ニューラルネットワーク基礎
現代の機械学習において革命的な成果を生み出しているニューラルネットワークは、人間の脳の神経細胞(ニューロン)の働きからヒントを得た計算モデルです。画像認識、自然言語処理、音声認識など幅広い分野で従来手法を大幅に上回る性能を実現しています。本章では、ニューラルネットワークの基本原理から実装まで体系的に学習します。
この章で学ぶこと
- パーセプトロンから多層ネットワークへの発展を、線形分離可能性の観点で説明できる
- 活性化関数の役割と、勾配消失との関係を数式で説明できる
- 誤差逆伝播の連鎖律を、層ごとの誤差伝播として理解できる
- 初期化・学習率・勾配制御の実装上の要点を押さえられる
前提知識チェック
- 線形代数:ベクトル、行列積、転置
- 微分:合成関数の微分(連鎖律)
- 確率統計:損失関数と期待値の基本
パーセプトロン
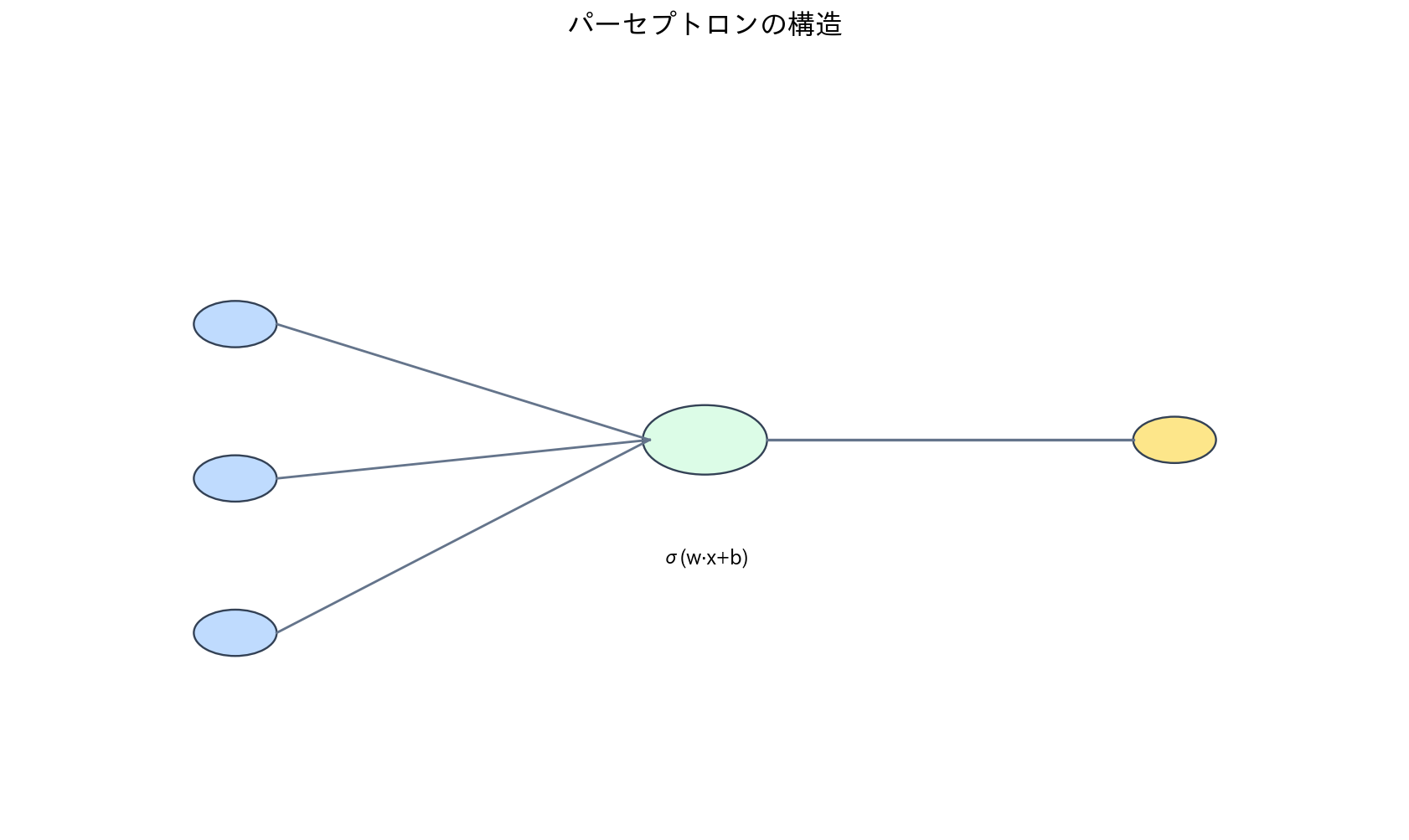
[図1] パーセプトロンの構造
最初の人工ニューロン
パーセプトロンは、1957年にFrank Rosenblattによって提案された最初の人工ニューロンモデルです。これは現代のニューラルネットワークの出発点となった重要な概念で、生物学的なニューロンの基本的な動作を数学的にモデル化したものです。
パーセプトロンの動作原理は非常にシンプルです。複数の入力信号を受け取り、それぞれに重み(weight)を掛けて合計し、その値が一定の閾値を超えた場合に活性化(出力1)し、そうでなければ非活性(出力0)となります。この仕組みは、生物学的ニューロンが複数のシナプスから信号を受け取り、それらの総和が閾値を超えると発火する現象を模倣しています。
数学的には、入力ベクトル$\mathbf{x} = (x_1, x_2, \ldots, x_n)$に対して、重みベクトル$\mathbf{w} = (w_1, w_2, \ldots, w_n)$と閾値$\theta$を用いて、以下のように表現されます:
パーセプトロンの幾何学的解釈
パーセプトロンを幾何学的に解釈すると、n次元空間における超平面による二分類器として理解できます。重みベクトル$\mathbf{w}$は超平面の法線方向を決定し、閾値$\theta$は原点からの距離を決定します。この超平面によって、入力空間が2つの領域に分割され、それぞれが異なるクラスに対応します。
この性質から、パーセプトロンは線形分離可能な問題のみを解くことができるという重要な制約があります。有名な例として、AND演算やOR演算は線形分離可能なためパーセプトロンで実現できますが、XOR演算は線形分離不可能なため単一のパーセプトロンでは解くことができません。
決定境界は
で表され、これは超平面です。
XOR が単層で解けない理由は、正例と負例を1枚の超平面で分離できない点にあります。
パーセプトロン学習アルゴリズム
パーセプトロンの学習は、誤分類されたサンプルに基づいて重みを更新していく反復的なプロセスです。アルゴリズムの基本的な手順は以下の通りです:
- 重みを小さなランダム値で初期化
- 各訓練サンプルに対して予測を計算
- 誤分類されたサンプルがあれば重みを更新
- 全サンプルが正しく分類されるまで繰り返し
重みの更新規則は次式で表されます:
ここで、$\eta$は学習率、$t$は正解ラベル、$y$は予測値、$x_i$は入力の第$i$成分です。
多層パーセプトロン
関連教材(青の統計学)
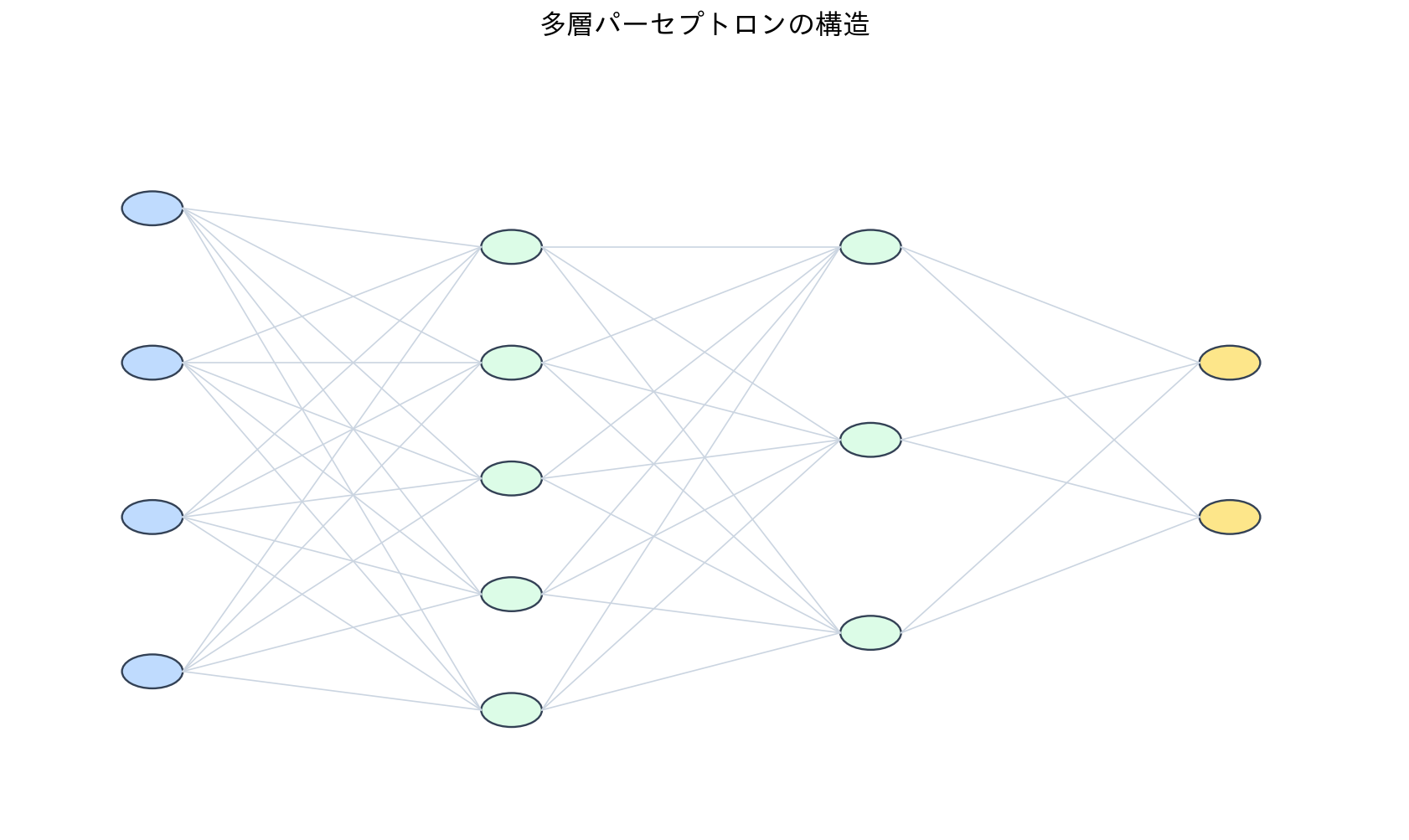
[図2] 多層パーセプトロンの構造
XOR問題の解決
パーセプトロンの線形分離可能性の制約を克服するために、複数のパーセプトロンを組み合わせた多層パーセプトロン(Multi-Layer Perceptron, MLP)が開発されました。この構造により、非線形な問題も解くことが可能になりました。
最も簡単な例として、XOR問題を考えてみましょう。単一のパーセプトロンでは解けないXOR関数も、隠れ層を持つ多層構造にすることで実現できます。隠れ層の各ニューロンが異なる線形境界を学習し、出力層でそれらを組み合わせることで、複雑な非線形境界を表現できるのです。
活性化関数の導入
多層パーセプトロンでは、各層の出力に非線形変換を適用する活性化関数が重要な役割を果たします。活性化関数がなければ、複数の線形変換を重ねても結局は線形変換にしかならないためです。
代表的な活性化関数には以下があります:
シグモイド関数:
tanh関数:
ReLU関数:
実務での見分け方として、シグモイドやtanhは「出力範囲を制約したいとき」、ReLU系は「深いネットワークを安定して学習したいとき」に使うのが基本です。
汎用近似定理
多層パーセプトロンの理論的基盤として、汎用近似定理(Universal Approximation Theorem)があります。この定理は、十分な数の隠れユニットを持つ1つの隠れ層があれば、任意の連続関数を任意の精度で近似できることを保証します。
この定理により、ニューラルネットワークが理論上あらゆる関数を学習できる能力を持つことが示されています。ただし、実際には「十分な数」がどの程度かは問題に依存し、効率的な学習のためには深い構造が有効であることが実証されています。
誤差逆伝播アルゴリズム
関連教材(青の統計学)
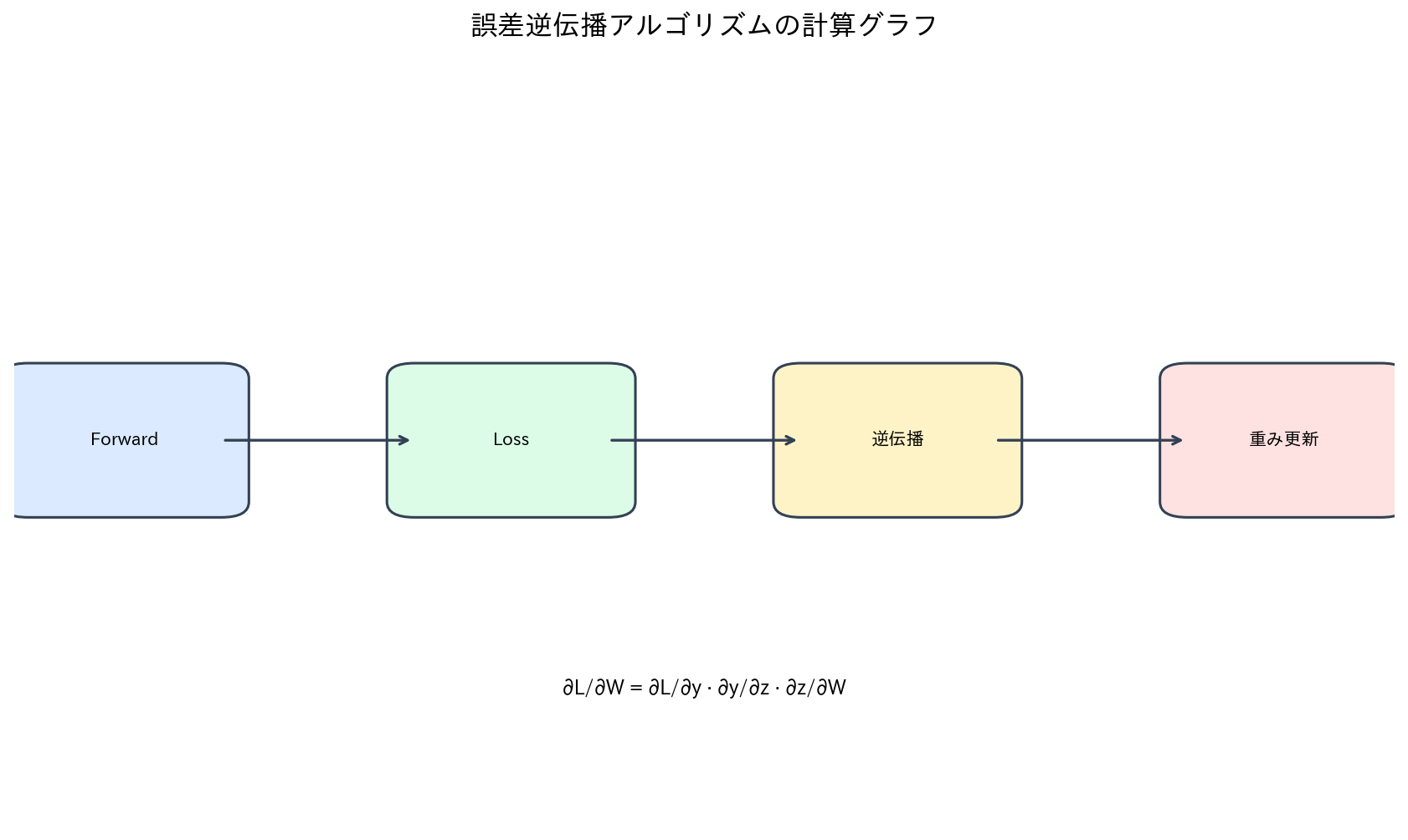
[図3] 誤差逆伝播アルゴリズムの計算グラフ
勾配の連鎖律による計算
多層ニューラルネットワークの学習において最も重要な技術が誤差逆伝播(Backpropagation)アルゴリズムです。これは、出力層から入力層に向かって誤差を逆向きに伝播させることで、各層の重みに対する勾配を効率的に計算する手法です。
誤差逆伝播の数学的基盤は、微積分学の連鎖律(Chain Rule)にあります。複合関数の導関数を計算する連鎖律を利用することで、多層構造における各重みパラメータの損失関数に対する偏微分を計算できます。
L層のニューラルネットワークにおいて、第$l$層の重み$W^{(l)}$に対する損失関数$J$の勾配は、以下のように計算されます:
ここで、$z^{(l)}$は第$l$層の線形結合出力、$a^{(l)}$は活性化関数適用後の出力を表します。
実装時に重要なのは、層ごとの誤差項 $\delta^{(l)}$ を再帰で計算できることです。
この形に整理すると、NumPy実装でもPyTorch実装でも同じロジックで追跡できます。
勾配降下法による重み更新
[図4] 最適化アルゴリズムの比較
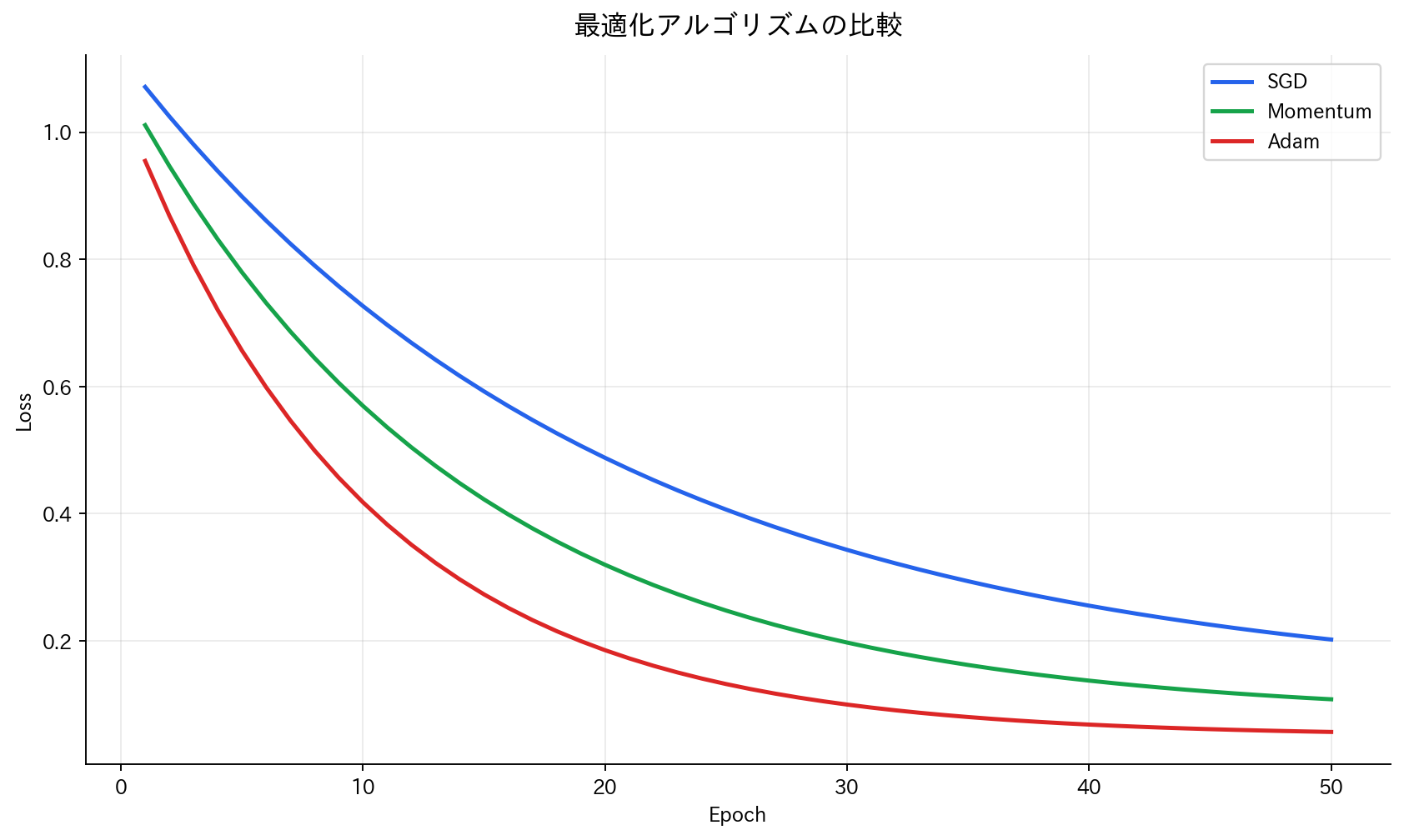
誤差逆伝播で計算された勾配を用いて、勾配降下法により重みを更新します。各重みパラメータ$w_{ij}$は以下のルールで更新されます:
ここで$\eta$は学習率です。この更新を全ての重みパラメータに対して繰り返すことで、ニューラルネットワークは目的とする関数を学習していきます。
勾配消失問題
深いニューラルネットワークでは、勾配が後ろの層から前の層に伝播する際に急速に小さくなる勾配消失問題が発生することがあります。これは特にシグモイド関数のような飽和する活性化関数を使用した場合に顕著に現れます。
勾配消失問題の対策として、ReLU系の活性化関数の使用、適切な重み初期化手法、正規化技術などが開発されています。これらの技術により、より深いネットワークの訓練が可能になりました。
加えて、勾配爆発への対策として gradient clipping を併用することが実務では一般的です。
コラム:ニューラルネットワークの歴史的発展
第一次AIブーム(1950年代-1960年代)
ニューラルネットワークの歴史は、1943年のMcCulloch-Pittsモデルに始まります。これは生物学的ニューロンの数学的モデル化の最初の試みでした。1957年にはRosenblattがパーセプトロンを提案し、機械が学習できることを実証しました。
しかし、1969年にMinsktyとPapertが著書「パーセプトロン」でパーセプトロンの限界(XOR問題など)を数学的に証明したことで、この分野への関心は急速に低下しました。これが第一次AIの冬と呼ばれる時期の始まりでした。
第二次AIブーム(1980年代)
1986年にRumelhartらによって誤差逆伝播アルゴリズムが再発見・普及されると、多層ニューラルネットワークの訓練が実用的になりました。これによりXOR問題をはじめとする非線形問題が解けるようになり、ニューラルネットワークへの関心が再び高まりました。
この時期には、Hopfieldネットワークやボルツマンマシンなど、様々なアーキテクチャが提案されました。しかし、1990年代にはSVMやランダムフォレストなどのより安定した手法が注目され、再びニューラルネットワークへの関心は低下しました。
深層学習革命(2010年代-現在)
2006年のHintonらによる深層信念ネットワーク、2012年のImageNetコンテストでのAlexNetの圧勝を契機として、深層学習が爆発的に発展しました。GPUの活用、大量データの利用可能性、改良されたアルゴリズムが相まって、かつてない性能を実現しています。
現在では、画像認識、自然言語処理、音声認識、ゲームAIなど、あらゆる分野でニューラルネットワークが最先端の性能を達成しています。
コラム:重み初期化の重要性
適切な初期化の必要性
ニューラルネットワークの訓練において、重みの初期値設定は学習の成功を左右する重要な要素です。不適切な初期化は、勾配消失・爆発問題や学習の停滞を引き起こす可能性があります。
全ての重みを0で初期化すると、各層のニューロンが同じ値を出力し、同じ勾配を受け取るため、学習が進みません。一方、重みが大きすぎると勾配爆発が、小さすぎると勾配消失が発生しやすくなります。
主要な初期化手法
Xavier初期化(Glorot初期化): 各層の入力・出力ユニット数を考慮した初期化手法で、重みを以下の分布から抽出します:
He初期化: ReLU系の活性化関数に適した初期化手法で、以下の分布を使用します:
これらの初期化手法により、各層の出力分散を適切に保つことで、深いネットワークでも安定した学習が可能になります。
数式から実装への対応づけ
この章の要点は「式を追えること」と「配列実装へ落とせること」をつなぐ点にあります。
特に逆伝播では、各式がどのテンソル操作に対応するかを明確にすると理解が一気に安定します。
| 数式 | 実装上の意味 |
|---|---|
| $\delta^{(l)} = (W^{(l+1)})^\top \delta^{(l+1)} \odot g'(z^{(l)})$ | 上位層誤差を現在層へ伝播し、活性化微分を掛ける |
| $\frac{\partial J}{\partial W^{(l)}} = \delta^{(l)} (a^{(l-1)})^\top$ | 誤差項と前層出力の外積で重み勾配を作る |
| $W^{(l)} \leftarrow W^{(l)} - \eta \frac{\partial J}{\partial W^{(l)}}$ | 学習率付きで勾配降下更新する |
1層分の更新式(NumPy)
# delta_l: (units_l, batch_size)
# a_prev: (units_prev, batch_size)
dW = (delta_l @ a_prev.T) / batch_size
db = np.mean(delta_l, axis=1, keepdims=True)
W_l -= eta * dW
b_l -= eta * db
勾配のshapeが合わないときは、ほぼ必ず「行列の向き」か「バッチ軸の定義」がずれています。
この段階でshapeを明示して追うのが最短です。
XORで非線形性を確認する最小例
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=float)
y = np.array([[0], [1], [1], [0]], dtype=float)
# 2 -> 4 -> 1 の最小MLPを学習(擬似)
model = TinyMLP(layers=[2, 4, 1], activation="tanh")
model.fit(X, y, epochs=2000, lr=0.1)
print(model.predict(X).round(3))
単層で解けないXORが、多層+非線形活性化で解けることを確認すると、
「なぜ活性化関数が必要か」を式ではなく挙動として理解できます。
まとめ
ニューラルネットワーク基礎で最重要なのは、パーセプトロンの限界と逆伝播の連鎖律を、同じ問題設定で往復できることです。
この往復ができると、次章の深層学習で出てくるCNN・LSTM・Transformerも「構造が違うだけで学習原理は同じ」と整理しやすくなります。
次のステップ
次章では、ここで学んだ最適化・正則化・勾配伝播を前提に、
より深いネットワーク設計と実務での安定学習の進め方を扱います。