線形回帰の数理
線形回帰は機械学習の最も基本的な手法の一つであり、多くの複雑なアルゴリズムの基礎となっています。本章では、線形回帰の数学的基盤から実装まで、詳細に学習していきます。
線形回帰の数学的定式化
関連教材(青の統計学)
[図1] 線形回帰の概要
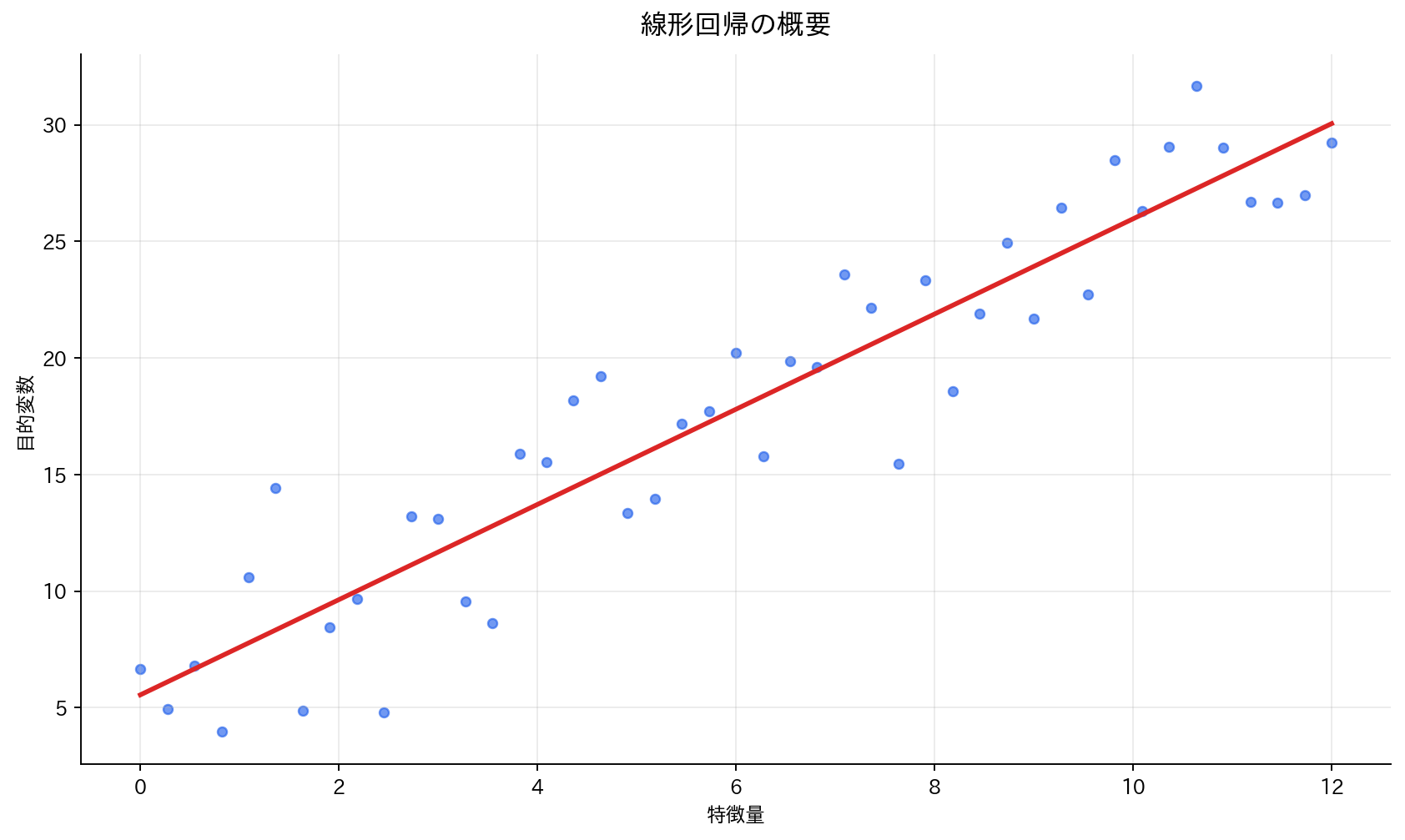
単回帰モデル
最もシンプルな線形回帰から始めましょう。
モデル:
ここで:
- $y$:目的変数(従属変数)
- $x$:説明変数(独立変数)
- $\beta_0$:切片(intercept)
- $\beta_1$:傾き(slope)
- $\varepsilon$:誤差項(ランダムノイズ)
仮定:
- 線形性:$x$ と $y$ の関係が線形
- 独立性:各観測が独立
- 等分散性:誤差の分散が一定
- 正規性:誤差が正規分布に従う:$\varepsilon \sim N(0, \sigma^2)$
重回帰モデル
複数の説明変数を持つ場合:
モデル:
ベクトル表記:
ここで:
- $\mathbf{y} \in \mathbb{R}^n$:目的変数ベクトル
- $\mathbf{X} \in \mathbb{R}^{n \times (p+1)}$:計画行列(design matrix)
- $\boldsymbol{\beta} \in \mathbb{R}^{p+1}$:回帰係数ベクトル
- $\boldsymbol{\varepsilon} \in \mathbb{R}^n$:誤差ベクトル
最小二乗法による推定
[図4] 最小二乗法による推定
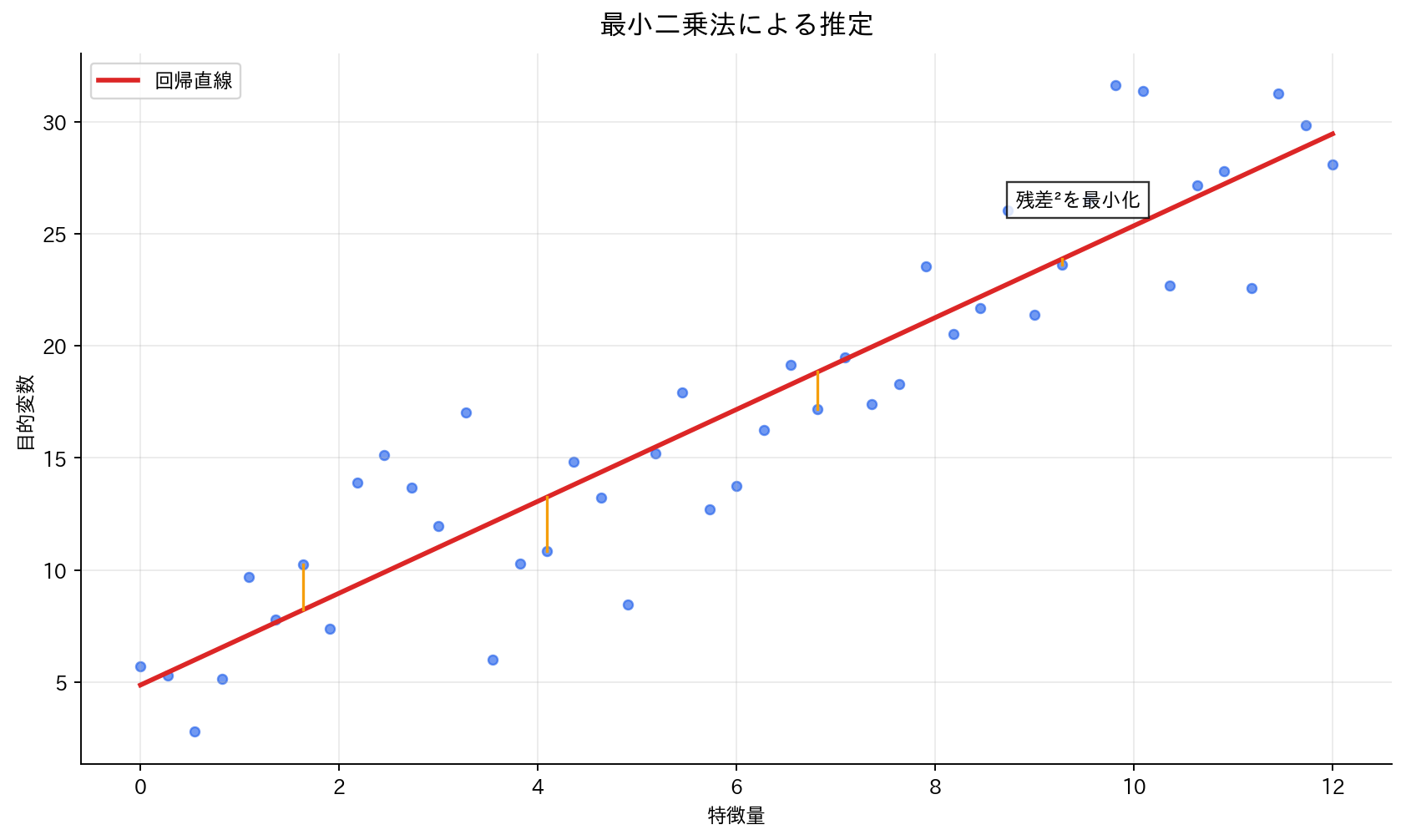
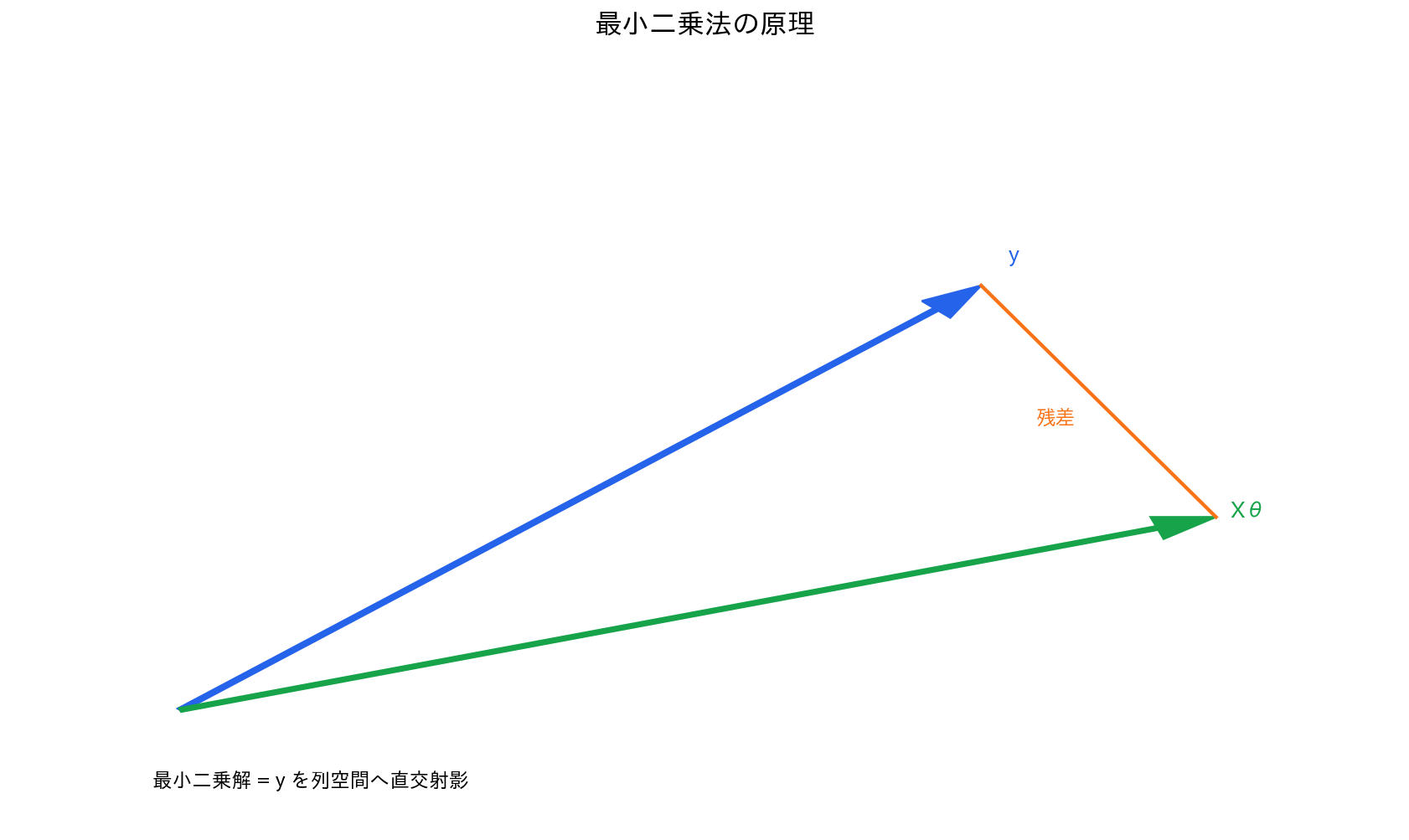
最小二乗法の原理
[図5] 最小二乗法の原理
目的関数(残差平方和):
ベクトル表記:
正規方程式の導出
目的関数を $\boldsymbol{\beta}$ で微分して0と置く:
正規方程式:
最小二乗推定量:
幾何学的解釈
最小二乗法は、$\mathbf{y}$ を $\mathbf{X}$ の列空間に正射影することと等価です。
予測値:
$\mathbf{H} = \mathbf{X}(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T$ は ハット行列(hat matrix)と呼ばれます。
実装例
scikit-learnによる実装
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# データ生成
np.random.seed(42)
X = np.random.randn(100, 3) # 3つの特徴量
true_beta = np.array([1.5, -2.0, 0.5])
y = X @ true_beta + np.random.randn(100) * 0.1
# 訓練・テスト分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデル学習
model = LinearRegression()
model.fit(X_train, y_train)
# 予測
y_pred = model.predict(X_test)
# 評価
print(f"R²スコア: {r2_score(y_test, y_pred):.3f}")
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, y_pred)):.3f}")
print(f"回帰係数: {model.coef_}")
print(f"切片: {model.intercept_:.3f}")
正規方程式による直接実装
class LinearRegressionOLS:
def __init__(self):
self.coef_ = None
self.intercept_ = None
def fit(self, X, y):
# バイアス項を追加
X_with_bias = np.column_stack([np.ones(X.shape[0]), X])
# 正規方程式で解く
XTX_inv = np.linalg.inv(X_with_bias.T @ X_with_bias)
beta = XTX_inv @ X_with_bias.T @ y
self.intercept_ = beta[0]
self.coef_ = beta[1:]
def predict(self, X):
return X @ self.coef_ + self.intercept_
# 使用例
model_ols = LinearRegressionOLS()
model_ols.fit(X_train, y_train)
y_pred_ols = model_ols.predict(X_test)
統計的性質
不偏性
$E[\hat{\boldsymbol{\beta}}] = \boldsymbol{\beta}$ (不偏推定量)
証明:
分散
ガウス・マルコフ定理
線形回帰の仮定の下で、最小二乗推定量は BLUE(Best Linear Unbiased Estimator:最良線形不偏推定量)です。
多重共線性の問題
関連教材(青の統計学)
多重共線性とは
説明変数間に強い線形関係がある状態:
問題:
- $\mathbf{X}^T\mathbf{X}$ の行列式が0に近くなる
- $(\mathbf{X}^T\mathbf{X})^{-1}$ が数値的に不安定
- 回帰係数の分散が大きくなる
検出方法
1. 相関行列
correlation_matrix = np.corrcoef(X.T)
print("相関行列:")
print(correlation_matrix)
2. 分散インフレーション因子(VIF)
ここで $R_j^2$ は、$j$ 番目の変数を他の変数で回帰した時の決定係数。
from statsmodels.stats.outliers_influence import variance_inflation_factor
def calculate_vif(X):
vif = pd.DataFrame()
vif["Feature"] = X.columns
vif["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
return vif
判定基準:
- VIF > 10:多重共線性あり
- VIF > 5:要注意
対処法
- 変数選択:相関の高い変数を除去
- 主成分分析:主成分を説明変数として使用
- 正則化:Ridge回帰、Lasso回帰
モデルの仮定の検証
残差分析
残差:
標準化残差:
ここで $h_{ii}$ はハット行列の対角成分(leverage)。
import matplotlib.pyplot as plt
def residual_analysis(y_true, y_pred, X):
residuals = y_true - y_pred
# 残差プロット
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 1. 残差 vs 予測値
axes[0, 0].scatter(y_pred, residuals, alpha=0.6)
axes[0, 0].axhline(y=0, color='red', linestyle='--')
axes[0, 0].set_xlabel('予測値')
axes[0, 0].set_ylabel('残差')
axes[0, 0].set_title('残差 vs 予測値')
# 2. Q-Qプロット(正規性の確認)
from scipy import stats
stats.probplot(residuals, dist="norm", plot=axes[0, 1])
axes[0, 1].set_title('Q-Qプロット')
# 3. 残差の分布
axes[1, 0].hist(residuals, bins=20, alpha=0.7)
axes[1, 0].set_xlabel('残差')
axes[1, 0].set_ylabel('頻度')
axes[1, 0].set_title('残差の分布')
# 4. leverage vs 残差
hat_matrix = X @ np.linalg.inv(X.T @ X) @ X.T
leverage = np.diag(hat_matrix)
axes[1, 1].scatter(leverage, residuals, alpha=0.6)
axes[1, 1].set_xlabel('Leverage')
axes[1, 1].set_ylabel('残差')
axes[1, 1].set_title('Leverage vs 残差')
plt.tight_layout()
plt.show()
線形回帰の限界と拡張
限界
- 線形性の仮定:非線形関係を捉えられない
- 外れ値に敏感:1つの外れ値で結果が大きく変わる
- 多重共線性:説明変数間の相関で推定が不安定
- 高次元問題:特徴量数がサンプル数より多いと破綻
拡張手法
1. 多項式回帰
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
2. 正則化回帰
- Ridge回帰(L2正則化)
- Lasso回帰(L1正則化)
- Elastic Net
3. ロバスト回帰
from sklearn.linear_model import HuberRegressor
robust_model = HuberRegressor()
実践的なガイドライン
データ前処理
- 欠損値処理
- 外れ値の確認・処理
- 特徴量のスケーリング(正則化する場合)
- 多重共線性のチェック
モデル評価
from sklearn.metrics import mean_absolute_error
def evaluate_regression(y_true, y_pred):
metrics = {
'MSE': mean_squared_error(y_true, y_pred),
'RMSE': np.sqrt(mean_squared_error(y_true, y_pred)),
'MAE': mean_absolute_error(y_true, y_pred),
'R²': r2_score(y_true, y_pred)
}
return metrics
まとめ
線形回帰は機械学習の基礎であり、その数学的理解は他のアルゴリズムの理解にも役立ちます。重要なポイント:
- 最小二乗法による係数の推定
- 正規方程式と勾配降下法の2つの解法
- 多重共線性の問題と対処法
- 残差分析による仮定の検証
- 正則化による拡張
次章では、分類問題の基本であるロジスティック回帰について学習します。