
- CLIQUE、SUBCLUなどの手法
特徴量選択との組み合わせ:
- クラスタリングに有効な特徴量のみを使用
- Wrapper法でクラスタリング性能を評価指標とする
実装例
各手法の比較実装
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_moons
from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import adjusted_rand_score, silhouette_score
import warnings
warnings.filterwarnings('ignore')
# データセット生成
datasets = {
'Blobs': make_blobs(n_samples=300, centers=4, n_features=2,
cluster_std=0.60, random_state=0),
'Moons': make_moons(n_samples=300, noise=0.1, random_state=0),
}
# アルゴリズム設定
algorithms = {
'K-Means': KMeans(n_clusters=4, random_state=0, n_init=10),
'Hierarchical': AgglomerativeClustering(n_clusters=4),
'DBSCAN': DBSCAN(eps=0.3, min_samples=10),
}
# 可視化
fig, axes = plt.subplots(len(datasets), len(algorithms) + 1,
figsize=(15, 10))
for i, (dataset_name, (X, y)) in enumerate(datasets.items()):
# 標準化
X_scaled = StandardScaler().fit_transform(X)
# 元データ
axes[i, 0].scatter(X_scaled[:, 0], X_scaled[:, 1], c=y, cmap='viridis')
axes[i, 0].set_title(f'{dataset_name} (Original)')
for j, (alg_name, algorithm) in enumerate(algorithms.items()):
# クラスタリング実行
if alg_name == 'DBSCAN':
y_pred = algorithm.fit_predict(X_scaled)
else:
y_pred = algorithm.fit(X_scaled).labels_
# 可視化
axes[i, j + 1].scatter(X_scaled[:, 0], X_scaled[:, 1],
c=y_pred, cmap='viridis')
axes[i, j + 1].set_title(f'{dataset_name} - {alg_name}')
# 評価指標計算
if len(set(y_pred)) > 1: # ノイズのみの場合を除外
ari = adjusted_rand_score(y, y_pred)
sil = silhouette_score(X_scaled, y_pred)
print(f"{dataset_name} - {alg_name}: ARI={ari:.3f}, Silhouette={sil:.3f}")
plt.tight_layout()
plt.show()
クラスタ数決定の実装
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
# データ生成
X, _ = make_blobs(n_samples=300, centers=4, n_features=2,
cluster_std=0.60, random_state=0)
X = StandardScaler().fit_transform(X)
# クラスタ数の範囲
k_range = range(2, 11)
# 各指標の計算
wcss = []
silhouette_scores = []
for k in k_range:
# k-means実行
kmeans = KMeans(n_clusters=k, random_state=0, n_init=10)
y_pred = kmeans.fit_predict(X)
# WCSS計算
wcss.append(kmeans.inertia_)
# シルエット係数計算
if k > 1:
sil_score = silhouette_score(X, y_pred)
silhouette_scores.append(sil_score)
# 可視化
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# エルボー法
ax1.plot(k_range, wcss, 'bo-')
ax1.set_xlabel('クラスタ数 k')
ax1.set_ylabel('WCSS')
ax1.set_title('エルボー法')
ax1.grid(True)
# シルエット分析
ax2.plot(range(2, 11), silhouette_scores, 'ro-')
ax2.set_xlabel('クラスタ数 k')
ax2.set_ylabel('シルエット係数')
ax2.set_title('シルエット分析')
ax2.grid(True)
plt.tight_layout()
plt.show()
# 最適クラスタ数
optimal_k = k_range[np.argmax(silhouette_scores) + 1]
print(f"シルエット分析による最適クラスタ数: {optimal_k}")
階層クラスタリングとデンドログラム
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
# データ準備
X, _ = make_blobs(n_samples=50, centers=3, n_features=2,
cluster_std=1.0, random_state=0)
X = StandardScaler().fit_transform(X)
# デンドログラム作成(scipy使用)
plt.figure(figsize=(15, 5))
# 異なる結合基準での比較
linkage_methods = ['single', 'complete', 'average', 'ward']
for i, method in enumerate(linkage_methods):
plt.subplot(1, 4, i + 1)
# 階層クラスタリング
Z = linkage(X, method=method)
# デンドログラム描画
dendrogram(Z, truncate_mode='level', p=5)
plt.title(f'{method.capitalize()} Linkage')
plt.xlabel('データポイント')
plt.ylabel('距離')
plt.tight_layout()
plt.show()
# 3クラスタでの結果比較
fig, axes = plt.subplots(1, 4, figsize=(16, 4))
for i, method in enumerate(linkage_methods):
# sklearn使用
if method == 'ward':
clustering = AgglomerativeClustering(n_clusters=3, linkage=method)
else:
clustering = AgglomerativeClustering(n_clusters=3, linkage=method)
y_pred = clustering.fit_predict(X)
axes[i].scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
axes[i].set_title(f'{method.capitalize()} Linkage')
# シルエット係数
sil_score = silhouette_score(X, y_pred)
axes[i].text(0.05, 0.95, f'Silhouette: {sil_score:.3f}',
transform=axes[i].transAxes,
bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
plt.tight_layout()
plt.show()
まとめ
クラスタリングは教師なし学習の中核的手法として幅広く活用されています。重要なポイント:
- 手法の特徴理解:k-means(球状)、階層(柔軟性)、DBSCAN(任意形状・ノイズ検出)
- 距離指標の重要性:データの性質に応じた適切な距離の選択
- クラスタ数決定:エルボー法、シルエット分析、Gap統計量等の活用
- 前処理の重要性:標準化、次元削減、外れ値処理
- 評価と解釈:内的指標(シルエット係数)と外的指標(ARI)の使い分け
これらの概念を理解することで、データの特性と目的に応じた最適なクラスタリング戦略を選択し、有意味なグループ分けを実現できるようになります。
次章では、機械学習の重要な応用分野である推薦システムについて学習します。