決定木とランダムフォレスト:ルールベース学習からアンサンブルへ
Stage 2 — 第3章| 機械学習基礎カリキュラム 推定学習時間:70〜80分 | 難易度:★★★☆☆
この章で学ぶこと
「もし年齢が30歳未満で、かつ年収が500万円以上なら、融資を承認する」——このような「もし〜なら」のルールで判断を下すことは、人間にとって最も自然な意思決定方法です。決定木は、まさにこの直感的な判断プロセスをアルゴリズム化したものです。
これまで学んだ線形回帰やロジスティック回帰は、すべての特徴量を組み合わせて一つの式で予測を行いました。一方、決定木は特徴量を一つずつ見て、段階的に判断を下していきます。この違いが、決定木に独特の強みと弱みをもたらします。
この章を終えると、こんなことができるようになります:
- なぜ決定木が解釈しやすいモデルなのか理解できる
- ジニ不純度やエントロピーを使った最適な分割の選び方を説明できる
- 過学習しやすい決定木の弱点と、それを克服する剪定の方法を理解できる
- ランダムフォレストがどのように決定木の弱点を補うか説明できる
- 特徴量重要度を使って、どの変数が予測に効いているか分析できる
1. なぜ決定木が必要か
人間の意思決定プロセスの模倣
私たちが日常的に行う判断を考えてみましょう。例えば、週末に外出するかどうかを決めるとき:
- まず天気を確認する(晴れか雨か)
- 晴れなら外出、雨なら次を考える
- 雨でも、予定があるかチェック
- 重要な予定があれば外出、なければ家にいる
このような段階的な判断プロセスは、複雑な要因を一つずつ整理して結論に至る効率的な方法です。決定木はまさにこのプロセスをアルゴリズム化したものです。
線形モデルの限界
線形回帰やロジスティック回帰は強力な手法ですが、いくつかの限界があります:
非線形な関係の表現が困難:例えば「年齢が20〜30歳の間だけリスクが高い」といった関係は、線形モデルでは直接表現できません。
特徴量間の相互作用:「高所得かつ若年層」という条件は、線形モデルでは交互作用項を明示的に追加する必要があります。
解釈の難しさ:多数の特徴量が複雑に組み合わさった線形式から、具体的な判断ルールを読み取ることは困難です。
決定木はこれらの問題を自然に解決します。
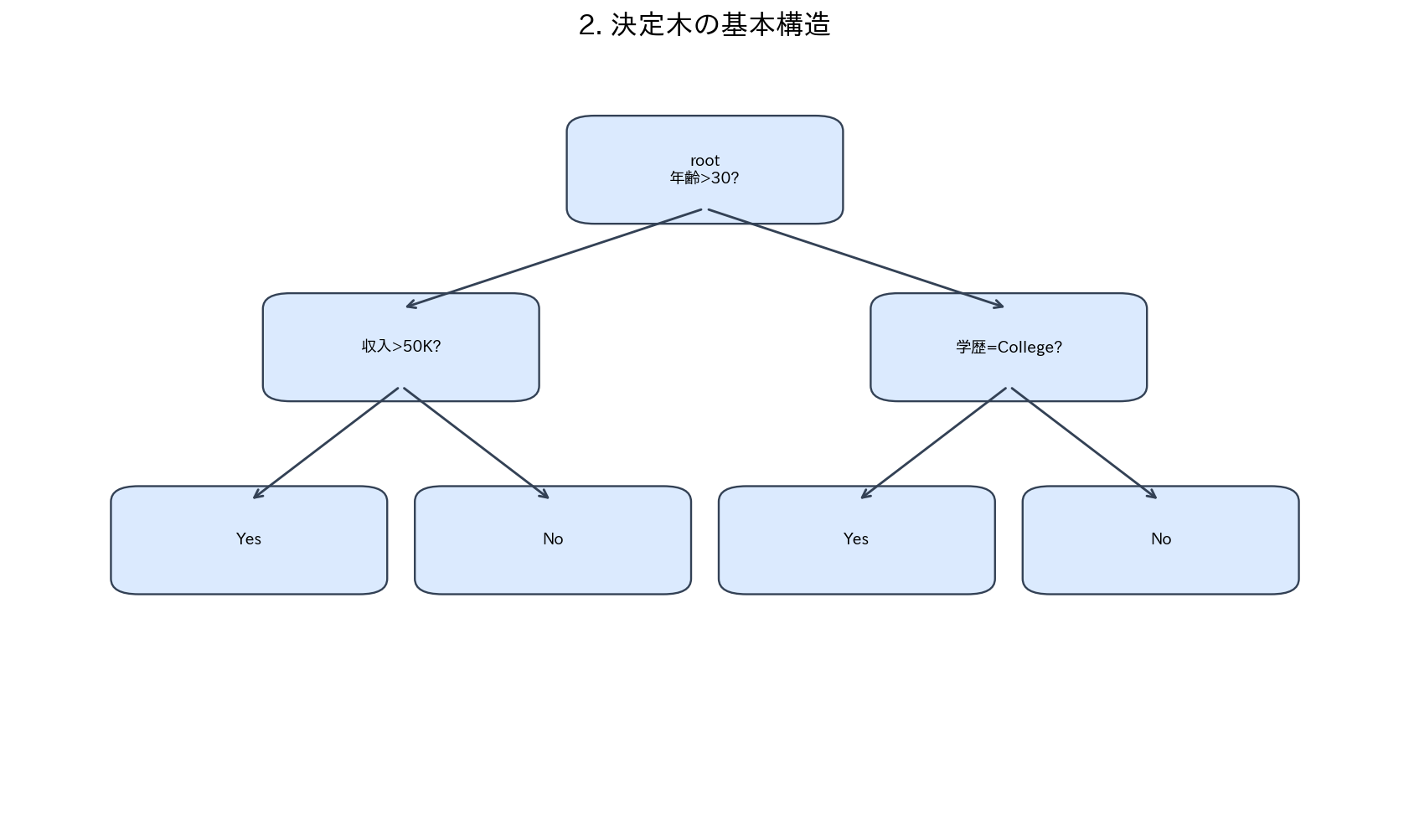
2. 決定木の基本構造
[図4] 2. 決定木の基本構造
木構造による分類の仕組み
[図5] 木構造による分類の仕組み
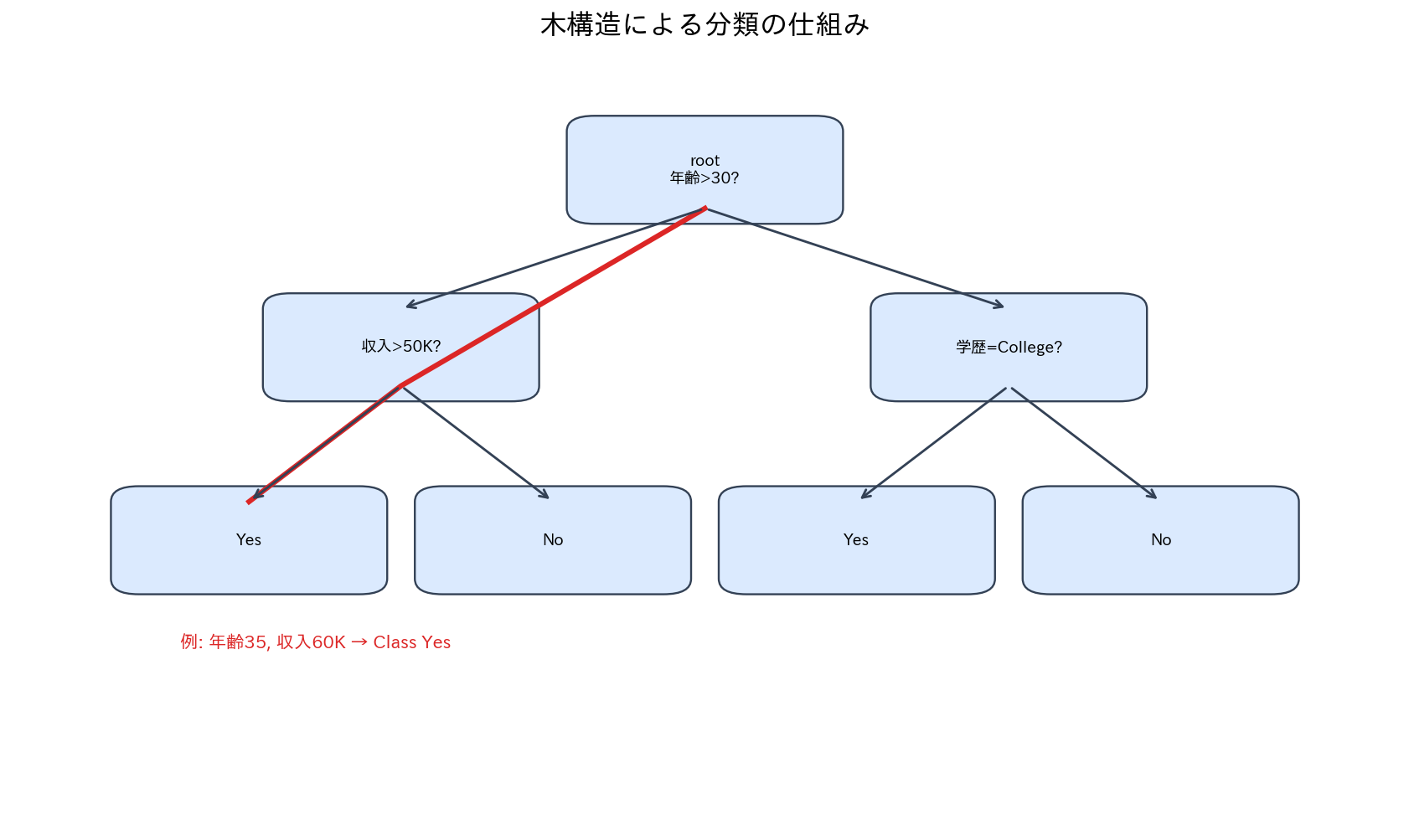
決定木は、根(root)から葉(leaf)に向かって、データを段階的に分割していく構造です。各内部ノードで一つの特徴量に基づいた判断を行い、最終的に葉ノードで予測値を出力します。
年齢 < 30?
/ \
Yes/ \No
/ \
収入 < 50K? 信用スコア < 700?
/ \ / \
Yes/ \No Yes/ \No
/ \ / \
拒否 承認 拒否 承認
この図を見ると、決定木がどのように判断を下しているか一目瞭然です。例えば「25歳で年収60万ドル」の申請者は、「年齢 < 30?」で左に進み、「収入 < 50K?」で右に進んで「承認」に至ります。
数学的な定式化
より厳密に、決定木の分割を定式化してみましょう。
各ノード $t$ において、特徴量 $j$ と閾値 $\theta$ の組 $(j, \theta)$ を選んで、データを2つのグループに分割します:
- 左の子ノード:$t_L = \{(\mathbf{x}, y) : x_j \leq \theta\}$
- 右の子ノード:$t_R = \{(\mathbf{x}, y) : x_j > \theta\}$
問題は、最適な $(j^*, \theta^*)$ をどう選ぶかです。直感的には、分割後の各グループがより「純粋」(同じクラスのサンプルばかり)になるような分割が良いはずです。この「純粋さ」を定量化する指標が必要になります。
3. 分岐基準:不純度の測定
関連教材(青の統計学)
なぜ不純度を測る必要があるか
決定木を構築する際の核心的な問題は、「どの特徴量のどの値で分割するのが最も良いか」です。良い分割とは、分割後の各グループがより「純粋」になる分割です。
例えば、100個のサンプル(50個がクラスA、50個がクラスB)があるとします。ある特徴量で分割した結果:
- 分割1:左に[A:45, B:5]、右に[A:5, B:45] → 各グループがほぼ純粋
- 分割2:左に[A:25, B:25]、右に[A:25, B:25] → 分割前と変わらない
明らかに分割1の方が良いですが、これを数値化する必要があります。
ジニ不純度:確率論的アプローチ
ジニ不純度は、最も広く使われる不純度指標の一つです。ノード $t$ におけるクラス $k$ の割合を $p_k^{(t)}$ とすると:
この式の意味を考えてみましょう。$\sum_{k=1}^K (p_k^{(t)})^2$ は、ランダムに選んだ2つのサンプルが同じクラスに属する確率です。したがって、ジニ不純度は「ランダムに選んだ2つのサンプルが異なるクラスに属する確率」を表しています。
具体例で理解する:
- 完全に純粋なノード(全て同じクラス):$p_1 = 1, p_2 = 0$ → $\text{Gini} = 1 - 1^2 = 0$
- 完全に混合したノード(2クラスが半々):$p_1 = 0.5, p_2 = 0.5$ → $\text{Gini} = 1 - (0.5^2 + 0.5^2) = 0.5$
ジニ不純度が小さいほど、ノードは純粋です。
エントロピー:情報理論的アプローチ
エントロピーは情報理論から来た概念で、「不確実性」や「驚き」を測る指標です:
エントロピーは、そのノードのクラスを正確に伝えるために必要な平均ビット数として解釈できます。
情報利得という考え方:
分割による情報利得は、親ノードのエントロピーから子ノードの加重平均エントロピーを引いたものです:
情報利得が大きいほど、その分割により多くの「情報」が得られた、つまり不確実性が大きく減少したことを意味します。
どの指標を選ぶべきか
実践的には、ジニ不純度とエントロピーの選択で結果が大きく変わることは稀です。両者の違いは:
ジニ不純度の特徴:
- 計算が高速(対数計算が不要)
- scikit-learnのデフォルト
- 不純度の減少を重視
エントロピーの特徴:
- 情報理論的な解釈が可能
- 情報利得という直感的な概念
- より「バランスの取れた」分割を作る傾向
多くの場合、計算効率の良いジニ不純度が使われます。
実装例
import numpy as np
def gini_impurity(y):
"""ジニ不純度の計算"""
_, counts = np.unique(y, return_counts=True)
probabilities = counts / len(y)
return 1 - np.sum(probabilities ** 2)
def entropy(y):
"""エントロピーの計算"""
_, counts = np.unique(y, return_counts=True)
probabilities = counts / len(y)
# 0 * log(0) = 0 と定義
probabilities = probabilities[probabilities > 0]
return -np.sum(probabilities * np.log2(probabilities))
def information_gain(parent, left_child, right_child):
"""情報利得の計算"""
n = len(parent)
n_l, n_r = len(left_child), len(right_child)
# 親ノードのエントロピー
parent_entropy = entropy(parent)
# 子ノードの加重平均エントロピー
child_entropy = (n_l / n * entropy(left_child) +
n_r / n * entropy(right_child))
return parent_entropy - child_entropy
回帰木(Regression Tree)
分割基準
回帰問題では、平方誤差を最小化:
ここで $\bar{y}_t$ はノード $t$ の平均値。
最適分割の探索
分割後の誤差減少を最大化:
決定木の実装
class DecisionNode:
"""決定木のノード"""
def __init__(self, feature=None, threshold=None, left=None, right=None, *, value=None):
self.feature = feature # 分割に使う特徴量のインデックス
self.threshold = threshold # 分割の閾値
self.left = left # 左の子ノード
self.right = right # 右の子ノード
self.value = value # 葉ノードの予測値
class DecisionTreeClassifier:
def __init__(self, max_depth=None, min_samples_split=2, criterion='gini'):
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.criterion = criterion
self.tree = None
def fit(self, X, y):
"""決定木の学習"""
self.n_classes = len(np.unique(y))
self.tree = self._grow_tree(X, y)
def _grow_tree(self, X, y, depth=0):
"""再帰的に木を構築"""
n_samples, n_features = X.shape
n_labels = len(np.unique(y))
# 停止条件
if (depth >= self.max_depth if self.max_depth else False) or \
n_labels == 1 or \
n_samples < self.min_samples_split:
leaf_value = self._most_common_label(y)
return DecisionNode(value=leaf_value)
# 最適な分割を探索
best_gain = -1
best_feature = None
best_threshold = None
for feature in range(n_features):
thresholds = np.unique(X[:, feature])
for threshold in thresholds:
# 分割
left_mask = X[:, feature] <= threshold
right_mask = ~left_mask
if np.sum(left_mask) == 0 or np.sum(right_mask) == 0:
continue
# 情報利得を計算
gain = self._information_gain(y, y[left_mask], y[right_mask])
if gain > best_gain:
best_gain = gain
best_feature = feature
best_threshold = threshold
# 子ノードを再帰的に構築
left_mask = X[:, best_feature] <= best_threshold
right_mask = ~left_mask
left_child = self._grow_tree(X[left_mask], y[left_mask], depth + 1)
right_child = self._grow_tree(X[right_mask], y[right_mask], depth + 1)
return DecisionNode(feature=best_feature, threshold=best_threshold,
left=left_child, right=right_child)
def _information_gain(self, parent, left, right):
"""情報利得の計算"""
if self.criterion == 'gini':
return self._gini_gain(parent, left, right)
else: # entropy
return self._entropy_gain(parent, left, right)
def _gini_gain(self, parent, left, right):
"""ジニ係数による情報利得"""
n = len(parent)
n_l, n_r = len(left), len(right)
parent_gini = gini_impurity(parent)
left_gini = gini_impurity(left)
right_gini = gini_impurity(right)
weighted_gini = (n_l / n) * left_gini + (n_r / n) * right_gini
return parent_gini - weighted_gini
def _most_common_label(self, y):
"""最頻値を返す"""
counter = np.bincount(y)
return np.argmax(counter)
def predict(self, X):
"""予測"""
return np.array([self._traverse_tree(x, self.tree) for x in X])
def _traverse_tree(self, x, node):
"""木を辿って予測値を返す"""
if node.value is not None:
return node.value
if x[node.feature] <= node.threshold:
return self._traverse_tree(x, node.left)
return self._traverse_tree(x, node.right)
5. 過学習と剪定:決定木の弱点への対処
決定木の根本的な問題
決定木の最大の弱点は、過学習への強い傾向です。制限なく成長させると、決定木は訓練データのすべての細かいパターンを覚えてしまい、各訓練サンプルを完全に分類できるまで分割を続けます。極端な場合、葉ノード一つにサンプル一つという状態になります。
この問題がなぜ深刻なのか、具体例で考えてみましょう。100人の顧客データで融資の可否を予測するモデルを作るとします。無制限に成長した決定木は、「35歳で年収523万円で郵便番号が123-4567の人は融資OK」といった、特定の個人にしか当てはまらないルールを作ってしまいます。このようなルールは新しいデータには全く役立ちません。
事前剪定:成長を制御する
事前剪定(pre-pruning)は、木の成長を適切なところで止める戦略です。以下のパラメータで制御します:
最大深さ(max_depth): 木の深さを制限します。深さ5の木は最大32個の葉ノードを持ちますが、深さ10なら1024個になります。深すぎる木は細かすぎる分類ルールを作ってしまいます。
最小サンプル数(min_samples_split / min_samples_leaf): 分割に必要な最小サンプル数を設定します。例えば min_samples_split=20 なら、20個未満のサンプルしかないノードは分割されません。これにより、少数のサンプルに基づく信頼性の低い分割を防げます。
最小不純度減少(min_impurity_decrease): 分割による不純度の減少がこの閾値を下回る場合、分割を行いません。わずかな改善のために複雑性を増すことを防ぎます。
事後剪定:最適な複雑さを見つける
事後剪定(post-pruning)は、一度完全に成長させた木から不要な枝を削除する戦略です。最も有名な手法がコスト複雑度剪定です。
コスト複雑度は次の式で定義されます:
ここで:
- $R(T)$ は訓練誤差(分類を間違えたサンプルの割合)
- $|T|$ は葉ノードの数(木の複雑さ)
- $\alpha$ は複雑度パラメータ(誤差と複雑さのトレードオフを制御)
$\alpha$ が小さいと複雑な木が選ばれ、大きいと単純な木が選ばれます。交差検証により最適な $\alpha$ を選ぶことで、汎化性能の高い木を得られます。
6. ランダムフォレスト:集団の知恵
関連教材(青の統計学)
単一の決定木の限界
決定木には、過学習以外にも重要な弱点があります。それは不安定性です。訓練データがわずかに変わるだけで、全く異なる木が生成されることがあります。最初の分割が変わると、その後のすべての分割が影響を受けるためです。
この問題に対する優雅な解決策が、「多数の木を作って集団で判断する」というアイデアです。一本の木の判断は不安定でも、多くの木の多数決は安定した予測を生み出します。これがランダムフォレストの基本思想です。
バギング:多様な木を作る
ランダムフォレストの第一の工夫はバギング(Bootstrap Aggregating)です。同じ訓練データから、少しずつ異なる多数のデータセットを作り出します。
ブートストラップサンプリング: $n$ 個の訓練データから、重複を許して $n$ 個のデータをランダムに選びます。例えば、[A, B, C, D, E] というデータから [A, A, C, E, E] のようなサンプルを作ります。
このプロセスを繰り返すことで、元のデータから多数の「似ているが少し違う」データセットを生成できます。各データセットで決定木を学習すれば、多様な視点を持つ木の集団が得られます。
興味深いことに、ブートストラップサンプリングでは、各サンプルで約37%のデータが一度も選ばれません($(1-1/n)^n \approx e^{-1} \approx 0.37$)。このOut-of-Bag(OOB)データは、交差検証なしで性能を評価するのに使えます。
特徴量のランダム選択:さらなる多様性
ランダムフォレストの第二の、そして決定的な工夫は、各分割で使う特徴量をランダムに制限することです。
通常の決定木では、各ノードですべての特徴量から最適な分割を選びます。しかし、強力な特徴量があると、多くの木でその特徴量が最初に選ばれ、似たような木ができてしまいます。
ランダムフォレストでは、各ノードの分割時に:
- $p$ 個の特徴量から $m$ 個をランダムに選択(分類では通常 $m = \sqrt{p}$)
- その $m$ 個の中だけから最適な分割を選択
これにより、異なる特徴量の組み合わせを使う多様な木が生成されます。一見すると性能が下がりそうですが、実際には個々の木の精度低下を、多様性による集団の強さが補って余りあります。
実装
from sklearn.ensemble import RandomForestClassifier
import numpy as np
class SimpleRandomForest:
def __init__(self, n_trees=100, max_depth=None, max_features='sqrt',
min_samples_split=2, bootstrap=True):
self.n_trees = n_trees
self.max_depth = max_depth
self.max_features = max_features
self.min_samples_split = min_samples_split
self.bootstrap = bootstrap
self.trees = []
def fit(self, X, y):
"""ランダムフォレストの学習"""
n_samples, n_features = X.shape
# max_featuresの設定
if self.max_features == 'sqrt':
self.max_features_ = int(np.sqrt(n_features))
elif self.max_features == 'log2':
self.max_features_ = int(np.log2(n_features))
else:
self.max_features_ = n_features
# 各木の学習
for _ in range(self.n_trees):
# ブートストラップサンプリング
if self.bootstrap:
indices = np.random.choice(n_samples, n_samples, replace=True)
X_sample, y_sample = X[indices], y[indices]
else:
X_sample, y_sample = X, y
# 決定木の学習(特徴量のサブセットを使用)
tree = DecisionTreeClassifier(
max_depth=self.max_depth,
min_samples_split=self.min_samples_split
)
# 特徴量のランダム選択
features = np.random.choice(n_features, self.max_features_, replace=False)
tree.fit(X_sample[:, features], y_sample)
self.trees.append((tree, features))
def predict(self, X):
"""予測(多数決)"""
predictions = []
for tree, features in self.trees:
pred = tree.predict(X[:, features])
predictions.append(pred)
predictions = np.array(predictions)
# 各サンプルで多数決
return np.array([np.bincount(predictions[:, i]).argmax()
for i in range(X.shape[0])])
def predict_proba(self, X):
"""確率予測"""
predictions = []
for tree, features in self.trees:
pred = tree.predict(X[:, features])
predictions.append(pred)
predictions = np.array(predictions)
n_samples = X.shape[0]
n_classes = len(np.unique(predictions))
probas = np.zeros((n_samples, n_classes))
for i in range(n_samples):
counts = np.bincount(predictions[:, i], minlength=n_classes)
probas[i] = counts / self.n_trees
return probas
特徴量重要度
不純度に基づく重要度
特徴量 $j$ の重要度:
ここで:
- $T_j$:特徴量 $j$ で分割されるノードの集合
- $w_t$:ノード $t$ のサンプル割合
- $\Delta(t)$:ノード $t$ での不純度減少
Permutation Importance
特徴量の値をランダムにシャッフルした時の精度低下を測定:
from sklearn.inspection import permutation_importance
def calculate_feature_importance(model, X, y, feature_names):
"""特徴量重要度の計算と可視化"""
# 不純度に基づく重要度
importances = model.feature_importances_
# Permutation importance
perm_importance = permutation_importance(
model, X, y, n_repeats=10, random_state=42
)
# データフレーム作成
importance_df = pd.DataFrame({
'feature': feature_names,
'gini_importance': importances,
'permutation_importance': perm_importance.importances_mean,
'perm_std': perm_importance.importances_std
}).sort_values('gini_importance', ascending=False)
# 可視化
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# ジニ係数ベース
axes[0].barh(importance_df['feature'][:10],
importance_df['gini_importance'][:10])
axes[0].set_xlabel('重要度')
axes[0].set_title('ジニ係数に基づく特徴量重要度')
# Permutation importance
axes[1].barh(importance_df['feature'][:10],
importance_df['permutation_importance'][:10])
axes[1].errorbar(importance_df['permutation_importance'][:10],
range(10),
xerr=importance_df['perm_std'][:10],
fmt='none', color='black', alpha=0.5)
axes[1].set_xlabel('重要度')
axes[1].set_title('Permutation Importance')
plt.tight_layout()
return importance_df
Out-of-Bag (OOB) 誤差
ブートストラップサンプリングで選ばれなかったデータ(約37%)を検証に使用:
class RandomForestWithOOB:
def __init__(self, n_trees=100):
self.n_trees = n_trees
self.trees = []
self.oob_score_ = None
def fit(self, X, y):
n_samples = X.shape[0]
n_classes = len(np.unique(y))
# OOB予測を格納
oob_predictions = np.zeros((n_samples, n_classes))
oob_counts = np.zeros(n_samples)
for _ in range(self.n_trees):
# ブートストラップサンプリング
indices = np.random.choice(n_samples, n_samples, replace=True)
oob_indices = np.setdiff1d(np.arange(n_samples), indices)
# 木の学習
tree = DecisionTreeClassifier()
tree.fit(X[indices], y[indices])
self.trees.append(tree)
# OOBサンプルで予測
if len(oob_indices) > 0:
oob_pred = tree.predict(X[oob_indices])
for idx, pred in zip(oob_indices, oob_pred):
oob_predictions[idx, pred] += 1
oob_counts[idx] += 1
# OOBスコアの計算
oob_pred_classes = np.argmax(oob_predictions, axis=1)
mask = oob_counts > 0
self.oob_score_ = np.mean(y[mask] == oob_pred_classes[mask])
return self
利点と欠点
決定木
利点:
- 解釈性が高い(可視化できる)
- 非線形関係を捉えられる
- カテゴリ変数をそのまま扱える
- 特徴量のスケーリング不要
欠点:
- 過学習しやすい
- 不安定(データの小さな変化で木構造が大きく変わる)
- 線形関係の表現が苦手
- 外挿ができない
ランダムフォレスト
利点:
- 高い予測精度
- 過学習に強い
- 特徴量重要度を計算できる
- 並列化が容易
欠点:
- 解釈性が低い
- メモリ使用量が多い
- 訓練・予測が遅い
- リアルタイム予測には不向き
実装例:顧客離脱予測
# データ準備
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
# 顧客データを模擬
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=10,
n_redundant=5,
n_classes=2,
weights=[0.7, 0.3], # 離脱率30%
random_state=42
)
# データ分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 決定木とランダムフォレストの比較
models = {
'Decision Tree': DecisionTreeClassifier(max_depth=5, random_state=42),
'Random Forest': RandomForestClassifier(
n_estimators=100, max_depth=5, random_state=42, oob_score=True
)
}
results = {}
for name, model in models.items():
# 学習
model.fit(X_train, y_train)
# 交差検証
cv_scores = cross_val_score(model, X_train, y_train, cv=5, scoring='roc_auc')
# テストスコア
test_score = model.score(X_test, y_test)
results[name] = {
'cv_mean': cv_scores.mean(),
'cv_std': cv_scores.std(),
'test_score': test_score
}
print(f"\n{name}:")
print(f" 交差検証AUC: {cv_scores.mean():.3f} ± {cv_scores.std():.3f}")
print(f" テスト精度: {test_score:.3f}")
if name == 'Random Forest' and hasattr(model, 'oob_score_'):
print(f" OOBスコア: {model.oob_score_:.3f}")
# 学習曲線の比較
from sklearn.model_selection import learning_curve
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
for idx, (name, model) in enumerate(models.items()):
train_sizes, train_scores, val_scores = learning_curve(
model, X_train, y_train, cv=5,
train_sizes=np.linspace(0.1, 1.0, 10),
scoring='accuracy'
)
axes[idx].plot(train_sizes, train_scores.mean(axis=1),
'o-', label='訓練スコア')
axes[idx].plot(train_sizes, val_scores.mean(axis=1),
's-', label='検証スコア')
axes[idx].fill_between(train_sizes,
train_scores.mean(axis=1) - train_scores.std(axis=1),
train_scores.mean(axis=1) + train_scores.std(axis=1),
alpha=0.2)
axes[idx].fill_between(train_sizes,
val_scores.mean(axis=1) - val_scores.std(axis=1),
val_scores.mean(axis=1) + val_scores.std(axis=1),
alpha=0.2)
axes[idx].set_xlabel('訓練データ数')
axes[idx].set_ylabel('精度')
axes[idx].set_title(f'{name} の学習曲線')
axes[idx].legend()
axes[idx].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
まとめ
決定木からランダムフォレストへの進化
この章では、人間の判断プロセスを模倣した決定木から始まり、その弱点を克服するランダムフォレストまでを学びました。
決定木は、その解釈性の高さから、結果の説明が重要な場面(医療診断、与信判断など)で今でも広く使われています。一方で、過学習しやすく不安定という弱点も明らかになりました。
ランダムフォレストは、「三人寄れば文殊の知恵」の原理を機械学習に適用した手法です。個々の木は完璧でなくても、多様な視点を持つ木々の集団判断は、単一の木よりもはるかに信頼できます。バギングと特徴量のランダム選択という二つの工夫により、精度と安定性の両立を実現しました。
実践での使い分け
決定木を選ぶべき場面:
- 予測の理由を説明する必要がある
- モデルの判断プロセスを人間が理解・検証したい
- データ量が少なく、シンプルなモデルが適している
- リアルタイム予測で速度が重要
ランダムフォレストを選ぶべき場面:
- 予測精度を最優先したい
- 特徴量が多く、どれが重要か分からない
- データに外れ値やノイズが含まれている
- 特徴量重要度を使って変数選択をしたい
今後の展望
決定木をベースにした手法は、さらに進化を続けています。勾配ブースティング(XGBoost、LightGBMなど)は、弱い木を順次追加していくことで、ランダムフォレストを超える精度を実現しています。また、解釈可能な機械学習への関心の高まりとともに、決定木の解釈性を活かした新しい手法も提案されています。
次章では、全く異なるアプローチである「k-NN法とベイズ分類器」について学習します。これらは、モデルを明示的に構築するのではなく、データそのものを使って予測を行う手法です。